![]()
「ヒートプロット」や「ヒートタイル」とも呼ばれるヒートマップは、3 つの変数(x 軸、y 軸、色)を表示しようとする際に便利なデータ可視化の手法です。本章では、2 つの例を紹介します。
![]()
以下のコードを実行すると、解析に必要なパッケージが読み込まれます。このハンドブックでは、パッケージを読み込むために、pacman パッケージの p_load() を主に使用しています。p_load() は、必要に応じてパッケージをインストールし、現在の R セッションで使用するためにパッケージを読み込む関数です。また、すでにインストールされたパッケージは、R の基本パッケージである base の library() を使用して読み込むこともできます。R のパッケージについては、R の基礎 の章を参照してください。
pacman::p_load(
tidyverse, # データ操作と可視化
rio, # データのインポート
lubridate # 日付処理
)データセット
感染伝播マトリックスのセクションでは、流行をシュミレートした症例ラインリストを使用し、報告率の時系列のセクションでは、日別のマラリア患者数のデータセットを使用しています。これらのデータの読み込みとクリーニングは、それぞれのセクションで行います。
ヒートマップは、マトリックスを視覚化するのに便利です。マトリックス視覚化の一つの例として、アウトブレイクにおける「誰から誰に感染がうつったか」を図示することができます。これは、感染イベントに関するデータがあることが前提となっています。
なお、接触者の追跡 の章には、別の(より単純な)データセットを用いて、ヒートマップによる接触マトリックスを作成する例が掲載されています。また、ggplot の基礎 の章では、この単純なデータを使用した密度マップの作成について説明しています。本章で扱う例は、症例のラインリストから始まるので、プロット可能なデータフレームになる前にかなりのデータ操作が必要ですが、その結果として多くのシナリオから選ぶことが可能になっています。
まずは、エボラ出血熱の流行をシミュレーションした症例ラインリストを使います。こちら から「前処理済みの」ラインリスト(.rdsファイル)をダウンロードすることができ、rio パッケージの import() を使用してデータをインポートすることができます(.xlsx、.rds、.csv など多様なファイル形式のインポートに対応しています。詳しくは、データのインポート・エクスポート の章を参照してください)。
ラインリストの最初の 50 行を以下に表示します。
linelist <- import("linelist_cleaned.rds")このラインリストでは、
case_id が振られています。infector 列には、感染者の case_id が含まれており、その感染者も症例としてラインリストに含まれています。目的:感染者と接触者を年代別にグループ分けし、感染者と接触者の年代別のグループを組み合わせた感染ペアを行として、その各感染ペアが全体に占める割合を数字型の列とする縦型のデータフレームを作成する必要があります。
これを実現するには、いくつかのデータ操作を行う必要があります。
まず症例 ID、年代、感染源の ID を含むデータフレームを作成し、case_ages という変数名をつけます。最初の 50 行は以下のように表示されます。
case_ages <- linelist %>%
select(case_id, infector, age_cat) %>%
rename("case_age_cat" = "age_cat")次に、感染源のデータフレームを作成します。まず、感染源 ID のみの 1 列から構成されているデータフレームを作成し、欠損値を削除します(全ての症例の感染源が判明している訳ではない)。最初の 50 行は以下のように表示されます。
infectors <- linelist %>%
select(infector) %>%
drop_na(infector)次に、感染源の年代を取得します。ラインリストには、感染源の症例の年代が直接は記載されていないため、簡単には取得できず、ラインリストと感染源 ID を結合する必要があります。感染源のデータフレームから始めて、左側に「ベースライン」のデータフレームの infector 列(感染者 ID 列)を書き、右側にラインリストの case_id 列を書いて両者を紐づけ、ラインリストを感染源のデータフレームに left_join() (左結合)します。
結合すると、ラインリスト内の感染源の症例のデータ(年代)が、感染源の行に追加されました。最初の 50 行を以下に表示します。
infector_ages <- infectors %>% # 感染源のデータフレームから始める
left_join( # それぞれの感染源の行にラインリストデータを追加する
linelist,
by = c("infector" = "case_id")) %>% # infector列とcase id 列で紐付ける
select(infector, age_cat) %>% # 必要な列のみを抽出する
rename("infector_age_cat" = "age_cat") # 分かりやすいように列名を変更次に、感染先症例とその年代を、感染源症例とその年代に結合します。これらのデータフレームはそれぞれ infector という列を持っているので、この列で紐付けます。最初の行は以下のように表示されます。
ages_complete <- case_ages %>%
left_join(
infector_ages,
by = "infector") %>% # infector 列で紐付け
drop_na() # 欠損値のある行を削除Warning in left_join(., infector_ages, by = "infector"): Detected an unexpected many-to-many relationship between `x` and `y`.
ℹ Row 1 of `x` matches multiple rows in `y`.
ℹ Row 6 of `y` matches multiple rows in `x`.
ℹ If a many-to-many relationship is expected, set `relationship =
"many-to-many"` to silence this warning.以下は、感染先症例と感染源症例の年代階級別の症例数を単純にクロス集計したものです。分かりやすくするためにラベルをつけています。
table(cases = ages_complete$case_age_cat,
infectors = ages_complete$infector_age_cat) infectors
cases 0-4 5-9 10-14 15-19 20-29 30-49 50-69 70+
0-4 105 156 105 114 143 117 13 0
5-9 102 132 110 102 117 96 12 5
10-14 104 109 91 79 120 80 12 4
15-19 85 105 82 39 75 69 7 5
20-29 101 127 109 80 143 107 22 4
30-49 72 97 56 54 98 61 4 5
50-69 5 6 15 9 7 5 2 0
70+ 1 0 2 0 0 0 0 0この表をデータフレームに変換するには、base R の data.frame() を使います。これにより自動で縦型のデータフレームとなり、ggplot() に適した形となります。最初の行は以下のようになります。
long_counts <- data.frame(table(
cases = ages_complete$case_age_cat,
infectors = ages_complete$infector_age_cat))さらに、base R の prop.table() をテーブルに適用して、数の代わりに全体の割合を出します。最初の 50 行は以下のようになります。
long_prop <- data.frame(prop.table(table(
cases = ages_complete$case_age_cat,
infectors = ages_complete$infector_age_cat)))さて、いよいよ ggplot2 パッケージで geom_tile() 関数を用いてヒートマップを作成します。色・塗りつぶしのスケール、特に scale_fill_gradient() 関数についてより広範囲に学びたい方は、ggplot の基礎 の章を参照してください。
geom_tile() の aes() で、x に case age、y に infector age を指定します。
また、aes() では、引数 fill = を Freq 列に指定します。これはタイルの色に変換される値です。
scale_fill_gradient() でスケールカラーを設定します。高い値の色と、低い値の色を何色にするのかそれぞれ指定することができます。
scale_color_gradient() とは異なることに注意してください!今回は塗りつぶしが必要です。色は 「fill」を介して作られるので、 labs() の fill = 引数を使って、凡例のタイトルを変更することができます。
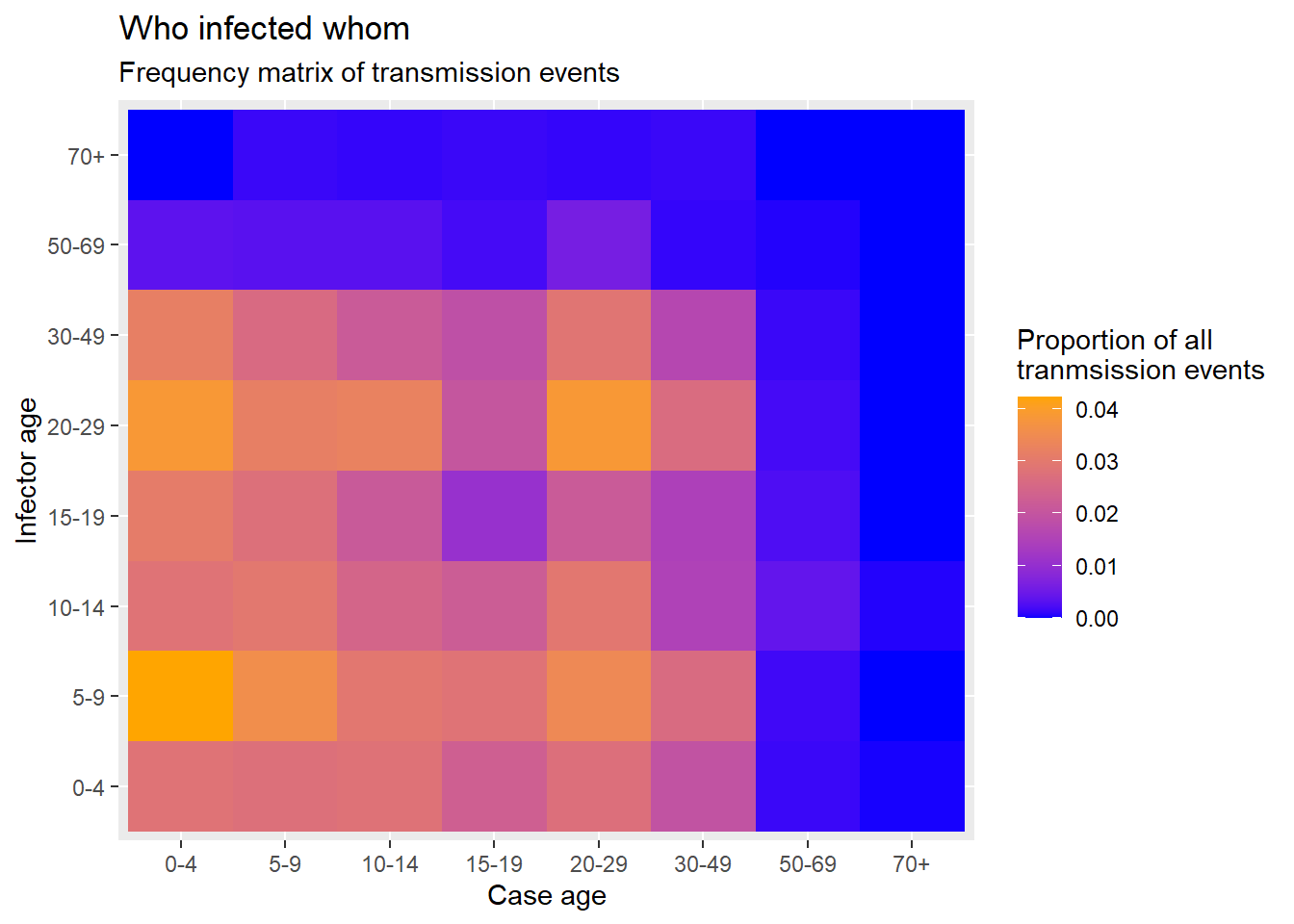
ggplot(data = long_prop)+ # 割合が Freq 列に格納された縦型データを使用
geom_tile( # タイルで可視化
aes(
x = cases, # x軸は感染先の年代
y = infectors, # y軸は感染源の年代
fill = Freq))+ # タイルの色分けを Freq 列で決定する
scale_fill_gradient( # タイルの色を調整する
low = "blue",
high = "orange")+
labs( # ラベル
x = "Case age",
y = "Infector age",
title = "Who infected whom",
subtitle = "Frequency matrix of transmission events",
fill = "Proportion of all\ntranmsission events" # 凡例タイトル
)
公衆衛生では、施設や管轄区域などにおける経時的な傾向を評価することが目的の一つであることがよくあります。このような経時的な傾向を可視化する方法の一つが、横軸を時間、縦軸を各施設としたヒートマップです。
まず、各施設におけるマラリアに関する日々の報告のデータセットをインポートします。データには、日付、州、地区、マラリアの症例数が含まれています。これらのデータをダウンロードする方法については、ハンドブックとデータのダウンロード の章を参照してください。以下は、データセットの最初の 30 行です。
facility_count_data <- import("malaria_facility_count_data.rds")このセクションの目的は、日別の施設ごとのマラリア患者数(前のタブで表示されています)を、週単位の施設ごとの報告率(この場合は、施設が何らかのデータを報告した日数の割合)に変換することです。以下の例では、Spring 地区のデータのみを表示します。
以下のステップを実行します。
データを適切にフィルタリング(場所、日付ごと)します。
lubridate パッケージの floor_date() を使って week 列を作成します。
データは「場所」と「週」の列でグループ化され、「施設 - 週」の分析単位が作成されます。
summarise() 関数を使って、「施設 - 週」グループごとの統計サマリーを反映する新しい列を作成します。
このデータフレームを right_join() (右結合)で、全ての「施設 - 週」の組み合わせを包括的なリストとして結合し、データセットを完成させます。全ての組み合わせの行列は、データフレーム(. で表されます)の 2 列に対して expand() 関数を適用することで作成されます。right_join() が使用されているので、expand() されたデータフレームのすべての行は保持され、必要であれば agg_weeks に追加されます。これらの新しい行は、NA(欠損値)の要約された値で表示されます。
以下に順を追って説明します。
# 週別の集計を作成する
agg_weeks <- facility_count_data %>%
# データのフィルタリング
filter(
District == "Spring",
data_date < as.Date("2020-08-01")) これでデータセットの行数が 3038 行から 608 行になりました。
次に、各行の週の開始日を示す week 列を作成します。これは、lubridate パッケージと floor_date() 関数を使って行います。この関数は「週」に設定され、週の始まりが月曜日(週の1日目、日曜日は 7 日目)になるように設定されています。
agg_weeks <- agg_weeks %>%
# data_date 列から week 列を作成
mutate(
week = lubridate::floor_date( # week 列を新たに作成
data_date, # 日付列
unit = "week", # 週の開始を指定
week_start = 1)) # 月曜スタートに指定 新しい week 列は、データフレームの一番右に表示されます。
ここで、データを「施設 - 週」にグループ分けし、「施設 - 週」ごとの統計データを作成するために集計を行います。詳細は、記述統計表の作り方 の章を参照してください。グループ化自体はデータフレームを変更しませんが、その後の要約統計の計算に影響します。
最初の 30 行を以下に示します。目的の要約統計量を反映するために、列が完全に変更されたことに注意してください。各行は、1 つの「施設 - 週」を反映しています。
agg_weeks <- agg_weeks %>%
# 「施設 - 週」でグループ化
group_by(location_name, week) %>%
# グループ化されたデータに対して要約統計量の列を作成
summarize(
n_days = 7, # 1週間の日数(7日)
n_reports = dplyr::n(), # 「施設 - 週」 からの報告回数(7件以上の可能性あり)
malaria_tot = sum(malaria_tot, na.rm = T), # 「施設 - 週」 で報告されたマラリア患者数の合計
n_days_reported = length(unique(data_date)), # データが報告された「施設 - 週」における日数
p_days_reported = round(100*(n_days_reported / n_days))) %>% # 「施設 - 週」 の7日間のうち、データが報告された日数の割合
ungroup(location_name, week) # 次の処理で expand() が動作するように ungroup() を実行最後に、以下のコマンドを実行して、報告のなかった週も含めて、可能性のある全ての「施設 - 週」の組み合わせがデータ中に存在することを確認します。
確認するために、 right_join() を使用して week 列と location_name の列の全ての組み合わせを含むようにデータセットを拡張します(データセットは「. 」で表されます)。詳細は、データの縦横変換 の章にある expand() 関数のドキュメントを参照してください。このコードを実行する前の段階ではデータセットには 107 行が含まれています。
# 可能な全ての施設-週の組み合わせを作成
expanded_weeks <- agg_weeks %>%
tidyr::expand(location_name, week) # 可能な施設-週の組み合わせすべてを含んだデータフレームを作成する全 180 行の expanded_weeks は以下のようなデータになっています。
以下のコードを実行する前の段階では、agg_weeks は 107 行でした。
# 拡張された施設週間リストと right-join して、データの欠損を補填
agg_weeks <- agg_weeks %>%
right_join(expanded_weeks) %>% # 可能な全ての施設-週の組み合わせが含まれるようにする
mutate(p_days_reported = replace_na(p_days_reported, 0)) # 欠損値を0に変換Joining with `by = join_by(location_name, week)`コードを実行した後、agg_weeks は 180 行に変わっています。
ggplot2 パッケージの geom_tile() を用いて ggplot グラフを作成します。
scale_x_date() が使用できます。location_name は全ての施設名を表示します。p_days_reported に対して行われ、その「施設 - 週」の報告率を示します。scale_fill_gradient() は数値の塗りつぶしに使用され、高い値の色(high)、低い値の色(low)、NA の色を指定します。scale_x_date() を使用し、2 週間ごとのラベルとその形式を指定します。基本的なヒートマップは、デフォルトの色やスケールなどを使用して、以下のように作成できます。上で説明したように、geom_tile() の aes() 内では、x 軸、y 軸、および fill = の列を指定する必要があります。fill は色として表示される数値です。
ggplot(data = agg_weeks)+
geom_tile(
aes(x = week,
y = location_name,
fill = p_days_reported))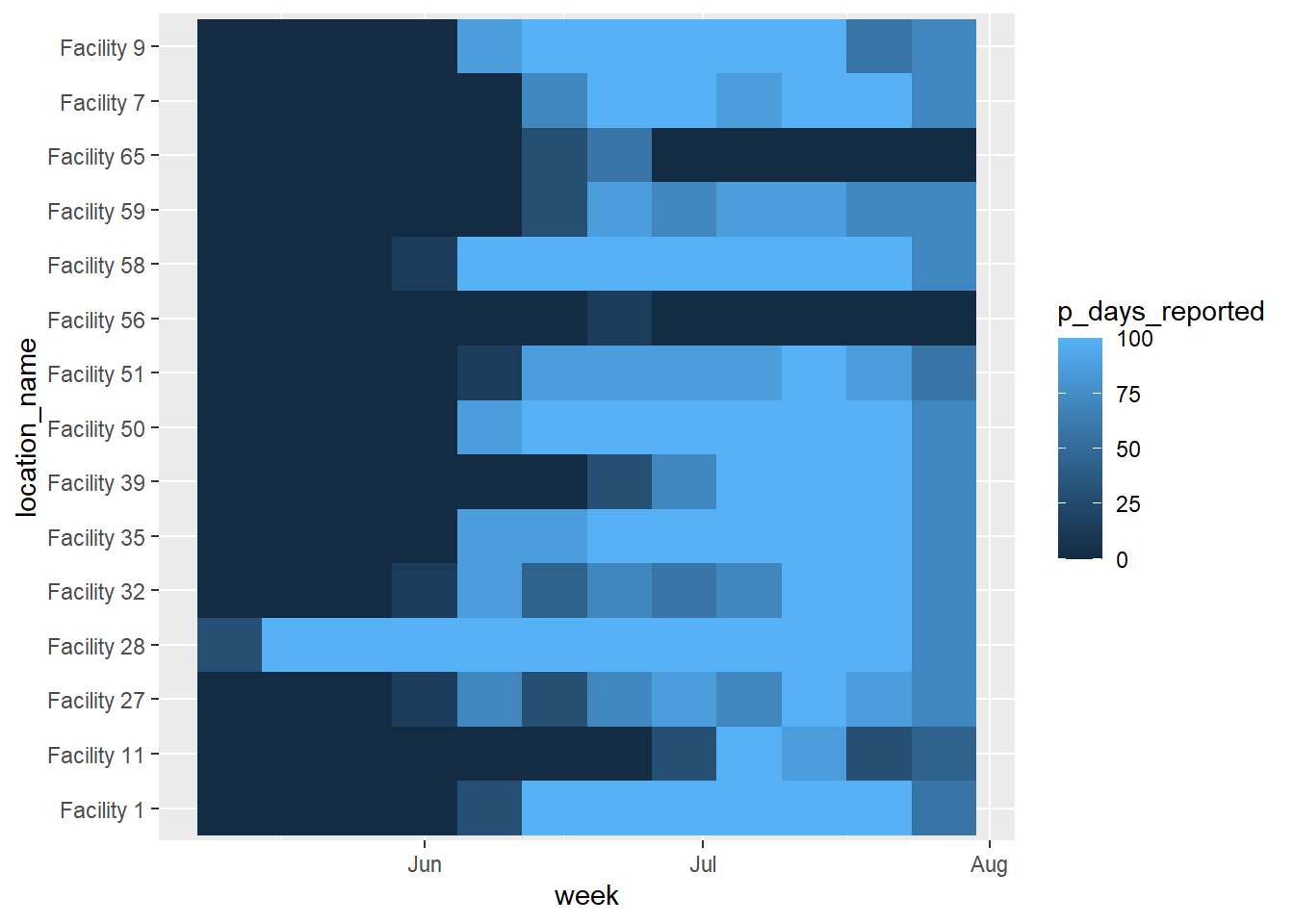
以下のように、ggplot2 の関数を追加することで、このプロットをより美しくできます。詳細は、ggplot の基礎 の章を参照して下さい。
ggplot(data = agg_weeks)+
# データをタイルで表示
geom_tile(
aes(x = week,
y = location_name,
fill = p_days_reported),
color = "white")+ # 罫線を白に指定
scale_fill_gradient(
low = "orange",
high = "darkgreen",
na.value = "grey80")+
# 日付軸
scale_x_date(
expand = c(0,0), # 両端の余分なスペースを削除
date_breaks = "2 weeks", # 2週間ごとの日付ラベルを指定
date_labels = "%d\n%b")+ # 月の上に日付を表示 (\n は改行を示す)
# テーマ
theme_minimal()+ # 背景を簡潔にする
theme(
legend.title = element_text(size=12, face="bold"),
legend.text = element_text(size=10, face="bold"),
legend.key.height = grid::unit(1,"cm"), # 凡例の高さの指定
legend.key.width = grid::unit(0.6,"cm"), # 凡例の幅の指定
axis.text.x = element_text(size=12), # 軸のテキストサイズの指定
axis.text.y = element_text(vjust=0.2), # 軸のテキストの場所の調整
axis.ticks = element_line(size=0.4),
axis.title = element_text(size=12, face="bold"), # 軸のタイトルのサイズの指定と太字フォントの指定
plot.title = element_text(hjust=0,size=14,face="bold"), # タイトルを右揃えにして、サイズを大きく、太字にする
plot.caption = element_text(hjust = 0, face = "italic") # 脚注を右揃えにしてイタリック体にする
)+
# 凡例
labs(x = "Week",
y = "Facility name",
fill = "Reporting\nperformance (%)", # 凡例のタイトルを指定
title = "Percent of days per week that facility reported data",
subtitle = "District health facilities, May-July 2020",
caption = "7-day weeks beginning on Mondays.")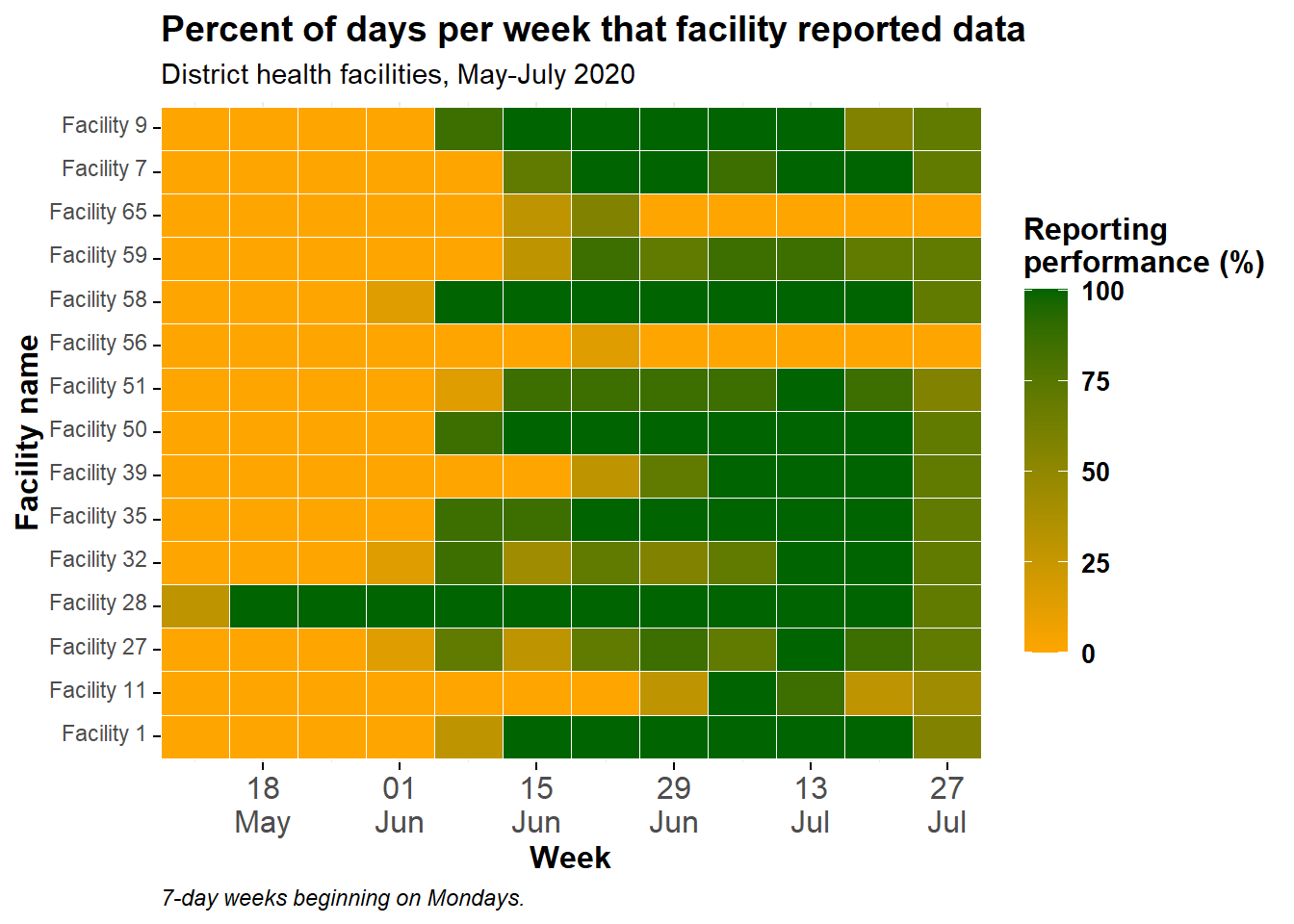
現在、各施設は下から上へ「アルファベット順」に並んでいます。y 軸の施設の順番を調整したい場合は、対象の列を因子型に変換して順番を指定してください。詳細は、因子(ファクタ)型データ の章を参照して下さい。
施設数が多く、全てを書き出すのは大変なので、別の方法として、データフレームに施設を並べ、その結果得られる名前の列を因子レベルの順序とすることを試みます。以下では、location_name 列を因子に変換し、そのレベルの順序を、全期間における施設ごとの報告日の合計数に基づいて設定します。
そのために、まず施設ごとの総報告数を昇順に並べたデータフレームを作成します。このベクトルを使って、プロットにおける因子レベルの順序を決めることができます。
facility_order <- agg_weeks %>%
group_by(location_name) %>%
summarize(tot_reports = sum(n_days_reported, na.rm=T)) %>%
arrange(tot_reports) # 昇順データフレームは以下のようになります。
ここで、上で扱ったデータフレームの列(facility_order$location_name)を使用して、データフレーム agg_weeks における location_name の因子レベルの順序を調整します。
# パッケージの読み込み
pacman::p_load(forcats)
# 因子を作成して、レベルを決める
agg_weeks <- agg_weeks %>%
mutate(location_name = fct_relevel(
location_name, facility_order$location_name)
)そして、次は location_name が順序付きの因子となるように、データを再プロットします。
ggplot(data = agg_weeks)+
# データをタイルで表示
geom_tile(
aes(x = week,
y = location_name,
fill = p_days_reported),
color = "white")+ # 罫線を白に指定
scale_fill_gradient(
low = "orange",
high = "darkgreen",
na.value = "grey80")+
# 日付軸
scale_x_date(
expand = c(0,0), # 両端の余分なスペースを削除
date_breaks = "2 weeks", # 2週間ごとの日付ラベルを指定
date_labels = "%d\n%b")+ # 月の上に日付を表示 (\n は改行を示す)
# テーマ
theme_minimal()+ # 背景を簡潔にする
theme(
legend.title = element_text(size=12, face="bold"),
legend.text = element_text(size=10, face="bold"),
legend.key.height = grid::unit(1,"cm"), # 凡例の高さの指定
legend.key.width = grid::unit(0.6,"cm"), # 凡例の幅の指定
axis.text.x = element_text(size=12), # 軸のテキストサイズの指定
axis.text.y = element_text(vjust=0.2), # 軸のテキストの場所の調整
axis.ticks = element_line(size=0.4),
axis.title = element_text(size=12, face="bold"), # 軸のタイトルのサイズの指定と太字フォントの指定
plot.title = element_text(hjust=0,size=14,face="bold"), # タイトルを右揃えにして、サイズを大きく、太字にする
plot.caption = element_text(hjust = 0, face = "italic") # 脚注を右揃えにしてイタリック体にする
)+
# 凡例
labs(x = "Week",
y = "Facility name",
fill = "Reporting\nperformance (%)", # 凡例のタイトルを指定
title = "Percent of days per week that facility reported data",
subtitle = "District health facilities, May-July 2020",
caption = "7-day weeks beginning on Mondays.")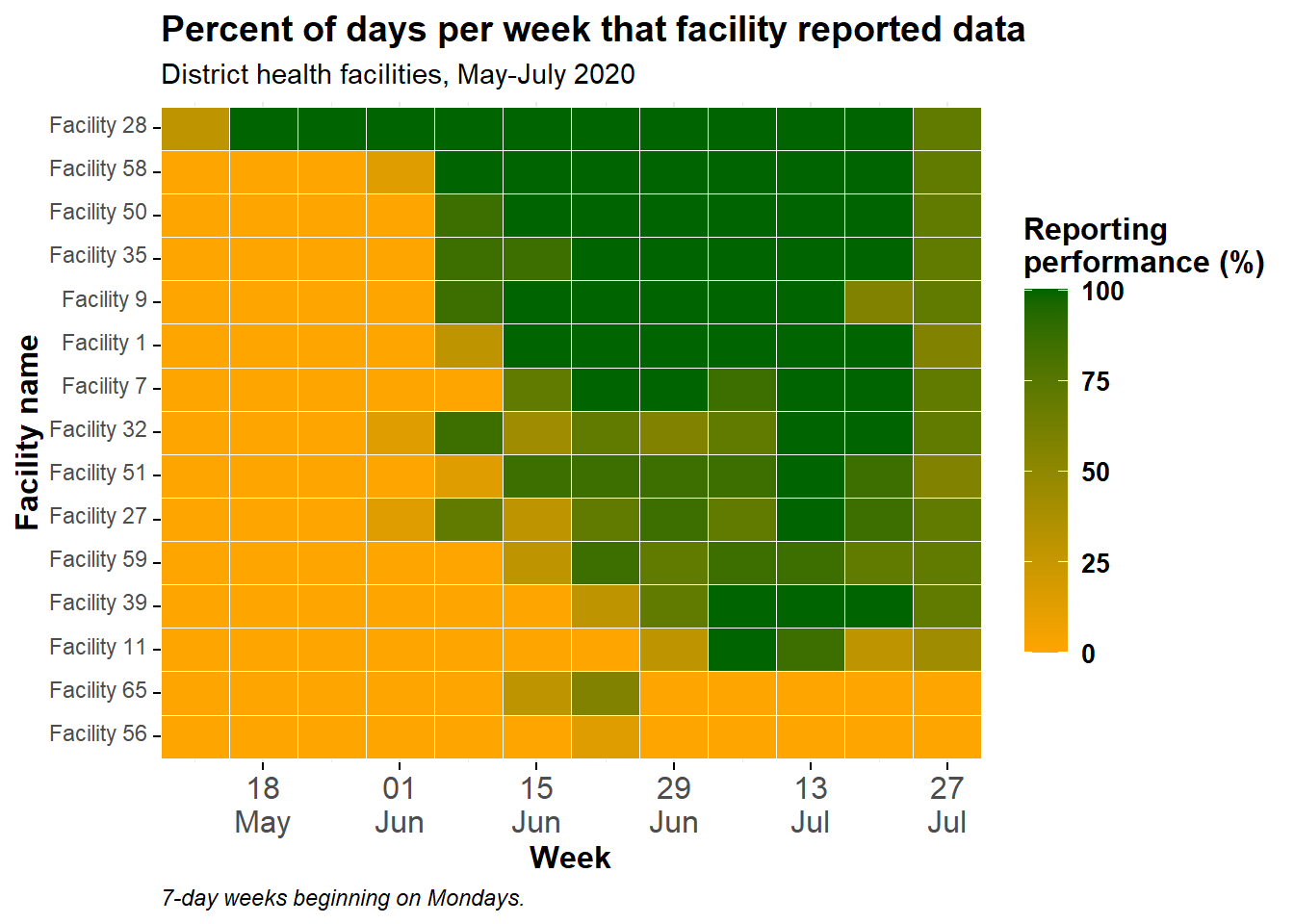
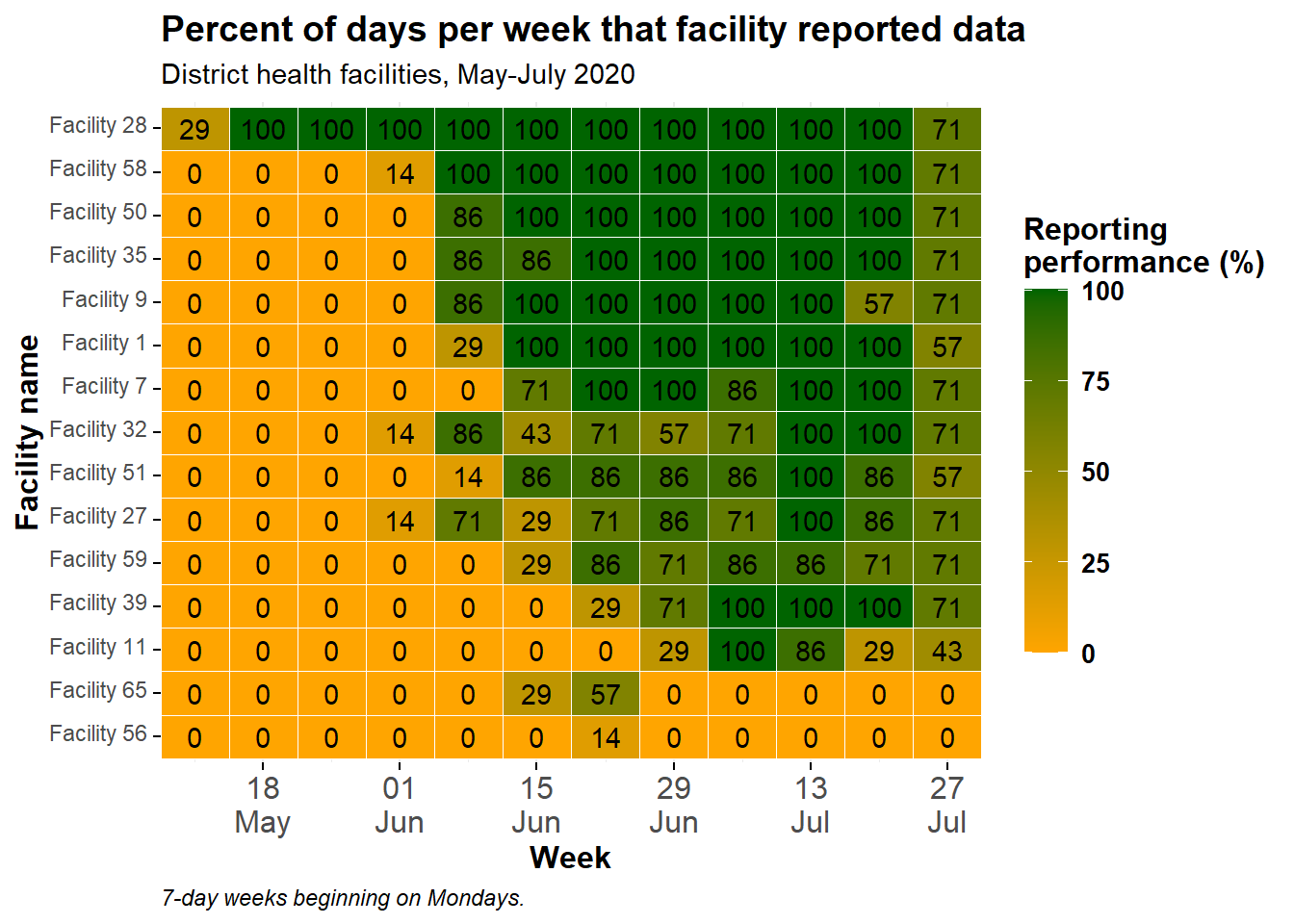
タイルの上に geom_text()レイヤーを追加して、各タイルの数値を表示することができます。小さなタイルがたくさんある場合、小さくてはっきり見えないかも知れないので注意して下さい!
次のコードを追加します: geom_text(aes(label = p_days_reported)) これは、各タイルにテキストで数値を追加するコードです。表示される数字は、引数 label = に割り当てられた値で、以下の例では色のグラデーションを作成するためにも使用されているのと同じ数値列 p_days_reported を指定しています。
ggplot(data = agg_weeks)+
# データをタイルで表示
geom_tile(
aes(x = week,
y = location_name,
fill = p_days_reported),
color = "white")+ # 罫線を白に指定
# テキスト
geom_text(
aes(
x = week,
y = location_name,
label = p_days_reported))+ # タイルの上に数値を表示
# タイルの塗りつぶし
scale_fill_gradient(
low = "orange",
high = "darkgreen",
na.value = "grey80")+
# 日付軸
scale_x_date(
expand = c(0,0), # 両端の余分なスペースを削除
date_breaks = "2 weeks", # 2週間ごとの日付ラベルを指定
date_labels = "%d\n%b")+ # 月の上に日付を表示 (\n は改行を示す)
# テーマ
theme_minimal()+ # 背景を簡潔にする
theme(
legend.title = element_text(size=12, face="bold"),
legend.text = element_text(size=10, face="bold"),
legend.key.height = grid::unit(1,"cm"), # 凡例の高さの指定
legend.key.width = grid::unit(0.6,"cm"), # 凡例の幅の指定
axis.text.x = element_text(size=12), # 軸のテキストサイズの指定
axis.text.y = element_text(vjust=0.2), # 軸のテキストの場所の調整
axis.ticks = element_line(size=0.4),
axis.title = element_text(size=12, face="bold"), # 軸のタイトルのサイズの指定と太字フォントの指定
plot.title = element_text(hjust=0,size=14,face="bold"), # タイトルを右揃えにして
plot.caption = element_text(hjust = 0, face = "italic") # 脚注を右揃えにしてイタリック体にする
)+
# 凡例
labs(x = "Week",
y = "Facility name",
fill = "Reporting\nperformance (%)", # 凡例のタイトルを指定
title = "Percent of days per week that facility reported data",
subtitle = "District health facilities, May-July 2020",
caption = "7-day weeks beginning on Mondays.")