pacman::p_load(
rio, # импорт файлов
here, # путь к файлу
skimr, # получение обзора данных
tidyverse, # управление данными + графики ggplot2,
gtsummary, # сводная статистика и тесты
rstatix, # статистика
corrr, # анализ корреляции числовых переменных
janitor, # добавление итого и процентов в таблицы
flextable # конвертация таблиц в HTML
)18 Простые статистические тесты
На этой странице мы демонстрируем, как проводить простые статистические тесты, используя базовый R, rstatix и gtsummary.
- T-тест
- Критерий Шапиро-Уилка
- Критерий ранговой суммы Уилкоксона
- Критерий Крускала-Уоллиса
- Критерий хи-квадрат
- Корреляции между числовыми переменными
…могут проводиться и многие другие тесты, но мы показываем только эти часто используемые тесты и даем ссылки на дополнительную документацию.
Каждый из указанных пакетов имеет свои преимущества и недостатки:
- Используйте функции базового R, чтобы напечатать статистические выходные данные в консоли R
- Используйте функции rstatix, чтобы выдать результаты в датафрейме, либо если вы хотите рассчитать тесты по группам
- Используйте gtsummary, если вы хотите быстро напечатать готовые к публикации таблицы
18.1 Подготовка
Загрузка пакетов
Данный фрагмент кода показывает загрузку пакетов, необходимых для анализа. В данном руководстве мы фокусируемся на использовании p_load() из пакета pacman, которая устанавливает пакет, если необходимо, и загружает его для использования. Вы можете также загрузить установленные пакеты с помощью library() из базового R. См. страницу Основы R для получения дополнительной информации о пакетах R.
Импорт данных
Мы импортируем набор данных о случаях из имитированной эпидемии Эболы. Если вы хотите выполнять действия параллельно, кликните, чтобы скачать “чистый” построчный список (как .rds файл). Импортируйте ваши данные с помощью функции import() из пакета rio (она работает со многими типами файлов, такими как .xlsx, .rds, .csv - см. детали на странице Импорт и экспорт).
# импорт построчного списка
linelist <- import("linelist_cleaned.rds")Первые 50 строк построчного списка отображены ниже.
18.2 базовый R
Вы можете использовать функции базового R для проведения статистических тестов. Команды относительно просты, а результаты будут напечатаны для просмотра в консоли R. Однако выходные данные, как правило, являются списками, поэтому с ними слложнее работать, если вы хотите использовать результаты в дальнейших операциях.
T-тесты
t-тест, также называемый “t-тест Стьюдента”, как правило, используется для определения того, есть ли значительная разница между средними значениями какой-либо числовой переменной между двумя группами. Здесь мы покажем синтаксис для выполнения этого теста в зависимости от того, находятся ли столбцы в том же датафрейме.
Синтаксис 1: Это синтаксис, если ваш числовой и категориальный столбец находятся в одном датафрейме. Укажите числовой столбец в левой части уровнения, а категориальный столбец - в правой части. Укажите набор данных в data =. Опционально, установите paired = TRUE и conf.level = (0.95 по умолчанию), а также alternative = (либо “two.sided”, “less”, либо “greater”). Для получения детальной информации введите ?t.test.
## сравниваем средний возраст по группе исходов с помощью t-теста
t.test(age_years ~ gender, data = linelist)
Welch Two Sample t-test
data: age_years by gender
t = -21.344, df = 4902.3, p-value < 2.2e-16
alternative hypothesis: true difference in means between group f and group m is not equal to 0
95 percent confidence interval:
-7.571920 -6.297975
sample estimates:
mean in group f mean in group m
12.60207 19.53701 Синтаксис 2: Вы можете сравнить два числовых вектора, используя этот альтернативный синтаксис. Например, если два столбца находятся в разных наборах данных.
t.test(df1$age_years, df2$age_years)Вы можете также использовать t-тест, чтобы определить, отличается ли среднее значение выборки значительным образом от какого-то конкретного значения. Здесь мы проведем одновыборочный t-тест с известным/построенным на основе гипотезы популяционным средним значением mu =:
t.test(linelist$age_years, mu = 45)Критерий Шапиро-Уилка
Критерий Шапиро-Уилка может использоваться для определения того, была ли взята выборка из популяции с нормальным распределением (это допущение для многих других тестов и анализа, например, для t-теста). Однако, его можно использовать только на выборке от 3 до 5000 наблюдений. Для более крупных выборок может быть полезным квантиль-квантиль график.
shapiro.test(linelist$age_years)Критерий ранговой суммы Уилкоксона
Критерий ранговой суммы Уилкоксона, также называемый U тест Манна-Уитни, часто используется, чтобы помочь определить, относятся ли две числовых выборки к тому же распределению, когда их популяции не являются нормально распределенными или имеют неравную дисперсию.
## сравниваем возрастное распределение по группе исходов с помощью теста Уилкоксона
wilcox.test(age_years ~ outcome, data = linelist)
Wilcoxon rank sum test with continuity correction
data: age_years by outcome
W = 2501868, p-value = 0.8308
alternative hypothesis: true location shift is not equal to 0Критерий Крускала-Уоллиса
Критерий Крускала-Уоллиса является расширением Критерия ранговой суммы Уилкоксона, который может использоватьсядля тестировния различий в распределении более, чем двух выборок. Когда используются только две выборки, результаты идентичны Критерию ранговой суммы Уилкоксона.
## сравниваем возрастное распределение по группе исходов с помощью Критерия Крускала-Уоллиса
kruskal.test(age_years ~ outcome, linelist)
Kruskal-Wallis rank sum test
data: age_years by outcome
Kruskal-Wallis chi-squared = 0.045675, df = 1, p-value = 0.8308Критерий хи-квадрат
Критерий хи-квадрат Пирсона используется при тестировании значительных отличий между категорияльными группами.
## сравниваем доли в каждой группе с помощью критерия хи-квадрат
chisq.test(linelist$gender, linelist$outcome)
Pearson's Chi-squared test with Yates' continuity correction
data: linelist$gender and linelist$outcome
X-squared = 0.0011841, df = 1, p-value = 0.972518.3 Пакет rstatix
Пакет rstatix предлагает способность выполнять статистические тесты и извлекать результаты в структуре, удобной для каналов. Результаты автоматически представляются в датафрейме, так что вы можете проводить с результатами последующие операции. Также легко группировать данные, которые передаются в функции, чтобы статистические показатели считались для каждой группы.
Сводная статистика
Функция get_summary_stats() является быстрым способом выдачи сводной статистики. Просто передайте ваш набор данных в эту функцию и задайте столбцы для анализа. Если не указаны столбцы, статистика считается для всех столбцов.
По умолчанию выдаетсыя полный диапазон сводной статистики: n, max (максимум), min (минимум), median (медиана), 25%ile (25 процентиль), 75%ile (75 процентиль), IQR (межквартильный диапазон), median absolute deviation (mad) (медианное абсолютное отклонение), mean (среднее), standard deviation (стандартное отклонение), standard error (стандартная ошибка), а также confidence interval of the mean (доверительный интервал от среднего).
linelist %>%
rstatix::get_summary_stats(age, temp)# A tibble: 2 × 13
variable n min max median q1 q3 iqr mad mean sd se
<fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 age 5802 0 84 13 6 23 17 11.9 16.1 12.6 0.166
2 temp 5739 35.2 40.8 38.8 38.2 39.2 1 0.741 38.6 0.977 0.013
# ℹ 1 more variable: ci <dbl>Вы можете указать подмножество сводной статистике, которое вам нужно, задав одно из следующих значений в type =: “full”, “common”, “robust”, “five_number”, “mean_sd”, “mean_se”, “mean_ci”, “median_iqr”, “median_mad”, “quantile”, “mean”, “median”, “min”, “max”.
Можно использовать также для группированных данных, так чтобы выдавалась строка для каждой группы-переменной:
linelist %>%
group_by(hospital) %>%
rstatix::get_summary_stats(age, temp, type = "common")# A tibble: 12 × 11
hospital variable n min max median iqr mean sd se ci
<chr> <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Central Hos… age 445 0 58 12 15 15.7 12.5 0.591 1.16
2 Central Hos… temp 450 35.2 40.4 38.8 1 38.5 0.964 0.045 0.089
3 Military Ho… age 884 0 72 14 18 16.1 12.4 0.417 0.818
4 Military Ho… temp 873 35.3 40.5 38.8 1 38.6 0.952 0.032 0.063
5 Missing age 1441 0 76 13 17 16.0 12.9 0.339 0.665
6 Missing temp 1431 35.8 40.6 38.9 1 38.6 0.97 0.026 0.05
7 Other age 873 0 69 13 17 16.0 12.5 0.422 0.828
8 Other temp 862 35.7 40.8 38.8 1.1 38.5 1.01 0.034 0.067
9 Port Hospit… age 1739 0 68 14 18 16.3 12.7 0.305 0.598
10 Port Hospit… temp 1713 35.5 40.6 38.8 1.1 38.6 0.981 0.024 0.046
11 St. Mark's … age 420 0 84 12 15 15.7 12.4 0.606 1.19
12 St. Mark's … temp 410 35.9 40.6 38.8 1.1 38.5 0.983 0.049 0.095Вы также можете использовать rstatix для проведения статистических тестов:
T-тест
Используйте синтаксис формулы, чтобы уточнить числовой и категориальный столбцы:
linelist %>%
t_test(age_years ~ gender)# A tibble: 1 × 10
.y. group1 group2 n1 n2 statistic df p p.adj p.adj.signif
* <chr> <chr> <chr> <int> <int> <dbl> <dbl> <dbl> <dbl> <chr>
1 age_… f m 2807 2803 -21.3 4902. 9.89e-97 9.89e-97 **** Или используйте ~ 1 и уточните mu = для одновыборочного t-теста. Это также можно сделать по группе.
linelist %>%
t_test(age_years ~ 1, mu = 30)# A tibble: 1 × 7
.y. group1 group2 n statistic df p
* <chr> <chr> <chr> <int> <dbl> <dbl> <dbl>
1 age_years 1 null model 5802 -84.2 5801 0Если применимо, статистические тесты можно выполнять по группе, как показано ниже:
linelist %>%
group_by(gender) %>%
t_test(age_years ~ 1, mu = 18)# A tibble: 3 × 8
gender .y. group1 group2 n statistic df p
* <chr> <chr> <chr> <chr> <int> <dbl> <dbl> <dbl>
1 f age_years 1 null model 2807 -29.8 2806 7.52e-170
2 m age_years 1 null model 2803 5.70 2802 1.34e- 8
3 <NA> age_years 1 null model 192 -3.80 191 1.96e- 4Критерий Шапиро-Уилка
Как указано выше, размер выборки должен быть от 3 до 5000.
linelist %>%
head(500) %>% # первые 500 строк построчного списка случаев, только в целях примера
shapiro_test(age_years)# A tibble: 1 × 3
variable statistic p
<chr> <dbl> <dbl>
1 age_years 0.917 6.67e-16Критерий ранговой суммы Уилкоксона
linelist %>%
wilcox_test(age_years ~ gender)# A tibble: 1 × 9
.y. group1 group2 n1 n2 statistic p p.adj p.adj.signif
* <chr> <chr> <chr> <int> <int> <dbl> <dbl> <dbl> <chr>
1 age_years f m 2807 2803 2829274 3.47e-74 3.47e-74 **** Критерий Крускала-Уоллиса
Также известен как U-тест Манна-Уитни.
linelist %>%
kruskal_test(age_years ~ outcome)# A tibble: 1 × 6
.y. n statistic df p method
* <chr> <int> <dbl> <int> <dbl> <chr>
1 age_years 5888 0.0457 1 0.831 Kruskal-WallisКритерий хи-квадрат
Функция критерия хи-квадрата принимает таблицу, поэтому сначала создадим кросс-табуляцию. Существует много способов создания кросс-табуляции (см. Описательные таблицы), но здесь мы используем tabyl() из janitor и удаляем самый левый столбец подписей значений до того, как передаем в chisq_test().
linelist %>%
tabyl(gender, outcome) %>%
select(-1) %>%
chisq_test()# A tibble: 1 × 6
n statistic p df method p.signif
* <dbl> <dbl> <dbl> <int> <chr> <chr>
1 5888 3.53 0.473 4 Chi-square test ns С помощью пакета rstatix можно выполнить еще много функций и провести статистические тесты с этими функциями. См. документацию по rstatix онлайн тут или введите ?rstatix.
18.4 пакет gtsummary
Используйте gtsummary, если вы хотите добавить результаты статистического теста в красивую таблицу, которая была создана с помощью. этого пакета (как описано в разделе gtsummary страницы Описательные таблицы).
Проведение статистических тестов сравнения с tbl_summary делается путем добавления функции add_p к таблице и уточнения, какой тест использовать. Возможно откорректировать p-значения для множественного тестирования, используя функцию add_q. Детали можно получить с помощью ?tbl_summary.
Критерий хи-квадрат
Сравнтие доли категориальной переменной в двух группах. Статистическим тестом по умолчанию для add_p() при применении к категориальной переменной является критерий хи-квадрат независимости с корректировкой непрерывности, но если ожидаемое количество вызовов ниже 5, то используется точный критерий Фишера.
linelist %>%
select(gender, outcome) %>% # сохраняем интересующие переменные
tbl_summary(by = outcome) %>% # создаем суммарную таблицу и уточняем переменную группирования
add_p() # уточняем, какой тест провести1323 observations missing `outcome` have been removed. To include these observations, use `forcats::fct_na_value_to_level()` on `outcome` column before passing to `tbl_summary()`.Characteristic |
Death, N = 2,582 1 |
Recover, N = 1,983 1 |
p-value 2 |
|---|---|---|---|
| gender | >0.9 | ||
| f | 1,227 (50%) | 953 (50%) | |
| m | 1,228 (50%) | 950 (50%) | |
| Unknown | 127 | 80 | |
|
1
n (%) |
|||
|
2
Pearson’s Chi-squared test |
|||
T-тесты
Сравниваем разницу средних значений непрерывной переменной в двух группах. Например, сравниваем средний возраст по исходам пациентов.
linelist %>%
select(age_years, outcome) %>% # сохраняем интересующие переменные
tbl_summary( # создаем суммарную таблицу
statistic = age_years ~ "{mean} ({sd})", # уточняем, какую статистику показать
by = outcome) %>% # уточняем переменную группирования
add_p(age_years ~ "t.test") # уточняем, какие тесты провести1323 observations missing `outcome` have been removed. To include these observations, use `forcats::fct_na_value_to_level()` on `outcome` column before passing to `tbl_summary()`.Characteristic |
Death, N = 2,582 1 |
Recover, N = 1,983 1 |
p-value 2 |
|---|---|---|---|
| age_years | 16 (12) | 16 (13) | 0.6 |
| Unknown | 32 | 28 | |
|
1
Mean (SD) |
|||
|
2
Welch Two Sample t-test |
|||
Критерий ранговой суммы Уилкоксона
Сравниваем распределение непрерывной переменной в двух группах. По умолчанию используется Критерий ранговой суммы Уилкоксона и медиана (IQR) при сравнении двух групп. Однако для не-нормально распределенных данных или при сравнении нескольких групп более подходящим будет Критерий Крускала-Уоллиса.
linelist %>%
select(age_years, outcome) %>% # сохраняем интересующие переменные
tbl_summary( # создаем суммарную таблицу
statistic = age_years ~ "{median} ({p25}, {p75})", # уточняем, какую статистику показать (по умолчанию, так что можно удалить)
by = outcome) %>% # уточняем переменную группирования
add_p(age_years ~ "wilcox.test") # уточняем, какой тест провести (по умолчанию, так что можно оставить скобки пустыми)1323 observations missing `outcome` have been removed. To include these observations, use `forcats::fct_na_value_to_level()` on `outcome` column before passing to `tbl_summary()`.Characteristic |
Death, N = 2,582 1 |
Recover, N = 1,983 1 |
p-value 2 |
|---|---|---|---|
| age_years | 13 (6, 23) | 13 (6, 23) | 0.8 |
| Unknown | 32 | 28 | |
|
1
Median (IQR) |
|||
|
2
Wilcoxon rank sum test |
|||
Критерий Крускала-Уоллиса
Сравниваем распределение непрерывной переменной в двух или более группах, вне зависимости от того, имеют ли данные нормальное распределение.
linelist %>%
select(age_years, outcome) %>% # сохраняем интересующие переменные
tbl_summary( # создаем суммарную таблицу
statistic = age_years ~ "{median} ({p25}, {p75})", # уточняем, какую статистику показать (по умолчанию, так что можно удалить)
by = outcome) %>% # уточняем переменную группирования
add_p(age_years ~ "kruskal.test") # уточняем, какой тест провести1323 observations missing `outcome` have been removed. To include these observations, use `forcats::fct_na_value_to_level()` on `outcome` column before passing to `tbl_summary()`.Characteristic |
Death, N = 2,582 1 |
Recover, N = 1,983 1 |
p-value 2 |
|---|---|---|---|
| age_years | 13 (6, 23) | 13 (6, 23) | 0.8 |
| Unknown | 32 | 28 | |
|
1
Median (IQR) |
|||
|
2
Kruskal-Wallis rank sum test |
|||
18.5 Корреляции
Корреляцию между числовыми переменными можно изучить с помощью пакета tidyverse
corrr. Он позволяет вам рассчитать корреляции, используя коэффициент Пирсона, тау Кендалла или коэффициент корреляции Спирмена. Пакет создает таблицу, а также имеет функцию по автоматическому построению графика значений.
correlation_tab <- linelist %>%
select(generation, age, ct_blood, days_onset_hosp, wt_kg, ht_cm) %>% # сохраняем интересующие числовые переменные
correlate() # создаем таблицу корреляции (используя по умолчанию коэффициент Пирсона)
correlation_tab # печать# A tibble: 6 × 7
term generation age ct_blood days_onset_hosp wt_kg ht_cm
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 generation NA -2.22e-2 0.179 -0.288 -0.0302 -0.00942
2 age -0.0222 NA 0.00849 -0.000635 0.833 0.877
3 ct_blood 0.179 8.49e-3 NA -0.600 -0.00636 0.0181
4 days_onset_hosp -0.288 -6.35e-4 -0.600 NA 0.0153 -0.00953
5 wt_kg -0.0302 8.33e-1 -0.00636 0.0153 NA 0.884
6 ht_cm -0.00942 8.77e-1 0.0181 -0.00953 0.884 NA ## удаляем дублирующиеся записи (зеркало таблицы выше)
correlation_tab <- correlation_tab %>%
shave()
## просмотр таблицы корреляции
correlation_tab# A tibble: 6 × 7
term generation age ct_blood days_onset_hosp wt_kg ht_cm
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 generation NA NA NA NA NA NA
2 age -0.0222 NA NA NA NA NA
3 ct_blood 0.179 0.00849 NA NA NA NA
4 days_onset_hosp -0.288 -0.000635 -0.600 NA NA NA
5 wt_kg -0.0302 0.833 -0.00636 0.0153 NA NA
6 ht_cm -0.00942 0.877 0.0181 -0.00953 0.884 NA## график корреляций
rplot(correlation_tab)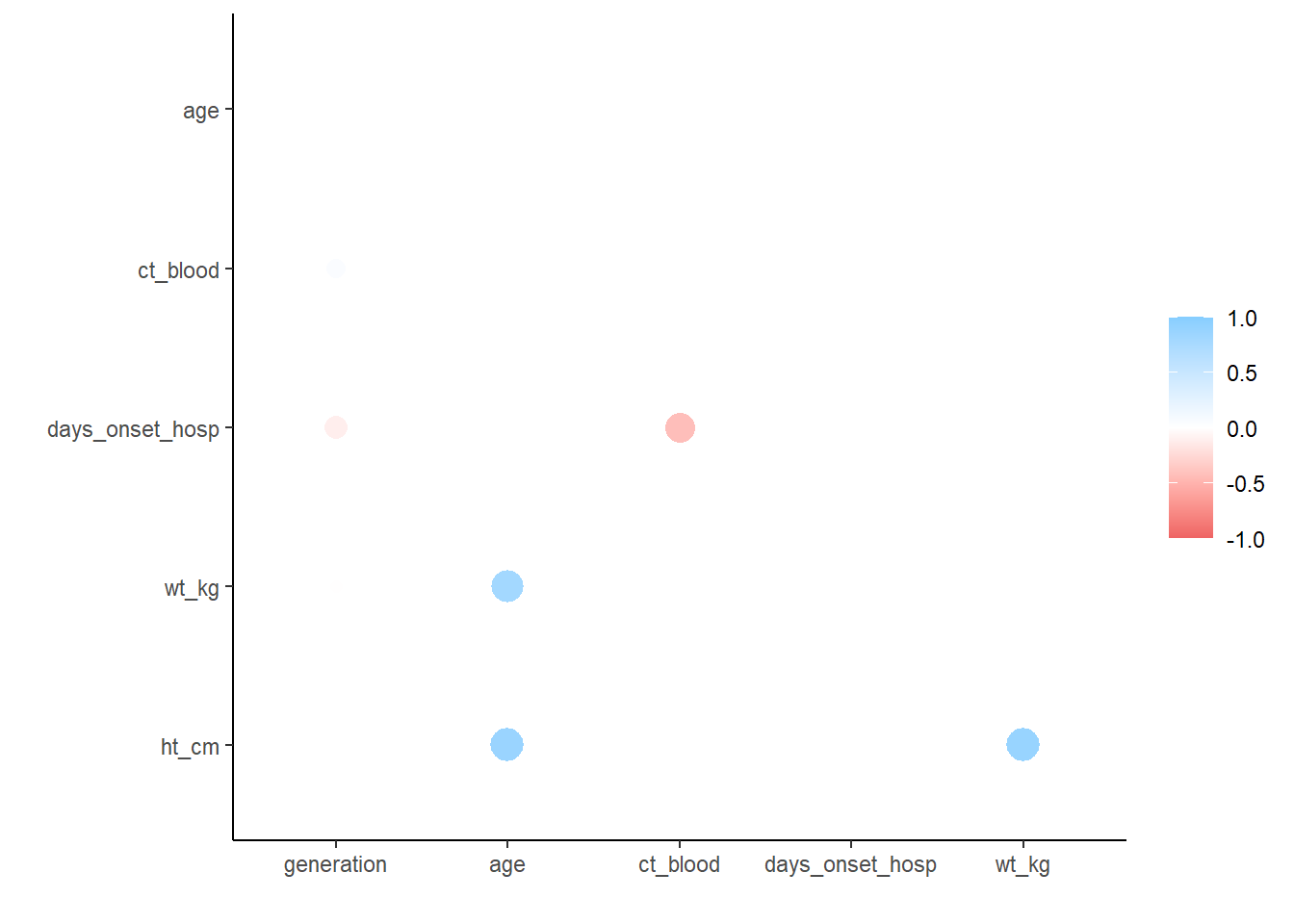
18.6 Ресурсы
Многая информация на этой странице была взята из следующих онлайн ресурсов и виньеток: