
3 Основы R
Добро пожаловать!
На данной странице рассматриваются основы работы с R. Она не является подробной инструкцией, но расскажет вам об основах и может быть полезна в качестве напоминания. В разделе Ресурсы для обучения даны ссылки на более подробные учебные пособия.
Части этой страницы были адаптированы с разрешения R4Epis project.
См. страницу Переход к R для поиска советов о том, как перейти к использованию R со STATA, SAS или Excel.
3.1 Зачем использовать R?
Как указано на нашем веб-сайте проекта по R, R - язык программирования и среда для статистических расчетов и графики. Он очень разнообразный, гибкий и развивается усилиями сообщества.
Стоимость
R можно использовать бесплатно! Сообщество придерживается принципов бесплатных и открытых материалов.
Воспроизводимость
Управление вашими данными и проведение анализа с использованием языка программирования (а не Excel или другого готового/ручного инструмента) повышает воспроизводимость, облегчает обнаружение ошибок, а также уменьшает объем работы.
Сообщество
У R очень большое и активно сотрудничающее сообщество пользователей. Новые пакеты и инструменты для решения реальных проблем разрабатываются практически ежедневно, а сообщество пользователей их проверяет. Например, R-Ladies - международная организация, чьей миссией является продвижение гендерного разнообразия в сообществе пользователей R, также является одной из крупнейших организацией пользователей R. У нее наверняка есть отделение недалеко от вас!
3.2 Ключевые понятия
RStudio - RStudio - это графический интерфейс пользователя (ГИП), облегчающий использование R. Дополнительную информацию можно найти в разделе RStudio.
Объекты - Все, что вы сохраняете в R - наборы данных, переменные, список названий населенных пунктов, количество населения, а также выходные данные, такие как графики - это все объекты, которым присваивается имя и на которые можно ссылаться в последующих командах. Дополнительную информацию можно найти в разделе Объекты.
Функции - Функция - это закодированная операция, которая принимает входные данные и выдает преобразованный результат. Дополнительную информацию можно найти в разделе Функции.
Пакеты - Пакет R - набор функций, которыми можно поделиться. Дополнительную информацию можно найти в разделе Пакеты.
Скрипты - Скрипт - документ, который содержит ваши команды. Дополнительную информацию можно найти в разделе Скрипты
3.3 Ресурсы для обучения
Ресурсы внутри RStudio
Справочная документация
Поищите документацию по пакетам и конкретным функциям R во вкладке “Help” (справка) в RStudio. Она находится в панели, где содержатся Файлы, Графики и Пакеты (как правило, нижняя правая панель). Альтернативно, вы можете также поставить вопросительный знак и после него напечатать название пакета или функции в консоли R, чтобы открыть соответствующую страницу Справки. Не включайте скобки.
Например: ?filter или ?diagrammeR.
Интерактивное обучение
Есть несколько способов интерактивного изучения R внутри RStudio.
Сама RStudio предлагает панель Tutorial (обучение), которая основана на learnr R package. Просто установите этот пакет и откройте самоучитель через новую вкладку “Tutorial” (обучение) в верхней правой панели RStudio (в которой также находятся вкладки Environment (рабочая среда) и History (история)).
Пакет R swirl предлагает интерактивное обучение в Консоли R. Установите и загрузите этот пакет, затем выполните команду swirl() (с пустыми скобками) в консоли R. В Консоли появятся подсказки. Печатайте ответ в Консоли. Пакет поможет вам пройти интересующий курс.
Шпаргалки
Существует много PDF “шпаргалок” на сайте RStudio, например:
- Коэффициенты в пакете forcats
- Даты и время в пакете lubridate
- Последовательности в пакете stringr
- Повторяющиеся операции в пакете purrr
- Импорт данных
- Шпаргалка по преобразованию данных с помощью пакета dplyr
- R Markdown (чтобы создавать документы в формате PDF, Word, Powerpoint…)
- Shiny (чтобы создавать интерактивные веб-приложения)
- Визуализация данных в пакете ggplot2
- Картография (GIS)
- Пакет leaflet (интерактивные карты)
- Python с помощью R (пакет reticulate)
Есть онлайн ресурс по R специально для пользователей Excel
У R есть активное твиттер-сообщество, в котором вы можете найти полезные советы, подсказки, а также новости - подпишитесь на следующие аккаунты:
- Подпишитесь на нас! @epiRhandbook
- R Функция Дня @rfuntionaday - замечательный ресурс
- R для Науки о данных @rstats4ds
- RStudio @RStudio
- RStudio Советы @rstudiotips
- R-Bloggers @Rbloggers
- R-ladies @RLadiesGlobal
- Hadley Wickham @hadleywickham
Также:
#epitwitter и #rstats
Бесплатные онлайн ресурсы
Авторитетный источник по R для Аналитики Данных - книга Гарретта Гролемунда и Хэдли Викхэма
Веб-сайт проекта R4Epis направлен на “разработку стандартизированных инструментов вычистки, анализа данных и ответности, которые бы охватывали основные типы исследований по вспышкам и популяционных исследований, которые могут проводиться в условиях экстренного реагирования Врачей Без Границ.” Там вы можете найти материалы для обучения основам R, шаблоны для отчетов RMarkdown по вспышкам и исследованиям, а также самоучители, которые помогут вам их настроить.
Языки кроме английского
3.4 Установка
R и RStudio
Как установить R
Зайдите на этот вебсайт https://www.r-project.org/ и скачайте последнюю версию R, подходящую для вашего компьютера.
Как установить RStudio
Зайдите на этот вебсайт https://rstudio.com/products/rstudio/download/ и скачайте последнюю версию десктоп приложения RStudio, подходящую для вашего компьютера.
Разрешения
Обратите внимание, что устанавливать R и RStudio нужно на диск, для которого у вас есть разрешения для чтения и внесения изменений. Иначе у вас будут проблемы с установкой пакетов R (это часто случается). Если вы столкнетесь с проблемой, попробуйте открыть RStudio правым кликом мышки и выберите вариант “Запуск от имени администратора”. Дополнительные соеветы можно найти на странице R на сетевых дисках.
Как обновлять R и RStudio
Номер версии R написан на Консоли при запуске. Вы можете это также проверить через sessionInfo().
Чтобы обновить R, зайдите на указанный выше веб-сайт и переустановите R. Альтернативно, вы можете использовать пакет installr (на Windows), выполнив команду installr::updateR(). Она откроет диалоговые окна, с помощью которых вы можете скачать последнюю версию R и обновить свои пакеты до самой новой версии R. Дополнительную информацию можно найти в installr документации.
Имейте ввиду, что старая версия R все еще будет существовать на вашем компьютере. Вы можете временно запустить более старую версию (установленную ранее) R, нажав на “Tools” -> “Global Options” в RStudio и выбрав версию R. Это может быть полезным, если вам нужно использовать пакет, который не был обновлен для работы в последней версии R.
Чтобы обновить RStudio, вы можете зайти на указанный выше сайт и повторно скачать RStudio. Еще один вариант - кликнуть на “Help” -> “Check for Updates” (справка-проверить обновления) в RStudio, но там не всегда будут отображаться самые последние обновления.
Чтобы увидеть, какие версии R, RStudio, либо пакетов использовались на момент создания данного Руководства, см. страницу Редакторские и технические заметки.
Другие программы, которые вам может понадобиться установить
- TinyTeX (для преобразования документа RMarkdown в PDF)
- Pandoc (для формирования документов RMarkdown)
- RTools (для создания пакетов для R)
- phantomjs (для сохранения статичных изображений из анимированных сетей, например, цепочек передачи инфекции)
TinyTex
TinyTex - кастомизированный дистрибутив LaTeX, полезен при создании PDF из R.
Дополнительную информацию можно найти по адресу https://yihui.org/tinytex/.
Чтобы установить TinyTex из R:
install.packages('tinytex')
tinytex::install_tinytex()
# чтобы удалить TinyTeX, выполните tinytex::uninstall_tinytex()Pandoc
Pandoc - конвертер документов, отдельная от R программа. Она идет в комплекте с RStudio и обычно не требует отдельного скачивания. Она помогает в процессе конвертации документов в такие форматы как .pdf и добавлении сложного функционала.
RTools
RTools - коллекция программного обеспечения для создания пакетов для R
Установите с веб-сайта: https://cran.r-project.org/bin/windows/Rtools/
phantomjs
Часто используется для создания “снимков экрана” веб-страниц. Например, когда вы создаете цепочки передачи инфекции с помощью пакета epicontacts, создается HTML файл, который является интерактивным и динамичным. Если вам нужно статичное изображение, полезно будет использовать пакет webshot для автоматизации этого процесса. Это также потребует внешней программы “phantomjs”. Вы можете установить phantomjs с помощью пакета webshot, использовав команду webshot::install_phantomjs().
3.5 RStudio
Ориентация в RStudio
Во-первых, откройте RStudio. Поскольку иконки выглядят похоже, убедитесь, что вы открыли именно RStudio, а не R.
Для работы RStudio у вас на компьютере должен быть установлен R (см. инструкции по установке выше).
RStudio - это интерфейс (ГИП) для облегчения использования R. Можете представить себе R как двигатель автомобиля, который выполняет основную работу, а RStudio как кузов автомобиля (с сидениями, аксессуарами и т.п.), который помогает использовать двигатель для движения! Вы можете полную шпаргалку по пользовательскому интерфейсу RStudio (PDF) здесь
По умолчанию RStudio отображает четыре прямоугольные панели.
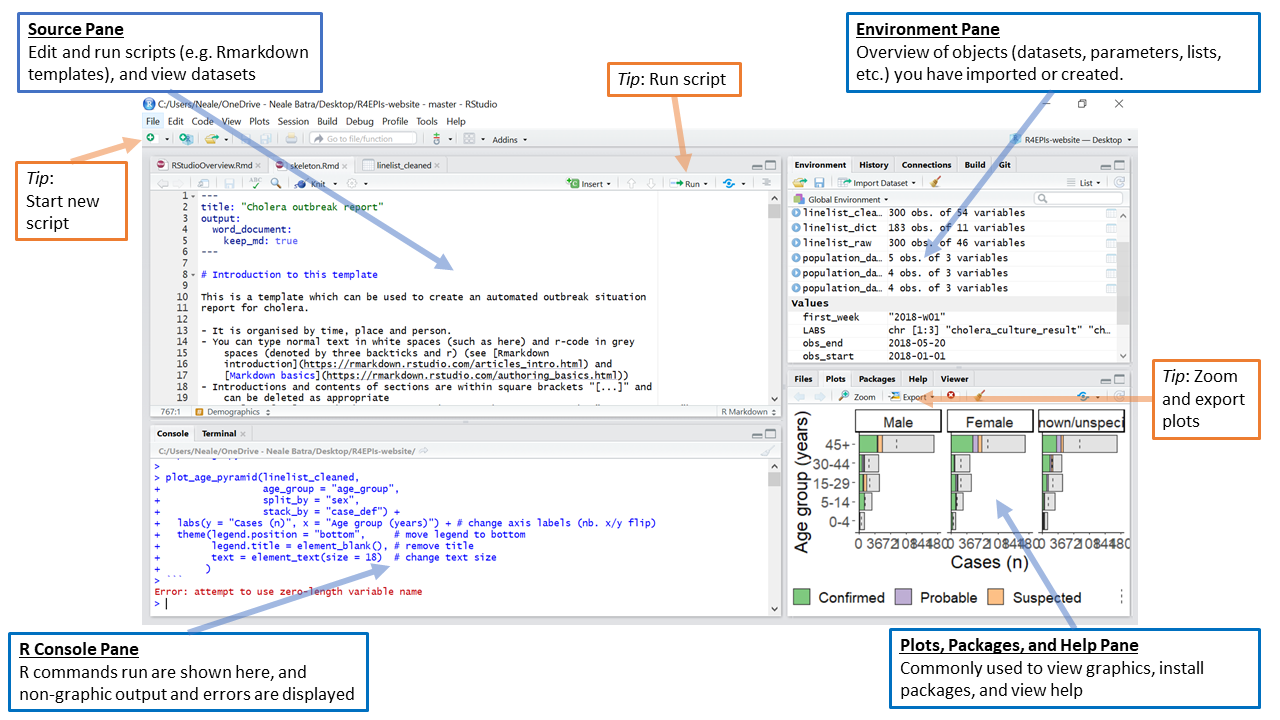
СОВЕТ: Если в вашем RStudio отображается только одна левая панель, это происходит потому что вы еще не открыли скрипты.
Панель Source (источник)
Эта панель, по умолчанию расположенная в верхней левой части, представляет собой пространство для редактирования, выполнения и сохранения ваших скриптом. Скрипты содержат команды, которые вы хотите выполнить. На этой панели также могут отображаться наборы данных (датафреймы) для просмотра.
Для пользователей Stata, данная панель похожа на окна Do-file и Data Editor.
Панель R Console (консоль)
Консоль R, по умолчанию расположенная в нижней левой части в R Studio, является местом расположения “двигателя” R. Здесь происходит собственно выполнение команд, и там же появляются неграфические выходные данные и сообщения об ошибках/предупреждения. Вы можете вводить и выполнять команды напрямую в Консоли R, но нужно понимать, что эти команды не сохраняются, как при выполнении команд из скрипта.
Если вы знакомы со Stata, Консоль R похожа на командное окно и окно результатов.
Панель Environment (рабочая среда)
Данная панель, по умолчанию расположенная в верхней правой части, является наиболее часто используемой для просмотра краткой информации по объектам в рабочей среде R в рамках текущей сессии. Эти объекты могут включать импортированные, модифицированные или созданные наборы данных, заданные вами параметры (например, конкретная эпиднеделя для анализа), либо векторы или списки, которые вы задали во время анализа (например, названия регионов). Вы можете нажат на стрелку рядом с названием датафрейма, чтобы увидеть его переменные.
Эта понель похожа на окно Менеджера переменных в Stata.
В этой панели также содержится Источрия, где вы можете увидеть предыдущие команды. В ней также есть вкладка “Tutorial” (обучение), где вы можете пройти интерактивное обучение по R, если у вас установлен пакет learnr. It also has a “Connections” pane for external connections, and can have a “Git” pane if you choose to interface with Github.
Панель Plots (графики), Viewer (просмотр), Packages (пакеты), и Help (справка)
Нижняя правая панель включает в себя несколько важных вкладок. Типичные графики, включая карты, будут отображаться на панели Plot (график). Интерактивные или HTML выходные данные будут отображаться в панели Viewer (просмотр). Панель Help (справка) может отображать файлы с документацией и со справкой. Панель Files (файлы) является средством просмотра, который можно использовать для открытия или удаления файлов. Панель Packages (пакеты) позволяет вам видеть, устанавливать, обновлять, удалять загружать/сбрасывать пакеты R, а также просматривать, какая у вас версия пакета. Чтобы получить дополнительную информацию о пакетах, см. раздел пакеты ниже.
В данную панель входит функционал, похожий на окна Менеджера графиков и Менеджера проекта в Stata.
Настройки RStudio
Изменить настройки и вид RStudio можно в выпадающем меню во вкладке Tools (инструменты), выбрав Global Options (глобальные опции). Там можно изменить настройки по умолчанию, включая внешний вид/цвет фона.
Перезапуск
Если R зависнет, вы можете перезапустить R, зайдя в меню Сессии и нажав “Restart R (перезапуск R)”. Это позволит избежать необходимости закрытия и открытия RStudio. Когда вы выполните это действие, все объекты из вашей рабочей среды будут удалены.
Горячие клавиши
Ниже представлены полезные сочетания клавиш. См. все горячие клавиши для Windows, Max и Linux на второй странице данной шпаргалки по пользовательскому интерфейсу RStudio.
| Windows/Linux | Mac | Действие |
|---|---|---|
| Esc | Esc | Прерывает текущую команду (полезно, если вы случайно выполнили неполную команду, не можете выйти и видите “+” в консоли R) |
| Ctrl+s | Cmd+s | Сохраняет (скрипт) |
| Tab | Tab | Автозаполнение |
| Ctrl + Enter | Cmd + Enter | Выполняет текущую строку(и)/выбранный код |
| Ctrl + Shift + C | Cmd + Shift + c | Комментирование/снятие комментария с выделенных строк |
| Alt + - | Option + - | Вставка <-
|
| Ctrl + Shift + m | Cmd + Shift + m | Вставка %>%
|
| Ctrl + l | Cmd + l | Очистка консоли R |
| Ctrl + Alt + b | Cmd + Option + b | Выполнить, начиная с начала до текущей строки |
| Ctrl + Alt + t | Cmd + Option + t | Выполнить текущий раздел кода (R Markdown) |
| Ctrl + Alt + i | Cmd + Shift + r | Вставить блок кода (в R Markdown) |
| Ctrl + Alt + c | Cmd + Option + c | Выполнить текущий блок кода (R Markdown) |
| Стрелки вверх/вниз на консоли R | Те же | Переключение через последние выполненные команды |
| Shift + Стрелки вверх/вниз в скрипте| Те же | Выбор нескольких строк кода | |
| Ctrl + f | Cmd + f | Найти и заменить в текущем скрипте |
| Ctrl + Shift + f | Cmd + Shift + f | Найти в файлах (поиск/замена в нескольких скриптах) |
| Alt + l | Cmd + Option + l | Свернуть выбранный код |
| Shift + Alt + l | Cmd + Shift + Option+l | Развернуть выбранный код |
СОВЕТ: Используйте клавишу Tab при печатании, чтобы задействовать функционал RStudio по автозаполнению. Это позволит избежать ошибок в правописании. Нажмите Tab при печатании, чтобы вышло выпадающее меню с наиболее вероятными функциями и объектами, исходя из уже напечатанного вами текста.
3.6 Функции
Функции лежат в основе использования R. Функции позволяют выполнять задачи и операции. Многие функции уже установлены в R, многие доступны к скачиванию в пакетах (объясняются в разделе пакеты), и вы можете даже написать свои собственные функции!
В этом разделе по основам функций объясняется:
- Что такое функция и как она работает
- Что такое аргументы функции
- Как получить помощь, чтобы понять функцию
Краткий комментарий по синтаксису: В данном руководстве функции записаны в тексте кода с открытыми скобками, например: filter(). Как объясняет раздел пакеты, функции скачиваются в пакетах. В данном руководстве названия пакетов пишутся жирным, например, dplyr. Иногда в примере кода вы можете увидеть название функции, сразу связанное с названием пакета с помощью двойного двоеточия (::), например: dplyr::filter(). Цель такой связки объясняется в разделе пакеты.
Простые функции
Функция как машина, которая получает вводные данные, как-то их преобразует и выдает результат. Каким будет результат, зависит от функции.
Функции, как правило, работают над каким-то объектом, размещенным в скобках в функции. Например, функция sqrt() вычисляет квадратный корень числа:
sqrt(49)[1] 7Объектом, заданным для функции, может быть столбец в наборе данных (см. раздел Объекты для более детальной информации о всех типах объектов). Поскольку в R может храниться несколько наборов данных, вам нужно будет уточнить и набор данных, и столбец. Это можно сделать, используя знак $, чтобы связать название набора данных и название столбца (dataset$column). В примере ниже функция summary() применяется к числовому столбцу age (возраст) в наборе данных linelist, а результатом является сводная информация по числовым и отсутствующим значениям в столбце.
# Печатает сводную статистику по столбцу 'age' в наборе данных 'linelist'
summary(linelist$age) Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
0.00 6.00 13.00 16.07 23.00 84.00 86 ПРИМЕЧАНИЕ: Фоново функция представляет собой сложный дополнительный код, который упакован для пользователя в одну простую команду.
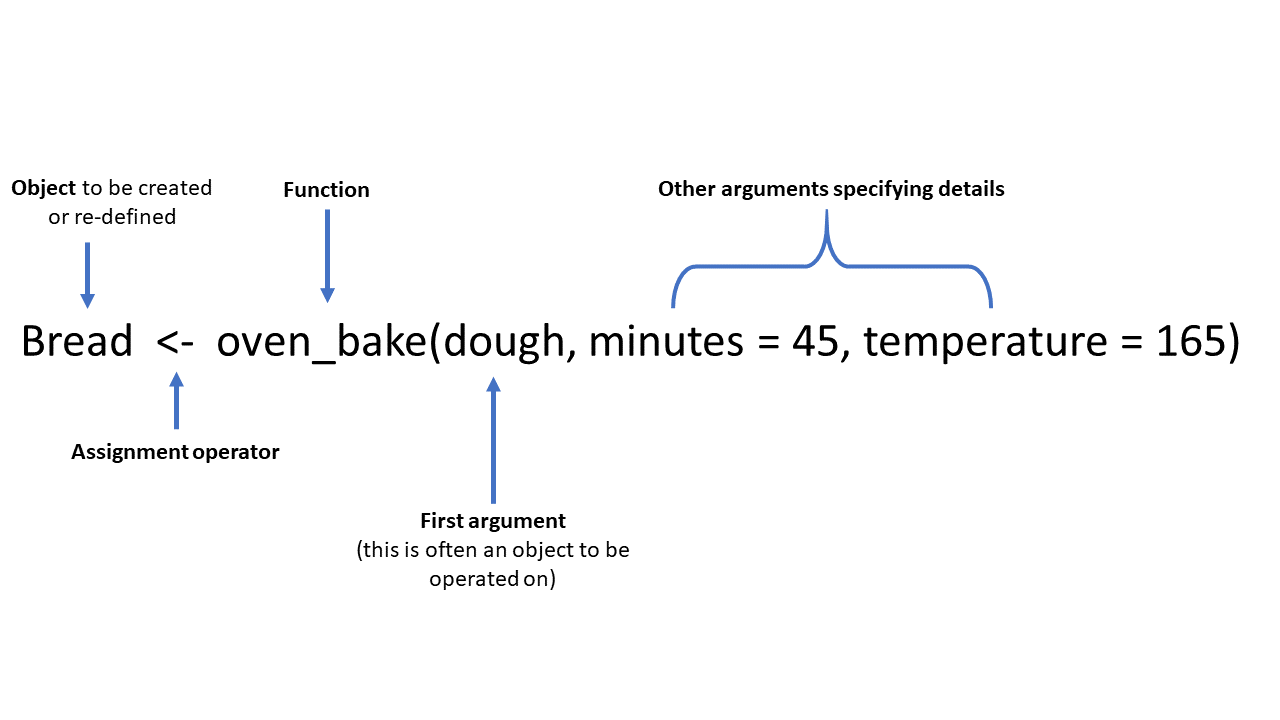
Функции с несколькими аргументами
Функции часто требуют нескольких вводных данных, которые называются аргументы, которые располагаются внутри скобок функции, и, как правило, разделяются запятыми.
- Некоторые аргументы обязательны для правильной работы функции, другие являются опциональными
- Опциональные аргументы имеют настройки по умолчанию
- Аргументы могут быть текстовыми, числовыми, логическими (TRUE/FALSE (ИСТИНА/ЛОЖЬ)) и другими
Здесь вы видите интересную выдуманную функцию, которая называется oven_bake() (печем пирог), она является примером типичной функции. Она берет входной объект (например, набор данных или в данном случае “тесто”) и проводит операции с ним, указанные с помощью дополнительных аргументов (minutes = (минуты) и temperature = (температура)). Выходные данные могут быть напечатаны в консоли, либо сохранены в качестве объекта, используя оператор присваивания <-.
Если рассмотреть более реалистичный пример, команда age_pyramid() ниже создает график возрастной пирамиды на основе заданных возрастных групп и двоичной графы gender (пол). Функции задаются три аргумента в скобках, которые отделяются запятыми. Значения, заданные в виде аргументов, определяют используемый датафрейм linelist, age_cat5 как столбец для подсчета, а gender как двоичный столбец для разделения пирамиды по цветам.
# Создание возрастной пирамиды
age_pyramid(data = linelist, age_group = "age_cat5", split_by = "gender")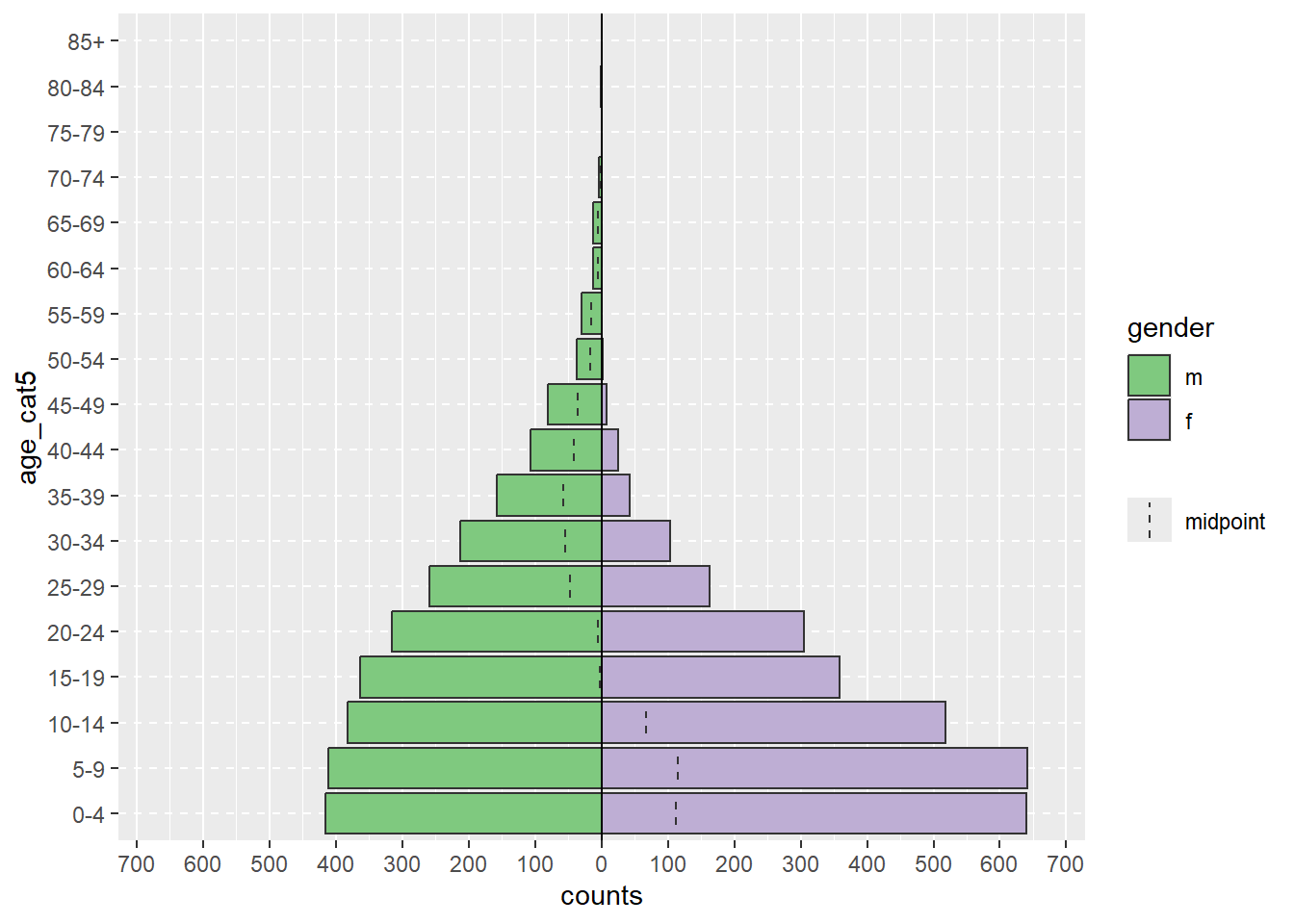
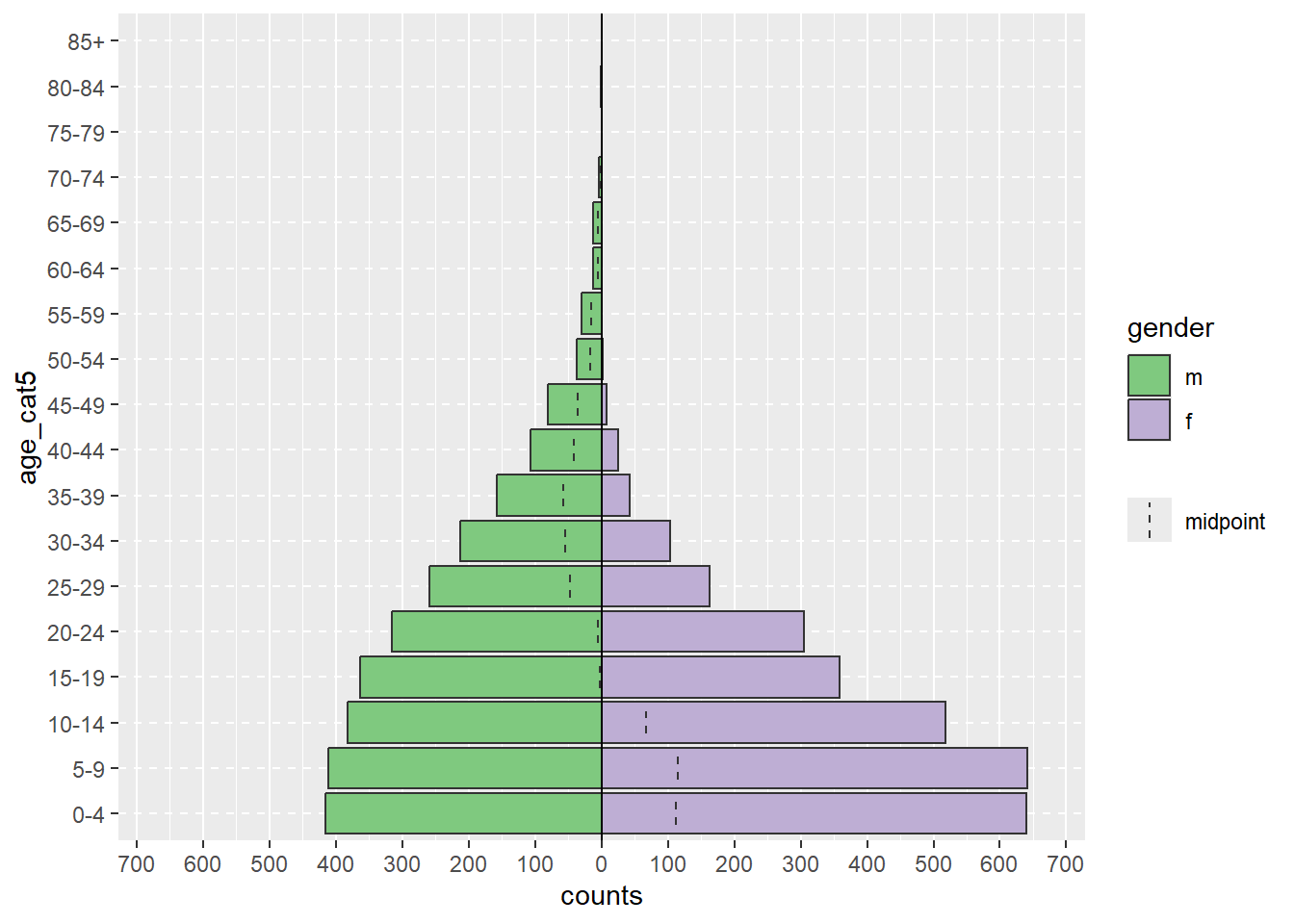
Указанные выше команды могут быть также записаны так, как указано ниже, более длинным стилем, где каждый аргумент начинается с новой строки. Этот стиль кодирования легче читать, к нему легче писать “комментарии” с помощью знака #, чтобы пояснить каждую часть (подробные комментарии - хорошая практика!). Чтобы выполнить эту более длинную команду, вы можете выделить всю команду и нажать “Run”, либо просто поместите курсор в первую строку и нажмите одновременно клавиши Ctrl и Enter.
# Создание возрастной пирамиды
age_pyramid(
data = linelist, # использовать построчный список случаев
age_group = "age_cat5", # задать столбец возрастной группы
split_by = "gender" # использовать столбец gender для двух сторон пирамиды
)
Первая половина присваивания аргумента (например, data =) не обязательно требует уточнения, если аргументы пишутся в указанном порядке (порядок указывается в документации по функции). Указанный ниже код выдаст абсолютно идентичную пирамиду, что и выше, поскольку функция ожидает порядка аргументов: датафрейм, переменная age_group (возрастная группа), переменная split_by (разделить по).
# Эта команда выдаст такой же график, что и выше
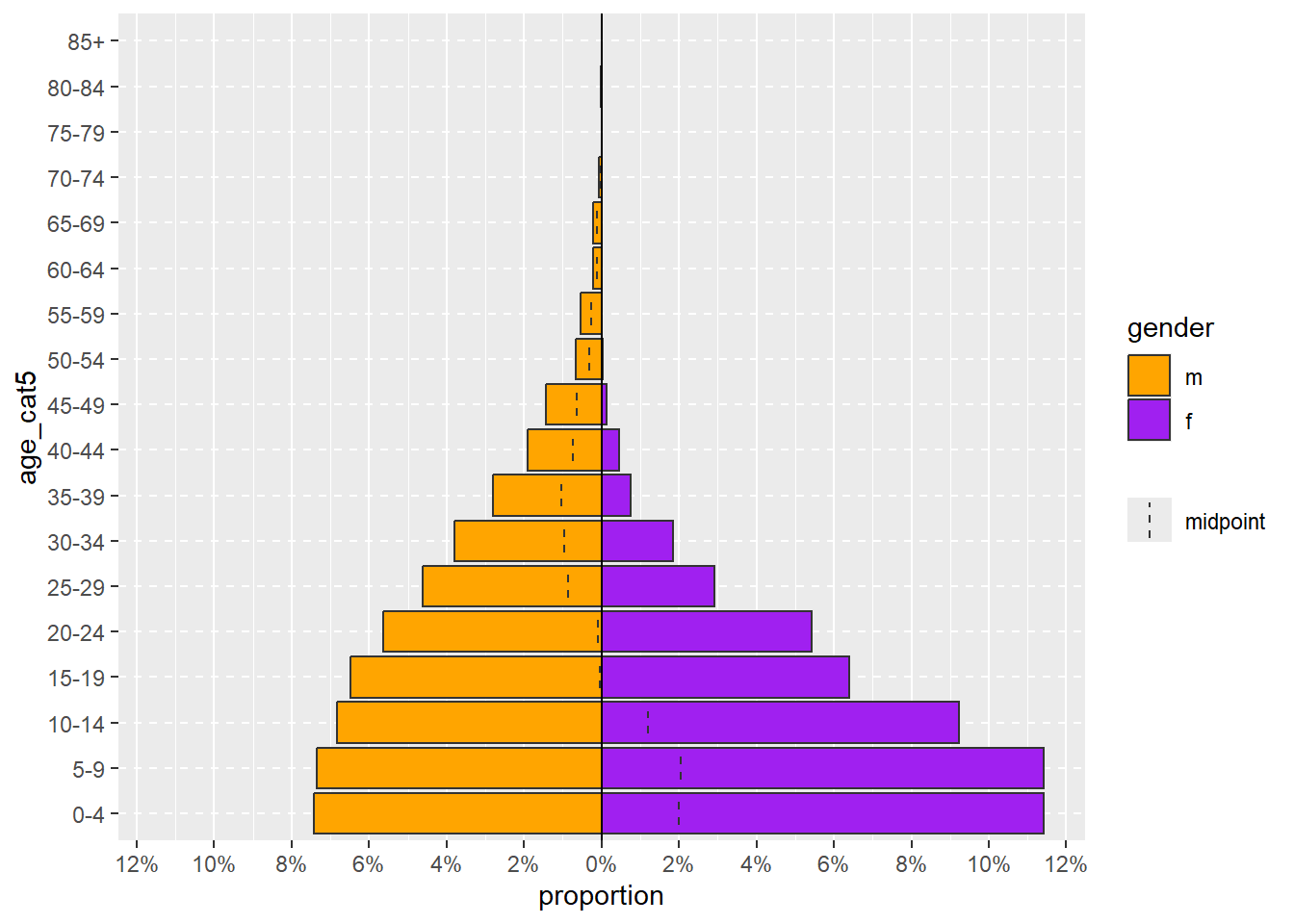
age_pyramid(linelist, "age_cat5", "gender")Более сложная команда age_pyramid() может включать опциональные аргументы, чтобы:
- Показать пропорции вместо абсолютных чисел (установить
proportional = TRUE, хотя по умолчанию стоитFALSE)
- Указать два цвета, которые будут использованы (
pal =это сокращение от слова “палетка”, в которой есть векторы двух названий цветов. См. страницу объекты для получения информации о том, как функцияc()создает вектор)
ПРИМЕЧАНИЕ: Для аргументов, для которых вы указываете обе части аргумента (например, proportional = TRUE), их порядок среди всех других аргументов не имеет значения.
age_pyramid(
linelist, # использовать построчный список случаев
"age_cat5", # столбец возрастной группы
"gender", # разделить по полу
proportional = TRUE, # проценты вместо абсолютного количества
pal = c("orange", "purple") # цвета
)
Написание Функций
R - язык, построенный на основе функций, поэтому вы можете свободно писать свои собственные функции. Создание функций даст вам ряд преимуществ:
- Облегчит модульное программирование - разделение кода на независимые и управляемые блоки
- Заменит многократное копирование и вставку, которое несет риск ошибок
- Даст блокам кода запоминающиеся названия
Написание функции более детально изучается на странице Написание функций.
3.7 Пакеты
Пакеты содержат функции.
Пакет R - набор кода и документации, которыми можно делиться и которые содержат заранее заданные функции. Пользователи в сообществе R все время разрабатывают пакеты для решения конкретных проблем, вероятно, что кто-то из них сможет помочь вам с вашей работой! В процессе использования R вы будете устанавливать и использовать множество пакетов.
При установке R содержит “базовые” пакеты и функции, которые выполняют частые элементарные задачи. Но многие пользователи R создают специализированные функции, которые проверяются сообществом R, и которые вы можете скачать в виде пакета для собственного использования. В данном руководстве названия пакетов записываются жирным. Одним из сложных аспектов R является то, что часто существует множество функций или пакетов для выполнения одной и той же задачи, из которых вы можете выбирать.
Установка и загрузка
Функции содержатся внутри пакетов, которые можно скачать (“установить”) на ваш компьютер с интернета. Как только пакет скачан, он хранится в вашей “библиотеке”. Затем вы можете получить доступ к функциям, которые содержатся в пакетах в ходе текущей сессии R, “загрузив” пакет.
Считайте R вашей личной библиотекой: Когда вы скачиваете пакет, в вашей библиотеке появляется новая книга функций, но каждый раз, когда вы хотите использовать функцию из этой книги, вам нужно взять эту книгу (“загрузить”) из библиотеки.
Подведем итог: чтобы использовать функции, доступные в пакете R, необходимо выполнить 2 шага:
- Пакет необходимо установить (один раз), и
- Пакет необходимо загрузить (при каждой сессии R)
Ваша библиотека
Ваша “библиотека” на самом деле является папкой в вашем компьютере, в которой содержится папка для каждого пакета, который был установлен. Найдите, где установлен R на вашем компьютере, найдите папку под названием “win-library”. Например: R\win-library\4.0 (4.0 - это версия R - у вас будет разная библиотека для каждой скаченной версии R).
Вы можете вывести путь к файлу для вашей библиотеки, введя .libPaths() (пустые скобки). Это станет особенно важно, если вы работаете с R на сетевых дисках.
Установка из CRAN
Наиболее часто пользователи R скачивают пакеты из CRAN. CRAN (Комплексная сеть архива R) - это онлайн публичное хранилище пакетов R, которые были опубликованы сообществом R.
Вы боитесь вирусов и обеспокоены вопросами безопасности при скачивании пакета с CRAN? Прочитайте эту статью по данной теме.
Как установить и загрузить
В данном руководстве мы советуем использовать пакет pacman (сокращение от “package manager (менеджер пакетов)”). В нем есть удобная функция p_load(), которая установит пакет, если необходимо, и загрузит его для использования в текущей сессии R.
Синаксис очень прост. Просто укажите названия пакетов внутрти скобок p_load(), отделив запятыми. Эта команда установит пакеты rio, tidyverse и here, если они еще не установлены, а также загрузит их для использования. Это делает подход p_load() удобным и кратким, если вы делитесь скриптами с другими. Обратите внимание, что названия пакетов чувствительны к регистру.
# Установить (если необходимо) и загрузить пакеты для использования
pacman::p_load(rio, tidyverse, here)Обратите внимание, что мы использовали синтаксис pacman::p_load(), в котором четко записано название пакета (pacman) перед названием функции (p_load()), и они соединены двумя двоеточиями ::. Этот синтаксис полезен, поскольку он также загружает пакет pacman (если он уже установлен).
Существуют альтернативные базовые функции R, с которыми вы будете часто сталкиваться. Базовая функция R для установки пакета - это install.packages(). Название пакета для установки необходимо указать в скобках в кавычках. Если вы хотите установить несколько пакетов одной командой, они должны быть перечислены внутри вектора символов c().
Примечание: эта команда устанавливает пакет, но не загружает его для использования в текущей сессии.
# установка одного пакета с помощью базового R
install.packages("tidyverse")
# установка нескольких пакетов с помощью базового R
install.packages(c("tidyverse", "rio", "here"))Установку можно также выполнить, зайдя в панель RStudio “Packages” (пакеты) и нажав “Install” (установить) и поискав название необходимого пакета.
Базовая функция в R для загрузки пакета для использования (после того, как он установлен) - это library(). Она может загружать только по одному пакету за раз (еще одна причина, почему лучше использовать p_load()). Вы можете указать название пакета с или без кавычек.
# загружает пакеты для использованя с базовым R
library(tidyverse)
library(rio)
library(here)Чтобы проверить, установлен ли и/или загружен ли пакет, вы можете просмотреть панель Packages (пакеты) в RStudio. Если пакет установлен, он будет отражаться там с номером версии. Если стоит галочка рядом с ним, значит он загружен для текущей сессии.
Установка с Github
Иногда может потребоваться установить пакет, которого еще нет на CRAN. Или, может быть, пакет есть на CRAN, но вам нужна версия разработчиков с новыми свойствами, которые еще недоступны в более стабильной опубликованной версии CRAN. Такие пакеты часто размещаются на сайте github.com в бесплатном общедоступном “репозитории” кода. Более детальную информацию о Github вы можете получить в данном руководстве на странице [Контроль версий и совместная работа с помощью Git и Github].
Чтобы скачать пакеты R с Github, вы можете использовать функцию p_load_gh() из pacman, которая установит пакет, если необходимо, и загрузит для использования в текущей сессии R. Альтернативно можно провести установку с помощью пакетов remotes или devtools. Более подробную информацию обо всех функциях pacman можно прочитать в документации по пакету.
Для установки с Github вам нужно задать больше информации. Вы должны указать:
- Github ID владельца репозитория
- Название репозитория, в котором содержится пакет
- (опционально) Название “ветви” (конкретной версии разработчика), которую вы хотите скачать
В примерах ниже первое слово в кавычках - это Github ID владельца репозитория, после слэша идет название репозитория (название пакета).
# установка/загрузка пакета epicontacts из репозитория Github
p_load_gh("reconhub/epicontacts")Если вы хотите произвести установку из другой “ветви” (версии), а не из основной ветви, добавьте название ветви после “@”, после названия репозитория.
# установка ветви "timeline" для пакета epicontacts из Github
p_load_gh("reconhub/epicontacts@timeline")Если нет разницы между версией в Github и версией на вашем компьютере, никакие действия не будут выполнены. Вы можете принудительно сделать переустановку, используя p_load_current_gh() с аргументом update = TRUE. Более подробно о pacman можно почитать в этой онлайн виньетке
Установка из ZIP или TAR
Вы можете установить пакет из URL:
packageurl <- "https://cran.r-project.org/src/contrib/Archive/dsr/dsr_0.2.2.tar.gz"
install.packages(packageurl, repos=NULL, type="source")Либо скачать его на свой компьютер в архиве:
Вариант 1: использовать install_local() из пакета remotes
remotes::install_local("~/Downloads/dplyr-master.zip")Вариант 2: использовать install.packages() из базового R, указав путь к ZIP файлу и установив type = "source и repos = NULL.
install.packages("~/Downloads/dplyr-master.zip", repos=NULL, type="source")Синтаксис кода
Для ясности в руководстве функции иногда приводятся с указанием сначала названия пакета, используя символ :: следующим образом: package_name::function_name()
Как только пакет загружен для сессии такой подробный стиль уже не нужен. Можно просто использовать function_name(). Однако написание названия пакета полезно, если у функции частое название, которое может существовать в нескольких пакетах (например, plot()). Написание названия пакета также позволит загрузить пакет, если он еще не загружен.
# Данная команда использует пакет "rio" и его функцию "import()" для импорта набора данных
linelist <- rio::import("linelist.xlsx", which = "Sheet1")Справка по функциям
Чтобы почитать дополнительную информацию о функции вы можете найти ее во вкладке Help (справка) в нижней правой части RStudio. Вы можете также выполнить команду ?thefunctionname (напишите название функции после знака вопрос) и появится страница Справка на панели Справка. Либо можно поискать ресурсы онлайн.
Обновление пакетов
Вы можете обновить пакеты, переустановив их. Вы можете также кликнуть зеленую кнопку “Update” (обновления) на панели RStudio Packages (пакеты), чтобы проверить, у каких пакетов есть новые версии для установки. Имейте ввиду, что может потребоваться обновление вашего старого кода, если произошли серьезные изменения в работе функции!
Удаление пакетов
Используйте p_delete() из pacman, или remove.packages() из базового R. Альтернативно, найдите папку, в которой содержится ваша библиотека, и вручную удалите папку.
Взаимозависимости
В работе пакеты часто зависят от других пакетов. Это называется взаимозависимостью. Если взаимозависимость не установлена, тогда, возможно, зависящий от нее пакет также не установится.
Проверить взаимозависимости пакета можно с помощью p_depends(), а увидеть, какие пакеты зависят от этого с помощью p_depends_reverse()
Маскирование функций
Часто бывает так, что в двух или нескольких пакетах есть функции с одинаковыми названиями. Например, в пакете dplyr есть функция filter(), но она же есть и в пакете stats. То, какая функция filter() будет использоваться по умолчанию, зависит от порядка, в котором изначально загружены эти пакеты в сессии R - более поздняя будет функцией по умолчанию для команды filter().
Вы можете проверить порядок в панели Environment (рабочая среда) в R Studio - кликните в выпадающем меню на “Global Environment” (глобальная среда) и посмотрите порядок пакетов. Функции из пакетов, расположенных ниже в этом выпадающем списке будут маскировать функции с тем же названием в пакетах, которые расположены выше в выпадающем списке. Изначально при загрузке пакета R предупредит вас в консоли, если происходит маскирование, но это предупреждение легко пропустить.
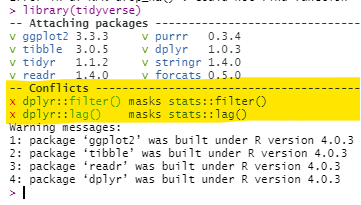
Способы исправления маскирования:
- Указать название пакета в команде. Например, используйте
dplyr::filter()
- Изменить порядок загрузки пакетов (например, в
p_load()), и начать новую сессию R
Открепление / сброс
Чтобы открепить (сбросить) пакет, используйте эту команду с правильным названием пакета и с одним двоеточием. Обратите внимание, что это не всегда устранит маскирование.
detach(package:PACKAGE_NAME_HERE, unload=TRUE)Установка более старой версии
См. данное руководство, чтобы установить более старую версию конкретного пакета.
Рекомендованные пакеты
См. страницу Рекомендованные пакеты со списком пакетов, которые мы рекомендуем для повседневной эпидемиологии.
3.8 Скрипты
Скрипты - фундаментальная часть программироввания. Это документы, которые содержат ваши команды (например, функции для создания и модификации наборов данных, вывода визуализаций и т.п.). Вы можете сохранить скрипт и выполнить его еще раз позже. Существует множество преимуществ хранения и выполнения команд из скрипта (по сравнению с печатанием команд по одной в консоли R в “командной строке”):
- Переносимость - вы можете делиться своей работой с другими, отправив им свои скрипты
- Воспроизводимость - чтобы и вы, и другие точно знали, что именно вы сделали
- Контроль версий - чтобы вы могли отслеживать изменения, которые внесли вы сами или коллеги
- Комментирование/аннотации - чтобы пояснить коллегам, что вы сделали
Комментирование
В скрипте вы можете также комментировать свой код R. Комментирование полезно, чтобы объяснить самому себе и другим пользователям, что именно вы делаете. Добавить комментарий можно, напечатав символ решетки (#) и записав после него свой комментарий. Текст комментария будет выделен другим цветом по сравнению с кодом R.
Код, записанный после знака #, не будет выполняться. Следовательно, вы можете поставить # перед кодом, чтобы временно заблокировать строку кода (“закомментировать”), если вы не хотите удалять ее). Вы можете закомментировать/снять комментирование с нескольких строк сразу, выделив их и нажав Ctrl+Shift+c (Cmd+Shift+c для Mac).
# Комментарий может быть отдельной строкой
# Импорт данных
linelist <- import("linelist_raw.xlsx") %>% # комментарий может стоять после кода
# filter(age > 50) # Может быть использован для деактивации/блокировки строки кода
count()- Комментируйте, что вы делаете и почему вы это делаете.
- Разбивайте код на логичные разделы
- Сопровождайте код текстовым пошаговым описанием того, что вы делаете (например, пронумерованные шаги)
Стиль
Важно обращать внимание на свой стиль кодирования - особенно при работе в команде. Мы призываем использовать tidyverse руководство по стилю. Существуют также такие пакеты, как styler и lintr, которые помогут вам соблюдать этот стиль.
Несколько простых правил, чтобы ваш код был понятен другим:
* При именовании объектов используйте только строчные буквы, цифры и нижние подчеркивания _, например, my_data
* Часто используйте пробелы, в том числе вокруг операторов, например, n = 1 и age_new <- age_old + 3
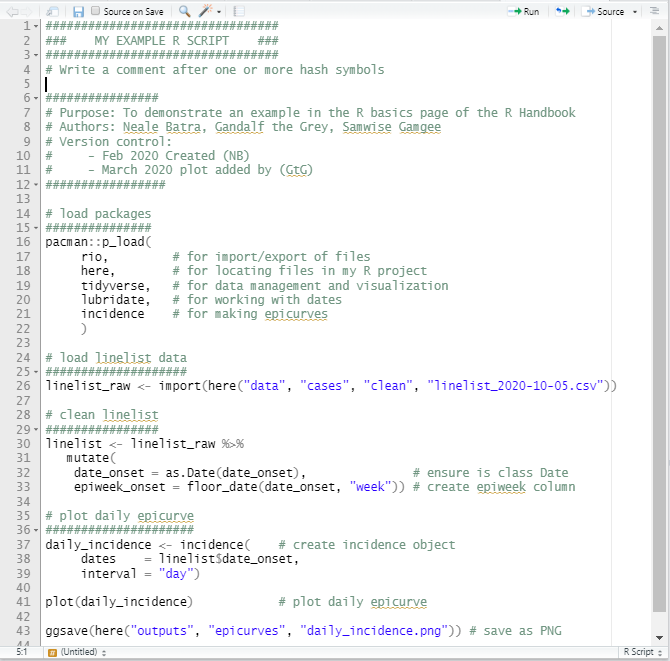
Пример скрипта
Ниже представлен пример короткого скрипта в R. Помните, чем лучше вы сможете кратко пояснить свой код в комментариях, тем больше ваши коллеги будут вас любить!
R markdown
Скрипт R markdown - тип скрипта R, в котором сам скрипт становится выводимым в результате документом (PDF, Word, HTML, Powerpoint, и т.п.). Это очень полезные и разнообразные инструменты, которые часто используются для создания динамичных и автоматизированных отчетов. Даже этот сайт и руководство создано с помощью скриптов R markdown!
Следует отметить, что новички в R также могут использовать R Markdown - не бойтесь его! Для получения дополнительной информации см. страницу руководства Отчеты с помощью R Markdown.
R notebooks
Нет разницы между написанием в Rmarkdown и R notebook. Однако выполнение документа чуть отличается. См. сайт для получения дополнительной информации.
Shiny
Приложения/сайты Shiny содержатся внутри одного скрипта, который должен называться app.R. У этого файла три компонента:
- Пользовательский интерфейс (ui)
- Серверная функция
- Функция обращения к
shinyApp
См. страницу руководства Информационные панели с Shiny, либо онлайн самоучитель: Самоучитель по Shiny
Раньше указанный выше файл делился на два файла (ui.R и server.R)
Сворачивание кода
Вы можете свернуть блоки кода, чтобы улучшить читаемость вашего скрипта.
Чтобы это сделать, создайте заголовок текста с помощью #, напишите заголовок, после него поставьте не менее 4 дефисов (-), решеток (#) или знаков равно (=). После того, как вы это сделаете, на “полях” слева (рядом с номером строки) появится маленькая стрелочка. Вы можете кликнуть на эту стрелку и код под ней до следующего заголовка будет свернут, а вместо него появится иконка с двойной стрелкой.
Чтобы развернуть код, кликните снова на стрелку на полях, либо на иконку с двойной стрелкой. Существуют также быстрые сочетания клавиш на клавиатуре, которые представлены в разделе RStudio на данной странице.
Создавая заголовки с помощью #, вы также активируете Содержание внизу вашего скрипта (см. ниже), которое вы сможете использовать для навигации по скрипту. Вы можете создавать подзаголовки, добавляя дополнительные символы #, например, # для основного заголовка, ## для подзаголовка второго уровня и ### для подзаголовка третьего уровня.
Ниже представлены две версии примера скрипта. Слева представлен оригинал с комментируемыми заголовками. Справа после каждого заголовка напечатаны четыре дефиса, что делает их сворачиваемыми. Два из них свернуты, и вы можете увидеть, что теперь в Содержании внизу указан каждый раздел.
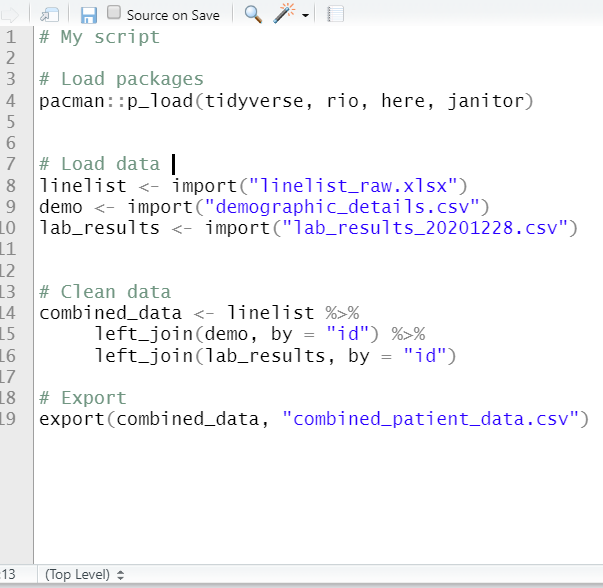
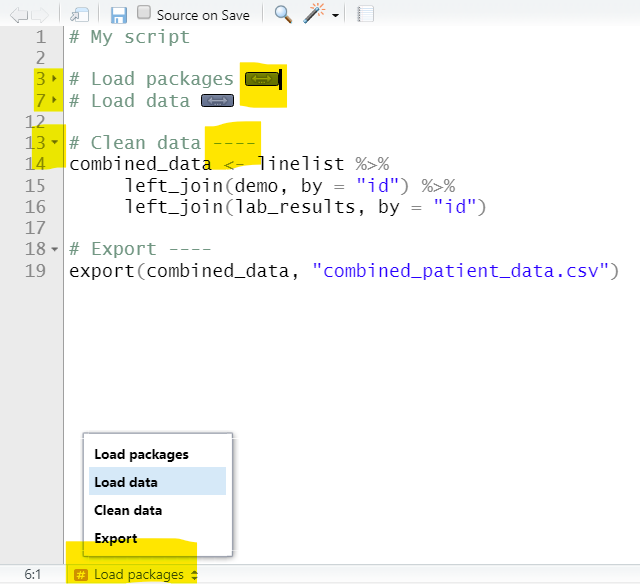
Другие зоны кода, которые автоматически могут сворачиваться, включают блоки со скобками { }, например определения функций или условные блоки (утверждения по принципу, если нет). Вы можете почитать дополнительную информацию о сворачивании кода на сайте RStudio.
3.9 Рабочая директория
Рабочая директория - корневая папка, используемая для вашей работы в R - то, где R ищет и сохраняет файлы по умолчанию. По умолчанию, программа будет сохранять новые файлы и выходные данные в эту папку, а также там будет искать файлы для импорта (например, наборы данных).
Рабочая директория отражается серым текстом в верхней части панели Console (консоль) RStudio. Вы можете также вывести текущую директорию, выполнив команду getwd() (оставьте скобки пустыми).

Рекомендованный подход
См. страницу [Проекты R] для получения детальной информации о рекомендуемом нами подходе к управлению рабочей директорией.
Частым, эффективным и беспроблемным способом управления рабочей директорией и путем к файлам является сочетание следующих 3 элементов в рабочем процессе в [Проекте R][R projects]:
- R Проект для хранения всех ваших файлов (см. страницу Проекты R)
- Пакет here для расположения файлов (см. страницу Импорт и экспорт)
- Пакет rio для импорта/экспорта файлов (см. страницу [Импорт и экспорт(importing.ru.qmd)])
Установка по команде
До недавних пор многих учили начинать скрипты в R с команды setwd(). Вместо этого, рассмотрите возможность использования рабочий процесс, ориентированный на Проект R и прочитайтепричины не использовать setwd(). Вкратце, ваша работа становится специфичной для вашего компьютера, пути к файлам, использованные для импорта и экспорта становятся “машинно-зависимыми”, а это серьезно осложняет совместную работу и использование вашего кода на других компьютерах Существуют простые альтернативы!
Как указано выше, хотя мы и не рекомендуем этот подход в большинстве ситуаций, вы можете использовать команду setwd() и указать желаемый путь к файлу в кавычках, например:
setwd("C:/Documents/R Files/My analysis")ВНИМАНИЕ: Установка рабочей директории с помощью setwd() может создать “машинно-зависимый” путь, если путь к файлу специфичен для конкретного компьютера. Вместо этого используйте пути к файлу, относительные для корневой директории R проекта (с помощью пакета here).
Установка вручную
Чтобы установить рабочую директорию вручную (кликовый аналог setwd()), кликните на меню Session (сессия), перейдите на “Set Working Directory” (установить рабочую директорию), а затем “Choose Directory” (выбрать директорию). Это задаст рабочую директорию для конкретной сессии R. Примечание: при использовании этого подхода, вам придется вручную выполнять это действие каждый раз, когда вы открываете RStudio.
Внутри проекта R
При использовании проекта R рабочая директория по умолчанию будет установлена на корневую папку проекта R, в которой находится файл “.rproj”. Это применимо, если вы открыли RStudio, кликнув на проект R (файл с расширением “.rproj”).
Рабочая директория для R markdown
В скрипте R markdown рабочей директорией по умолчанию будет папка, в которой сохранен файл Rmarkdown (.Rmd). При использовании проекта R и пакета here, этот принцип не применим, а рабочая директория будет here(), как объясняется на странице Проекты R.
Если вы хоитте сменить рабочую директорию отдельного R markdown (не в проекте R), если вы используете setwd(), это будет применимо только к этому конкретному блоку кода. Чтобы изменения были внесены во все блоки кода в R markdown, редактируйте установочный блок и добавьте параметр root.dir =, как указано ниже:
knitr::opts_knit$set(root.dir = 'desired/directorypath')Гораздо проще просто использовать R markdown в рамках проекта R и использовать пакет here.
Указание пути к файлу
Наверное, самым большим источником раздражения для начинающего пользователя R (по крайней мере, на компьютере на Windows) является впечатывание пути к файлу для импорта или экспорта данных. На странице Импорт и экспорт есть подробное объяснение того, как лучше всего указывать пути к фалам, но пока приведем ключевые моменты:
Сломанный путь к файлу
Ниже представлен пример “абсолютного” или “полного” пути к файлу. Такие пути могут быть сломаны при использовании на другом компьютере. Исключением является ситуация, когда вы используете общий/сетевой диск.
C:/Users/Name/Document/Analytic Software/R/Projects/Analysis2019/data/March2019.csv Направление слэшей
При впечатывании пути к файлу обращайте внимание на направление слэшей. Используйте прямой слэш (/), чтобы отделить компоненты (“data/provincial.csv”). Для пользователей Windows по умолчанию отображаются пути к файлу с обратным слэшем (\) - так что вам нужно будет изменить направление каждого слэша. Если вы используете пакет here, как описано на странице проекты R направление слэшей не будет для вас проблемой.
Относительный путь к файлу
Как правило, мы рекомендуем указывать “относительный” путь к файлу - то есть, путь к файлу относительно коренной папки вашего Проекта R. Вы можете также сделать это с помощью пакета here, как указано на странице Проекты R. Относительный путь к файлу может выглядеть следующим образом:
# Импорт построчного списка в csv из подпапок data/linelist/clean/ для проекта R
linelist <- import(here("data", "clean", "linelists", "marin_country.csv"))Даже при использовании относительного пути к файлу в Проекте R, вы все еще можете использовать абсолютные пути для импорта/экспорта данных вне Проекта R.
3.10 Объекты
Всё в R является объектом, а R является “объектно-ориентированным” языком. В следующих разделах будет объяснено:
- Как создавать объекты (
<-) - Типы объектов (например, датафреймы, векторы..)
- Как получить доступ к частям объекта (например, переменным в наборе данных)
- Классы объектов (например, числовые, логические, цельночисленные, двойной точности, знаки, факторы)
Всё является объектом
Этот раздел адаптирован из проекта R4Epis.
Всё, что вы храните в R - наборы данных, переменные, список названий населенных пунктов, общее население, даже такие выходные данные, как графики - это объекты, которым присваивается имя и на которые можно ссылаться в последующих командах.
Объект существует, когда вы присвоили ему значение (см. раздел по присвоению ниже). При присваивании значения объект появится в Рабочей среде (см. правую верхнюю панель в RStudio). Затем с ним можно работать, преобразовывать, изменять или менять его определение.
Определение объектов (<-)
Создание объектов путем присвоения им значения с помощью оператора <- .
Вы можете рассматривать оператор присваивания <- как аналог слов “определяется как”. Команды присвоения, как правило, используют стандартный порядок:
название_объекта <- значение (или процесс/расчет, который даст значение)
Например, вы можете зафиксировать текущую эпидемиологическую отчетную неделю в качестве объекта, чтобы дальше ссылаться на нее в коде. В данном примере создается объект current_week, когда ему присваивается значение "2018-W10" (кавычки задают значение как текстовое). Объект current_week затем появится в панели Environment (Рабочая среда) RStudio (верхняя правая) и на него можно будет ссылаться в последующих командах.
См. команды R и их выходные данные во вставках ниже.
current_week <- "2018-W10" # эта команда создает объект current_week путем присвоения ему значения
current_week # эта команда выводит текущее значение объекта current_week в консоли[1] "2018-W10"ПРИМЕЧАНИЕ: Обратите внимание на [1] в выходных данных на консоли R просто указывает на то, что вы просматриваете первый пункт выходных данных
ВНИМАНИЕ: Значение объекта можно заменить в любой момент времени, выполнив команду присвоения для пересмотра значения. Таким образом порядо выполнения команд очень важен.
Следующая команда заменит значение current_week:
current_week <- "2018-W51" # присваивает НОВОЕ значение объекту current_week
current_week # выводит текущее значение current_week в консоли[1] "2018-W51"Знаки равно =
Вы также будете встречать знаки равно в коде R:
- Двойное равно
==между двумя объектами или значениями задает логический вопрос: “равно ли одно другому?”.
- Вы также будете видеть знаки равно внутри функций для указания значений аргументов функции (дополнительная информация об этом в разделах ниже), например,
max(age, na.rm = TRUE).
- Вы можете использовать один знак равно
=вместо<-для создания и определения объектов, но мы не рекомендуем этого делать. Вы можете прочитать о том, почему это не рекомендуется, здесь.
Наборы данных
Наборы данных - это также объекты (как правило, “датафреймы”), им необходимо присваивать имена при импорте. С помощью кода ниже созодается объект linelist и ему присваивается значение файла CSV, импортироавнного с помощью пакета rio и его функции import().
# создается построчный список и ему присваивается значение импортируемого CSV файла
linelist <- import("my_linelist.csv")Вы можете прочитать дополнительную информацию об импорте и экспорте наборов данных в разделе Импорт и экспорт.
ВНИМАНИЕ: Короткий комментарий по именованию объектов:
- В названиях объектов не должно быть пробелов, вместо этого используйте нижнее подчеркивание (_) или точку (.).
- Названия объектов чувствительны к регистру (то есть Dataset_A отличается от dataset_A).
- Названия объектов должны начинаться с буквы (не могут начинаться с цифры, например, 1, 2 или 3).
Выходные данные
Выходные данные, такие как таблицы и графики, являются примером того, как можно сохранять выходные данные в виде объектов, либо выводить их без сохранения. Перекрестная таблица по полу и возрасту и ее результат с использованием базовой функции R table() можно вывести напрямую в консоль R (без сохранения).
# только выводится на консоль R
table(linelist$gender, linelist$outcome)
Death Recover
f 1227 953
m 1228 950Но ту же самую таблицу можно сохранить как именованный объект. Затем, при необходимости ее можно вывести (напечатать) на консоль.
# сохранить
gen_out_table <- table(linelist$gender, linelist$outcome)
# печать
gen_out_table
Death Recover
f 1227 953
m 1228 950Столбцы
Столбцы в наборе данных - также объекты, которые можно определить, переопределить и создать, как описано в разделе Столбцы ниже.
Вы можете использовать оператор присваивания из базового R, чтобы создать новый столбец. Ниже создается новый столбец bmi (Индекс массы тела), а для каждой строки новое значение является результатом математической операции со значениями строки в столбцах wt_kg и ht_cm.
# создание нового столбца "bmi" с помощью синтаксиса базового R
linelist$bmi <- linelist$wt_kg / (linelist$ht_cm/100)^2Однако в данном руководстве мы подчеркиваем другой подход к определению столбцов, который использует функцию mutate() из пакета dplyr и привязывание с помощью оператора канала (%>%). Такой синтаксис легче читать, а также имеются другие преимущества, которые объясняются на странице Вычистка данных и ключевые функции. Вы можете более подробно почитать про оператор канала в разделе Использование каналов ниже.
# создание нового столбца "bmi" с помощью синтаксиса dplyr
linelist <- linelist %>%
mutate(bmi = wt_kg / (ht_cm/100)^2)Структура объекта
Объекты могут быть одним элементом данных (например, my_number <- 24), либо могут состоять из структурированных данных.
Изображенмие ниже взято из данного онлайн самоучителя по R. Там показаны некоторые часто встречающиеся структуры данных и их названия. В эту графику не включены пространственные данные, которые рассматриваются на страницы Основы ГИС.
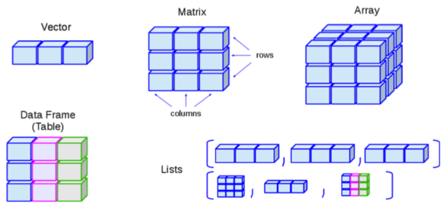
В эпидемиологии (а особенно в прикладной эпидемиологии), вы чаще всего будете сталкиваться с датафреймами и векторами:
4 Частая структураВекторы |
Объяснение | Пример | ==================================================================================================+=====================================================================================+ Контейнер для последовательности уникальных объектов, все из одного класса (например, числовые, текстовые). | “Переменные” (столбцы) в датафреймах являются векторами (например, столбец age_years). |
|
| Датафреймы | Векторы (например, столбцы), которые объединены, которые имеют одинаковое количество строк | Векторы (например, столбцы), которые объединены, которые имеют одинаковое количество строк | linelist является датафреймом. | |
|
Обратите внимание, что для создания “отдельного” вектора (который не является частью датафрейма) используется функция c() для связи разных элементов. Например, при создании вектора цветовой шкалы графика: vector_of_colors <- c("blue", "red2", "orange", "grey")
Классы объектов
Все объекты, хранящиеся в R имеют класс, который говорит R, как обращаться с объектом. Существует множество возможных классов, наиболее часто встречающиеся включают:
5 КлассТекстовый |
Объяснение | Примеры | =========================================================================================================================================================================================+=======================================================================================================+ Это текст/слова/предложения “в кавычках”. С этими объектами нельзя выполнять математические действия. | “Текстовые объекты пишутся в кавычках” | | ||
| Цельночисленный | Только целые числа (без десятичных знаков) | -5, 14, or 2000 | | |||
| Числовые | Числа, которые могут включать десятичные знаки. Если они будут в кавычках, они будут считаться текстовым классом. | 23.1 или 14 | | |||
| Факторы | Это векторы с конкретным порядком или иерархией значений | Переменная экономического статуса с упорядоченными значениями | Это векторы с конкретным порядком или иерархией значений | Переменная экономического статуса с упорядоченными значениями | |
||
| Дата | Как только вы скажете R, что определенные данные являются датой, с этими данными можно будет работать и отображать особенным образом. См. страницу Работа с датами для получения детальной информации. | 2018-04-12 или 15/3/1954 или Wed 4 Jan 1980 | ||
| Логические | Значения могут быть одним из двух специальных значений TRUE или FALSE (ИСТИНА или ЛОЖЬ) (обратите внимание, что это не “TRUE” и “FALSE” в кавычках) | TRUE или FALSE | | |||
| data.frame | Датафрейм - то, как R хранит типичный набор данных. Он состоит из векторов (столбцов) объединенных данных, у всех из которых одинаковое количество наблюдений (строк). | Пример набора данных AJS под названием linelist_raw содержит 68 переменных и по 300 наблюдений (строк) для каждой. | |
||
| tibble | таблицы tibble - вариация датафрейма, для которой основное отличие в том, что она более удобно выводится на консоль (отображает первые 10 строк и только те столбцы, которые влезут на экран) | Любой датафрейм, список или матрицу можно конвертировать в таблицу tibble с помощью as_tibble() | |
||
| Список | Список похож на вектор, но содержит другие объекты, которые могут быть в других классах | Список может содержать оодно число, датафрейм, вектор и даже другой список! | |
Вы можете проверить класс объекта, задав его имя в функции class(). Примечание: вы можете ссылаться на конкретный столбец в наборе данных, используя знак $, чтобы отделить название набора данных и название столбца.
class(linelist) # класс должен быть датафрейм (dataframe) или tibble[1] "data.frame"class(linelist$age) # класс должен быть числовой (numeric)[1] "numeric"class(linelist$gender) # класс должен быть текстовый (character)[1] "character"Иногда R автоматически конвертирует столбец в другой класс. Следите за этим! Например, если у вас есть вектор или столбец чисел, но вставлено текстовое значение… весь столбец изменится на текстовый класс.
num_vector <- c(1,2,3,4,5) # определение вектора как только чисел
class(num_vector) # вектор числового класса[1] "numeric"num_vector[3] <- "three" # конвертирован третий элемент в текстовый
class(num_vector) # вектор стал относиться к текстовому классу[1] "character"Частым примером этого является ситуация, когда вы изменяете датафрейм, чтобы напечатать таблицу - если вы создадите строку Итого и попытаетесь вставить/слепить проценты в той же ячейке, что числа (например, 23 (40%)), весь числовой столбец над этой ячейкой будет конвертирован в текстовы и больше не сможете проводить с ним математические расчеты.Иногда вам нужно будет конвертировать объекты или столбцы в другой класс.
6 Функция
|
7 ДействиеКонвертирует в текстовый класс |
|
as.numeric() |
Конвертирует в числовой класс | |
as.integer() |
Конвертирует в цельночисленный класс | |
as.Date() |
Конвертирует в класс Дата - Примечание: см. раздел даты для информации | | |
factor() |
Конвертирует в фактор - Примечание: изменение порядка уровней значений требует дополнительных аргументов |
Аналогично, существуют базовые функции R, чтобы проверить, относится ли объект к конкретному классу, например, is.numeric(), is.character(), is.double(), is.factor(), is.integer()
Здесь представлен дополнительный онлайн материал по классам и структурам данных в R.
Столбцы/Переменные ($)
Столбец в датафрейме технически является “вектором” (см. таблицу выше) - последовательностью значений, все из которых должны относиться к одному классу (текстовый, числовой, логический и т.п.).
Вектор может существовать независимо от датафрейма, например, вектор названий столбцов, которые вы хотите включать как независимые переменные в модель. Чтобы создать “отдельный” вектор, используйте функцию c(), как показано ниже:
# определение отдельного вектора текстовых значений
explanatory_vars <- c("gender", "fever", "chills", "cough", "aches", "vomit")
# печать значений данного именованного вектора
explanatory_vars[1] "gender" "fever" "chills" "cough" "aches" "vomit" Столбцы датафрейма также являются векторами, их можно называть, ссылаться, извлекать или создавать, используя символ $. Символ $ связывает имя столбца и имя датафрейма. В данном руководстве мы стараемся использовать слово “столбец” вместо “переменная”.
# Извлечение длины вектора age_years
length(linelist$age) # (age - столбец в датафрейме linelist)Если вы напечатаете название датафрейма, а затем $, вы увидите выпадающий список всех столбцов в датафрейме. Вы можете пролистать его с помощью клавиши стрелка, выбрать нужный пункт с помощью Enter и таким образом вы избежите орфографических ошибок!

ПРОДВИНУТЫЙ СОВЕТ: Некоторые более сложные объекты (например, спосок или объект epicontacts) могут иметьт несколько уровней, к которым вы можете получить доступ, используя несколько знаков доллара. Например, epicontacts$linelist$date_onset
Доступ/индекс с помощью квадратных скобок ([ ])
Вам может потребоваться просмотр частей объектов, что также называют “индексирование”, это часто делают с помощью квадратных скобок [ ]. Использование $ для датафрема для доступа к столбцу также является типом индексирования.
my_vector <- c("a", "b", "c", "d", "e", "f") # определение вектора
my_vector[5] # вывод на печать 5го элемента[1] "e"Квадратные скобки также работают, чтобы выдать вам конкретные части выданных выходных данных, например, результат функции summary():
# Вся сводная информация
summary(linelist$age) Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
0.00 6.00 13.00 16.07 23.00 84.00 86 # Только второй элемент сводной информации с названием (используя одноуровневые квадратные скобки)
summary(linelist$age)[2]1st Qu.
6 # Только второй элемент сводной информации без названия (используя двойные квадратные скобки)
summary(linelist$age)[[2]][1] 6# Извлечь элемент по названию, не показывая название
summary(linelist$age)[["Median"]][1] 13Квадратные скобки также работают в датафреймах для просмотра конкретных строк и столбцов. Вы можете это сделать с помощью следующего синтаксиса dataframe[rows, columns]:
# Просмотр конкретной строки (2) из набора данных со всеми столбцами (не забудьте запятую!)
linelist[2,]
# Просмотр всех строк, но только одного столбца
linelist[, "date_onset"]
# Просмотр значений из строки 2 и столбцов с 5 по 10
linelist[2, 5:10]
# Просмотр значений из строки 2 и столбцов с 5 по 10 и 18
linelist[2, c(5:10, 18)]
# Просмотр строк со 2 по 20, и конкретных столбцов
linelist[2:20, c("date_onset", "outcome", "age")]
# Просмотр строк и столбцов по критериям
# *** Обратите внимание, что необходимо назвать датафрейм в критериях!
linelist[linelist$age > 25 , c("date_onset", "outcome", "age")]
# Использование View(), чтобы просмотреть выходные данные в панели RStudio Viewer (просмотр) (так легче читать)
# *** Обратите внимание на заглавную букву "V" в функции View()
View(linelist[2:20, "date_onset"])
# Сохранение как нового объекта
new_table <- linelist[2:20, c("date_onset")] Обратите внимание, что вы можете провести указанное выше индексирование строк/столбцов в датафреймах и таблицах tibble, используя синтаксис dplyr (функции filter() для строк и select() для столбцов). Более подробную информацию по этим ключевым функциям вы можете получить на странице Вычистка данных и ключевые функции.
Для фильтра на основе “номера строки” вы можете использовать функцию dplyr row_number() с открытыми скобками как чатью утверждения для логического фильтра. Часто вы будете использовать оператор %in% и диапазон чисел в качестве логического утверждения, как показано ниже. Чтобы увидеть первые N строк, вы можете использовать специальную функцию dplyr head().
# Просмотр первых 100 строк
linelist %>% head(100)
# Показать только строку 5
linelist %>% filter(row_number() == 5)
# Просмотр строк со 2 по 20, а также трех конкретных столбцов (обратите внимание, что не нужны кавычки для названия столбцов)
linelist %>% filter(row_number() %in% 2:20) %>% select(date_onset, outcome, age)При индексации объекта в классе list (список), однократные скобки всегда выдают класс список, даже если выдан только один объект. Однако можно использовать двойные скобки для доступа к одному элементу и выведения его в другом классе, не как список.
Скобки могут быть также записаны одна за другой, как представлено ниже.
Данное визуальное объяснение индексации списков с перечницами является смешным и полезным.
# определение демо списка
my_list <- list(
# Первый элемент в списке - текстовый вектор
hospitals = c("Central", "Empire", "Santa Anna"),
# второй элемент в списке - датафрейм адресов
addresses = data.frame(
street = c("145 Medical Way", "1048 Brown Ave", "999 El Camino"),
city = c("Andover", "Hamilton", "El Paso")
)
)Вот так будет выглядеть список при печати в консоли. Обратите внимание на два именованных элемента:
-
hospitals, текстовый вектор
-
addresses, датафрейм адресов
my_list$hospitals
[1] "Central" "Empire" "Santa Anna"
$addresses
street city
1 145 Medical Way Andover
2 1048 Brown Ave Hamilton
3 999 El Camino El PasoТеперь мы проведем извлечение разными методами:
my_list[1] # выдает элемент класса "list" (список) - название элемента все еще отображается$hospitals
[1] "Central" "Empire" "Santa Anna"my_list[[1]] # выдает только текстовый вектор (без названия)[1] "Central" "Empire" "Santa Anna"my_list[["hospitals"]] # вы можете также провести индексирование по названию элемента списка[1] "Central" "Empire" "Santa Anna"my_list[[1]][3] # выдает третий элемент текстового вектора "hospitals"[1] "Santa Anna"my_list[[2]][1] # выдает первый столбец ("street") датафрейма адресов street
1 145 Medical Way
2 1048 Brown Ave
3 999 El CaminoУдаление объектов
Вы можете удалять отдельные объекты из вашей рабочей среды R, написав название в скобках в функции rm() (без кавычек):
rm(object_name)Вы можете удалить все объекты (очистить рабочее пространство), выполнив:
rm(list = ls(all = TRUE))
7.1 Использование каналов (%>%)
Два общих подхода к работе с объектами:
-
Каналы/tidyverse - каналы передают объект из функции в функцию - фокус на действии, а не на объекте
- Определение промежуточных объектов - объект постоянно переопределяется - фокус на объекте
Каналы
Если объяснять простыми словами, оператор канала (%>%) передает промежуточные выходные данные из одной функции в другую.
Представьте, что это как написать слово “затем”. Многие функции могут быть связаны между собой с помощью %>%.
-
Передача по каналу подчеркивает порядок действий, а не объект, с которым производятся действия
- Каналы лучше всего использовать, когда с одним объектом необходимо провести последовательные действия
- Каналы взяты из пакета magrittr, который автоматически включен в пакеты dplyr и tidyverse
- Каналы делают код чище и более удобно читаемым и интуитивно понятным
Более детально об этом подходе можно почитать в руководстве по стилю tidyverse
Рассмотрим выдуманный пример для сравнения, используя выдуманные функции “выпечки пирога”. Сначала используем метод каналов:
# Выдуманный пример того, как испечь пирог, используя синтаксис каналов
cake <- flour %>% # чтобы определить пирог, начинаем с муки, затем...
add(eggs) %>% # добавляем яйца
add(oil) %>% # добавляем масло
add(water) %>% # добавляем воду
mix_together( # смешиваем
utensil = spoon,
minutes = 2) %>%
bake(degrees = 350, # выпекаем
system = "fahrenheit",
minutes = 35) %>%
let_cool() # даем остытьВот еще одна ссылка, которая описывает полезность каналов.
Работа с каналами - это не базовая функция. Чтобы использовать каналы, необходимо установить и загрузить пакет magrittr (как правило, это делается при загрузке пакета tidyverse или dplyr, в которые он уже включен). Вы можете почитать детали об использовании каналов в документации по magrittr.
Обратите внимание, что как и в других командах R, каналы могут использоваться как для вывода результата, так и для сохранения/пересохранения объекта, в зависимости от того, используется ли оператор присваивания <-. См. ниже оба варианта:
# Создание или перезапись объекта, определение его как подсчета совокупного количества по возрастной категории (без печати)
linelist_summary <- linelist %>%
count(age_cat)# Печать таблицы с подсчетом совокупного количества на консоли, но без сохранения
linelist %>%
count(age_cat) age_cat n
1 0-4 1095
2 5-9 1095
3 10-14 941
4 15-19 743
5 20-29 1073
6 30-49 754
7 50-69 95
8 70+ 6
9 <NA> 86%<>%
Это “оператор присвоения” из пакета magrittr, который передает объект по каналу вперед и также переопределяет объект. Он должен быть первым оператором канала в цепочке. Это краткий вариант. Две команды, указанные ниже, являются эквивалентными:
linelist <- linelist %>%
filter(age > 50)
linelist %<>% filter(age > 50)Определение промежуточных объектов
Данный подход к изменению объектов/датафреймов может быть более подходящим, если:
- Вам нужно работать с несколькими объектами
- Существуют важные промежуточные шаги, которые требуют отдельных названий объектов
Риски:
- Создание новых объектов для каждого шага означает создание большого количества объектов. Вы можете перепутать объекты, не заметив этого!
- Присвоение названий всем объектам может вас запутать
- Может быть сложно заметить ошибки
Можно называть каждый промежуточный объект, переписывать изначальный объект, либо комбинировать все функции. Во всех подходах есть свои риски.
Ниже представлен тот же выдуманный пример с “пирогом”, но с использованием другого стиля:
# выдуманный пример выпечки пирога другим методом (определение промежуточных объектов)
batter_1 <- left_join(flour, eggs)
batter_2 <- left_join(batter_1, oil)
batter_3 <- left_join(batter_2, water)
batter_4 <- mix_together(object = batter_3, utensil = spoon, minutes = 2)
cake <- bake(batter_4, degrees = 350, system = "fahrenheit", minutes = 35)
cake <- let_cool(cake)Объединение всех функций - это будет сложно читать:
# пример объединения/комбинирования нескольких функций - сложно читать
cake <- let_cool(bake(mix_together(batter_3, utensil = spoon, minutes = 2), degrees = 350, system = "fahrenheit", minutes = 35))7.2 Ключевые операторы и функции
В данном разделе рассматриваются операторы в R, такие как:
- Операторы определения
- Операторы отношения (меньше,чем, равно..)
- Логические операторы (и, или…)
- Работа с отсутствующими значениями
- Математические операторы и функции (+/-, >, sum(), median(), …)
- Оператор
%in%
Операторы присвоения
<-
Базовый оператор присвоения в R - это <-. Например, object_name <- value.
Этот оператор+ присвоения можно также записать как =. Мы советуем для R использовать <-.
Мы также советуем до и по=сле таких операторов ставить пробелы для улучшения читаемости.
<<-
Написание функций или использование R интерактивным образом со скриптами с источниками может потребовать использования следующего оператора присвоения <<- (из базового R). Данный оператор используется, чтобы определить объект в более высокой ‘родительской’ среде R. См. онлайн материал.
%<>%
Это “оператор присвоения” из пакета magrittr, который передает объект вперед и также переопределяет объект. Он должен быть первым оператором канала в цепочке. Это краткая записаь, как показано ниже в двух равнозначных примерах:
linelist <- linelist %>%
mutate(age_months = age_years * 12)Пример выше эквивалентен следующему примеру:
linelist %<>% mutate(age_months = age_years * 12)%<+%
Этот оператор используется для добавления данных в филогенетические деревья в пакете ggtree. См. страницу Филогенетические деревья или данный онлайн справочник.
Операторы отношения и логические операторы
Операторы отношения сравнивают значения и часто используются при определении новых переменных и поднаборов данных. Ниже приведены часто используемые операторы отношений в R:
Значение | Оператор | Пример ==========================+============+============== Равно | == | "A" == "a"
|
Пример результата | ========================================================================================================================================================+ FALSE (поскольку R чувствителен к регистру) Обратите внимание, что == (двойное равно) отличается от = (одинарного равно), которое работает как оператор присвоения <- | |
|||
| Не равно | != |
2 != 0 |
TRUE |
|
| Больше, чем | > |
4 > 2 |
TRUE |
|
| Меньше, чем | < |
4 < 2 |
FALSE |
|
| Больше или равно | >= |
6 >= 4 |
TRUE |
|
| Меньше или равно | <= |
6 <= 4 |
FALSE |
|
| Значение отсутствует | is.na() |
is.na(7) |
FALSE (см. страницу Отсутствующие данные) |
|
| Значение не отсутствует | !is.na() |
!is.na(7) |
TRUE |
Логические операторы, такие как И и ИЛИ, часто используются для связи операторов отношения и создания более сложных критериев. Сложные утверждения могут потребовать скобок ( ) для группирования и определения порядка применения.
| Значение | Оператор |
|---|---|
| И | & |
| ИЛИ |
| (вертикальная черта) |
| Скобки |
( ) Для группировки критериев и уточнения порядка операций |
Например, ниже у нас есть построчный список с двумя переменными, которые мы хотим использовать для создания определения случая, hep_e_rdt, результат теста и other_cases_in_hh, которая скажет нам, есть ли другие случаи в домохозяйстве. Команда ниже использует функцию case_when(), чтобы создать новую переменную case_def, чтобы:
linelist_cleaned <- linelist %>%
mutate(case_def = case_when(
is.na(rdt_result) & is.na(other_case_in_home) ~ NA_character_,
rdt_result == "Positive" ~ "Confirmed",
rdt_result != "Positive" & other_cases_in_home == "Yes" ~ "Probable",
TRUE ~ "Suspected"
))| Критерии в примере выше | Результат в новой переменной “case_def” |
|---|---|
Если значения переменной rdt_result и other_cases_in_home отсутствуют |
NA (отсутствует) |
Если значение в rdt_result “Positive” (положительный) |
“Confirmed” (подтвержденный) |
Если значение в rdt_result НЕ “Positive” И значение в other_cases_in_home “Yes” (да) |
“Probable” (вероятный) |
| Если один из указанных выше критериев не выполнен | “Suspected” (подозрительный) |
Обратите внимание, что R чувствителен к регистру, так что “Positive” отличается от “positive”…
Отсутствующие значения
В R отсутствующие значения представлены особым значением NA (“зарезервированное” значение) (заглавные буквы N и A - без кавычек). Если вы импортируете данные, которые кодируют отсутствующие значения иным образом (например, 99, “Missing”, или .), вам, возможно, нужно перекодировать эти значения в NA. То, как это делать, рассмотрено на странице Импорт и экспорт.
To test whether a value is NA, use the special function is.na(), which returns TRUE or FALSE.
rdt_result <- c("Positive", "Suspected", "Positive", NA) # два положительных случая, один подозрительный и один неизвестный
is.na(rdt_result) # Тестирует, является ли значение rdt_result NA[1] FALSE FALSE FALSE TRUEБолее подробно почитать об отсутствующих, бесконечных, NULL и невозможных значениях можно на странице [Отсутствующие данные]. Узнайте, как конвертировать отсутствующие значения при импорте данных на странице Импорт и экспорт.
Математика и статистика
Все операторы и функции на этой странице автоматически доступны в базовом R.
Математические операторы
Их часто использует для сложения, деления, создания новых столбцов и т.п. Ниже представлены часто используемые математические операторы в R. Наличие пробелов перед и после операторов не имеет значения.
| Цель | Пример в R |
|---|---|
| сложение | 2 + 3 |
| вычитание | 2 - 3 |
| умножение | 2 * 3 |
| деление | 30 / 5 |
| возведение в степень | 2^3 |
| порядок операций | ( ) |
Математические функции
| Цель | Функция |
|---|---|
| округление | round(x, digits = n) |
| округление | janitor::round_half_up(x, digits = n) |
| округление большее | ceiling(x) |
| округление меньшее | floor(x) |
| абсолютное значение | abs(x) |
| квадратный корень | sqrt(x) |
| экспонента | exponent(x) |
| натур.логарифм | log(x) |
| log по основанию 10 | log10(x) |
| log по основанию 2 | log2(x) |
Примечание: для round() параметр digits = указывает количество знаков после запятой. Используйте signif() для округления чисел до значимой цифры.
Научная запись
Вероятность использования научной записи зависит от значения опции scipen.
Из документации по ?options: scipen - штраф, который применяется при принятии решений о выводе числовых значений в фиксированной или научной записи. Положительные значения склоняются к фиксированной записи, а отрицательные - к научной записи: фиксированная запись будет предпочтительной, кроме случаев, когда она шире, чем количество знаков ‘scipen’.
Если опция установлена на маленькое число (например, 0), она будет “включена” всегда. Чтобы “отключить” научную запись в сессии R, установите параметр на очень большое число, например:
# выключение научной записи
options(scipen=999)Округление
ВНИМАНИЕ: round() использует “банковское округление”, которое округляет в большую сторону от .5 только, если большее число четное. Используйте round_half_up() из пакета janitor для последовательного округления половин до ближайшего полного числа. См. данное объяснение
# используйте подходящую для вашей работы функцию округления
round(c(2.5, 3.5))[1] 2 4janitor::round_half_up(c(2.5, 3.5))[1] 3 4Статистические функции
ВНИМАНИЕ: Функции ниже по умолчанию будут включать отсутствующие значения в расчеты. Отсутствующие значения приведут к выводу NA, кроме случаев, когда уточнен аргумент na.rm = TRUE. Это можно кратко записать как na.rm = T.
| Задача | Функция |
|---|---|
| среднее | mean(x, na.rm=T) |
| медиана | median(x, na.rm=T) |
| стандартное отклонение | sd(x, na.rm=T) |
| квантили* | quantile(x, probs) |
| сумма | sum(x, na.rm=T) |
| минимальное значение | min(x, na.rm=T) |
| максимальное значение | max(x, na.rm=T) |
| диапазон числов.значений | range(x, na.rm=T) |
| сводные данные** | summary(x) |
Примечание:
-
*quantile():x- это числовой вектор для рассмотрения, аprobs =это числовой вектор с вероятностями от 0 до 1.0, например,c(0.5, 0.8, 0.85) -
**summary(): дает сводную информацию о числовом векторе, включая среднее значение, медиану и частые процентили
ВНИМАНИЕ: При указании вектора чисел для одной из указанных выше функций, не забудьте обернуть числа в c() .
# Если вы даете сырые числа функции, оберните их в c()
mean(1, 6, 12, 10, 5, 0) # !!! НЕПРАВИЛЬНО !!! [1] 1mean(c(1, 6, 12, 10, 5, 0)) # ПРАВИЛЬНО[1] 5.666667Другие полезные функции
| Задача | Функция | Пример |
|---|---|---|
| Создание последовательности | seq(from, to, by) | seq(1, 10, 2) |
| повторить x, n раз | rep(x, ntimes) |
rep(1:3, 2) or rep(c("a", "b", "c"), 3)
|
| разделить числовой вектор | cut(x, n) | cut(linelist$age, 5) |
| взять случайную выборку | sample(x, size) | sample(linelist$id, size = 5, replace = TRUE) |
%in%
Очень полезный оператор для сопоставления значений и быстрой оценки того, относится ли значение к вектору или датафрейму.
my_vector <- c("a", "b", "c", "d")"a" %in% my_vector[1] TRUE"h" %in% my_vector[1] FALSEЧтобы спросить, если значение не является %in% вектором, поставьте восклицательный знак (!) перед логическим утверждением:
# для отрицания, поставьте перед утверждением восклицательный знак
!"a" %in% my_vector[1] FALSE!"h" %in% my_vector[1] TRUE%in% полезен при использовании функции case_when() пакета dplyr. Вы можеет определить заранее вектор, затем ссылаться на него. Например:
affirmative <- c("1", "Yes", "YES", "yes", "y", "Y", "oui", "Oui", "Si")
linelist <- linelist %>%
mutate(child_hospitaled = case_when(
hospitalized %in% affirmative & age < 18 ~ "Hospitalized Child",
TRUE ~ "Not"))Примечание: Если вы хотите обнаружить частичную последовательность, например, используя функцию str_detect() из stringr, она не примет текстовый вектор, как c("1", "Yes", "yes", "y"). Вместо этого ей нужно задать обычное выражение - сжатую последовательность с черточками ИЛИ, например, “1|Yes|yes|y”. Например, str_detect(hospitalized, "1|Yes|yes|y"). См. страницу Текст и последовательности для получения дополнительной информации.
Мы можете конвертировать текстовый вектор в именованное обычное выражение с помощью следующей команды:
affirmative <- c("1", "Yes", "YES", "yes", "y", "Y", "oui", "Oui", "Si")
affirmative[1] "1" "Yes" "YES" "yes" "y" "Y" "oui" "Oui" "Si" # сжать до
affirmative_str_search <- paste0(affirmative, collapse = "|") # вариант с базовым R
affirmative_str_search <- str_c(affirmative, collapse = "|") # вариант с пакетом stringr
affirmative_str_search[1] "1|Yes|YES|yes|y|Y|oui|Oui|Si"7.3 Ошибки и предупреждения
Этот раздел объясняет:
- Разницу между ошибками и предупреждениями
- Общие советы по синтаксису для написания кода R
- Помощь в коде
Частые ошибки и предупреждения, а также советы по выявлению и решению проблем можно найти на странице Ошибки и справка.
Ошибки и предупреждения
При выполнении команды на консоли R могут появиться сообщения о предупреждениях или ошибках красным текстом.
Предупреждение означает, что R выполнил вашу команду, но системе пришлось предпринимать дополнительные шаги или она дала неожиданные выходные данные, о котором вам нужно знать.
Ошибка означает, что R не смог завершить выполнение вашей команды.
Ищите подсказки:
Сообщение об ошибке/предупреждении часто будет включать номер строки, в которой обнаружена проблема.
Если объект “is unknown” (неизвестен) или “not found” (не найден), возможно, вы допустили орфографическую ошибку, забыли вызвать пакет из библиотеки library(), либо забыли повторно выполнить скрипт после внесения изменений.
Если ничего не помогает, скопируйте сообщение об ошибке в Google вместе с ключевыми словами - возможно, кто-то уже решил эту проблему!
Общие советы по синтаксису
Несколько пунктов, которые нужно запомнить при написании команд в R, чтобы избежать ошибок и предупреждений:
- Всегда закрывайте скобки - совет: посчитайте количество открывающих “(” и закрывающих скобок “)” для каждого блока кода
- Избегайте пробелов в названиях столбцов и объектов. Вместо этого используйте нижнее подчеркивание ( _ ) или точки ( . )
- Отслеживайте и помните, что нужно отделять аргументы функций запятыми
- R чувствителен к регистру, значит,
Variable_Aотличается отvariable_A
Помощь в коде
Любой скрипт (RMarkdown или другой) будет давать подсказки, если вы допустили ошибку. Например, если вы забыли написать запятую там, где она нужна, либо закрыть скобку, RStudio поставит флажок на этой строке скрипта, чтобы вас предупредить.