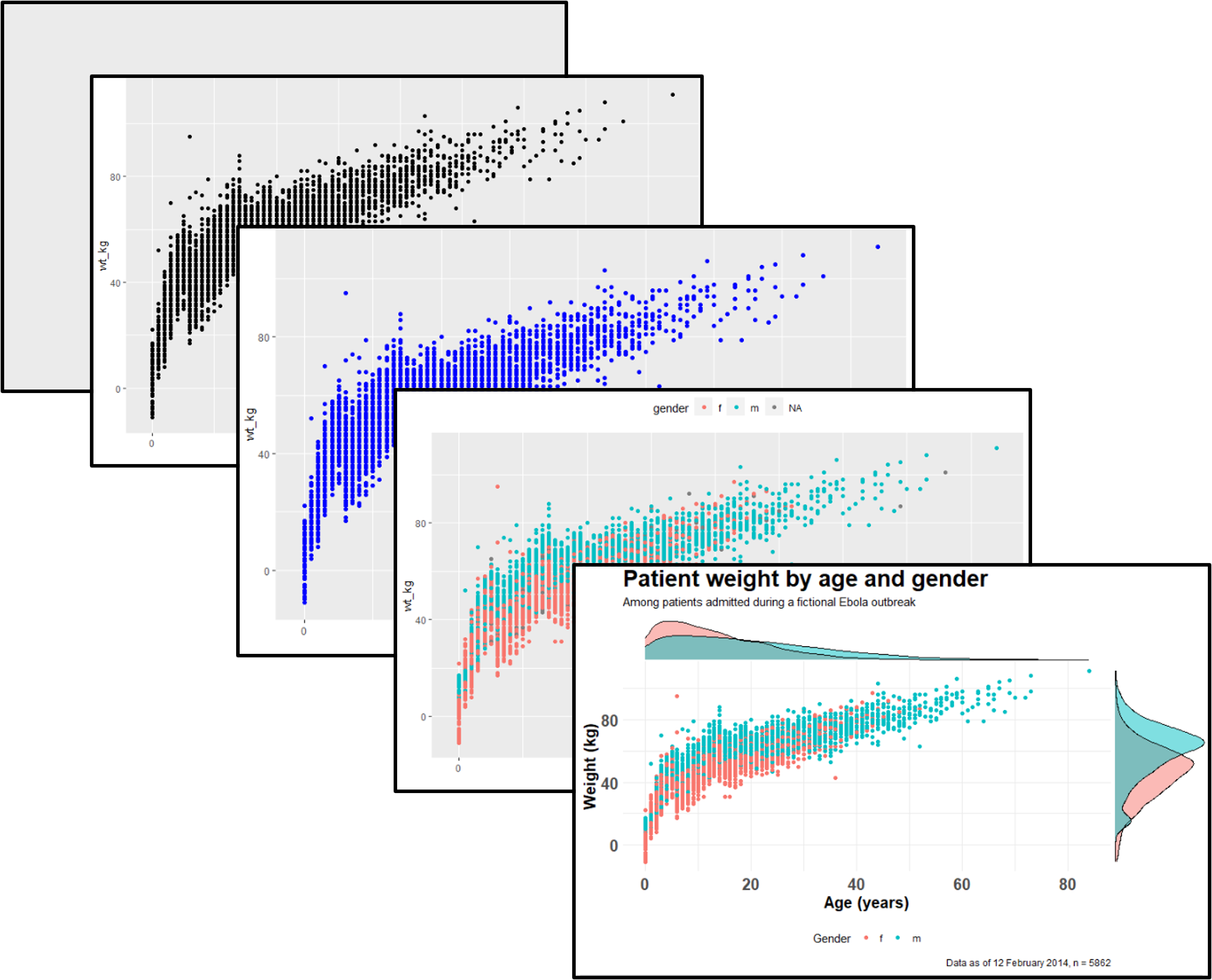
30 O básico do ggplot
O ggplot2 é o pacote R mais popular de visualização de dados. Sua função ggplot() está no centro deste pacote, e toda esta abordagem é conhecida coloquialmente como “ggplot” com as imagens resultantes às vezes carinhosamente chamadas de “ggplots”. O “gg” nestes nomes reflete a “gramática de gráficos” utilizados para construir as figuras. O ggplot2 beneficia-se de uma grande variedade de pacotes R suplementares que melhoram ainda mais sua funcionalidade.
A sintaxe é significativamente diferente dos gráficos gerados pelo R base*, e tem uma curva de aprendizado associada a ela. A utilização do ggplot2 geralmente exige que o usuário formate seus dados de uma forma altamente compatível com o “tidyverse”, o que em última análise torna a utilização conjunta destes pacotes muito eficaz.
Nesta página cobriremos os fundamentos da criação de gráficos com o pacote ggplot2. Veja a página Dicas para o ggplot para sugestões e técnicas avançadas para tornar seus gráficos realmente bonitos.
Há vários tutoriais completos de ggplot2 disponíveis na seção de recursos. Você também pode baixar esta cheat sheet (colinha) de visualização de dados do site do RStudio. Se você quiser inspiração para formas de visualizar criativamente seus dados, sugerimos que você revise sites como o galeria de gráficos R e Data-to-viz.
30.1 Preparação
Carregar pacotes
Este trecho de código mostra o carregamento dos pacotes necessários para as análises. Neste manual, enfatizamos p_load() de pacman, que instala o pacote se necessário e o carrega para utilização. Você também pode carregar os pacotes instalados com library() do R base*. Veja a página em Introdução ao R para mais informações sobre os pacotes R.
pacman::p_load(
tidyverse, # inclui ggplot2 e outras ferramentas de manipular dados
janitor, # limpeza de dados
ggforce, # extensão ggplot
rio, # importar/exportar
here, # localizador de arquivos
stringr # trabalhando com caracteres
)Importar datos
Importamos o conjunto de dados de casos de uma epidemia simulada de Ebola. Se você quiser acompanhar, clique para baixar a linelist “limpa” (como arquivo .rds). Importe seus dados com a função import() do pacote rio (ele aceita muitos tipos de arquivos como .xlsx, .rds, .csv - veja a página Importar and exportar para detalhes).
linelist <- rio::import("linelist_cleaned.rds")As primeiras 50 linhas da linelist são exibidas abaixo. Vamos nos concentrar nas variáveis contínuas age, wt_kg (peso em quilos), ct_blood (valores de CT) e days_onset_hosp (diferença entre data de início e hospitalização).
Limpeza geral
Ao preparar os dados para traçar o gráfico, é melhor fazer com que os dados adiram aos padrões de dados “arrumados” (do inglês tidy) na medida do possível. Como conseguir isto é explicado com mais detalhes nas páginas de gerenciamento de dados deste manual, tais como Dados de limpeza e principais funções.
Algumas maneiras simples de prepararmos nossos dados para torná-los melhores para a visualização podem incluir tornar o conteúdo dos dados melhor para exibição - o que não necessariamente equivale a melhor para a manipulação de dados. Por exemplo:
Substituir os valores
NAem uma coluna do tipo caracteres pela string “Desconhecido”.Considerar converter a coluna para classe fator para que seus valores tenham níveis em uma ordem específica.
Limpar algumas colunas para que os valores adequados à manipulações (“data friendly”), tais como valores que possuam sublinhado (“underline”), por exemplo, sejam alterados para texto normal ou padrão título (ver Caracteres e strings)
Aqui estão alguns exemplos disso em ação.
#faça uma versão visualizaçãi das colunas com nomes mais amigáveis
linelist <- linelist %>%
mutate(
gender_disp = case_when(gender == "m" ~ "Male", # m para Male
gender == "f" ~ "Female", # f para Femimino,
is.na(gender) ~ "Desconhecido"), # NA para Desconhecido
outcome_disp = replace_na(outcome, "Desconhecido") # substituir na por "Desconhecido"
)Pivoteamento para “mais longo”
Por uma questão de estrutura de dados, para ggplot2 muitas vezes também queremos pivotar nossos dados para formatos mais longos. Leia mais sobre isto na página em Pivoteando dados.
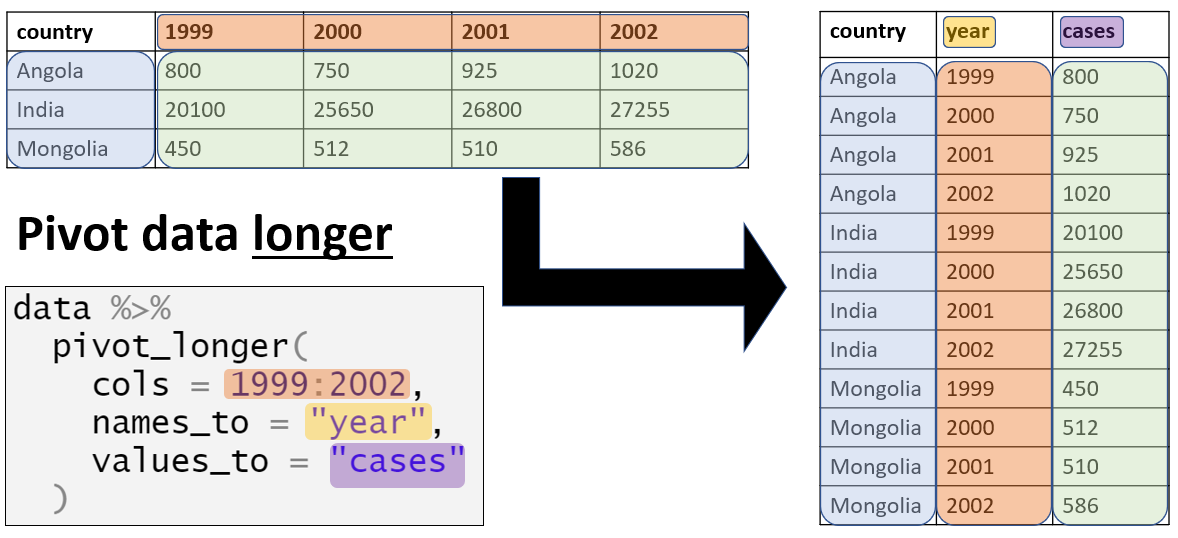
Por exemplo, digamos que queremos fazer um gráfico de dados que estão em um formato “largo”, como para cada caso na linelist e seus sintomas. Abaixo criamos uma mini-linelist chamada symptoms_data que contém apenas as colunas case_id e sintomas.
symptoms_data <- linelist %>%
rename(tosse=cough,
febre=fever,
vômito=vomit,
dores=aches,
calafrio=chills) %>% #traduzindo
select(c(case_id, febre, calafrio, tosse, dores, vômito)) Veja como são as primeiras 50 linhas desta mini-linelist - veja como elas são formatadas de forma “larga” com cada sintoma como uma coluna:
Se quisermos traçar um gráfico com o número de casos com sintomas específicos, estamos limitados pelo fato de que cada sintoma é uma coluna específica. Entretanto, podemos pivotar as colunas de sintomas para um formato mais longo como este:
symptoms_data_long <- symptoms_data %>% # comece com a "mini" linelist chamada symptoms_data
pivot_longer(
cols = -case_id, # pivote todas as colunas exceto case_id
names_to = "nome_sintoma", # dê o nome para a nova coluna que contém os sintomas
values_to = "sintoma_esta_presente") %>% # dê o nome para a coluna que diz se o sintoma está presente
mutate(sintoma_esta_presente = replace_na(sintoma_esta_presente, "desconhecido")) # converte NA para "desconhecido"Aqui estão as primeiras 50 linhas. Observe que o caso tem 5 fileiras - uma para cada sintoma possível. As novas colunas nome_sintoma e sintoma_esta_presente são o resultado do pivoteamento. Note que este formato pode não ser muito útil para outras operações, mas é útil para a criação do gráfico.
30.2 Básico do ggplot
“Gramática dos gráficos” - ggplot2
A criação de gráficos com o ggplot2 é baseada na “adição” de camadas de gráficos e de design uns sobre os outros, com cada comando adicionado aos anteriores com um símbolo de mais (+). O resultado é um objeto do tipo gráfico com várias camadas que pode ser salvo, modificado, impresso, exportado, etc.
Os objetos de ggplot podem ser altamente complexos, mas a ordem básica das camadas geralmente será assim:
- Comece com o comando de base
ggplot()- isto “abre” o ggplot e permite que funções subseqüentes sejam adicionadas com+. Tipicamente, o conjunto de dados também é especificado neste comando
- Adicionar camadas “geom” - estas funções visualizam os dados como geometrias (formas), por exemplo, como um gráfico de barras, gráfico de linhas, gráfico de dispersão, histograma (ou uma combinação!). Todas estas funções começam com
geom_como um prefixo.
- Adicione elementos de desenho ao gráfico, como etiquetas de eixos, título, fontes, tamanhos, esquemas de cores, legendas ou rotação de eixos.
Um exemplo simples de código esqueleto é o seguinte. Vamos explicar cada componente nas seções abaixo.
# plote os dados das colunas do objeto my_data como pontos vermelhos
ggplot(data = my_data)+ # use a base de dados "my_data"
geom_point( # adicione uma camada de pontos
mapping = aes(x = col1, y = col2), # mapeie as colunas para os eixos
color = "red")+ # outras especificações para o geom
labs()+ # aqui você pode adicionar títulos, rótulos dos eixos, etc.
theme() # aqui você pode ajustar a cor, fonte, tamanho, de elementos que não são orindos dos dados (eixo, título, etc.)
30.3 ggplot()
O comando de abertura de qualquer gráfico ggplot2 é ggplot(). Este comando simplesmente cria uma tela em branco sobre a qual se pode adicionar camadas. Ele “abre” o caminho para que outras camadas sejam adicionadas com um símbolo +.
Normalmente, o comando ggplot() inclui o dados = argumento para o gráfico. Isto define o conjunto de dados padrão a ser utilizado para as camadas subsequentes do gráfico.
Este comando terminará com um + após seus parênteses de fechamento. Isto deixa o comando “aberto”. O ggplot só será executado/aparecerá quando o comando completo incluir uma camada final sem um + no final.
# Isso irá criar um gráfco que é um painel em branco
ggplot(data = linelist)30.4 Geoms
Uma tela em branco certamente não é suficiente - precisamos criar geometrias (formas) a partir de nossos dados (por exemplo, gráficos de barra, histogramas, gráficos de dispersão, gráficos de caixa).
Isto é feito adicionando camadas “geoms” ao comando inicial ggplot(). Há muitas funções do ggplot2 que criam “geoms”. Cada uma destas funções começa com “geom_”, portanto, vamos nos referir a elas genericamente como geom_XXXX(). Há mais de 40 geoms em ggplot2 e muitos outros criados por fãs e contribuidores. Veja-os na galeria ggplot2. Alguns geoms comuns estão listados abaixo:
- Histogramas -
geom_histogram()
- Gráficos de barras -
geom_bar()ougeom_col()(veja “Bar plot” seção)
- Diagrama de caixas -
geom_boxplot()
- Pontos (por exemplo, gráficos de dispersão) -
geom_point()
- Gráficos de linhas -
geom_line()ougeom_path()
- Linhas de tendência -
geom_smooth()
Em um gráfico você pode exibir um ou vários geoms. Cada um é adicionado aos comandos anteriores ggplot2 com um +, e eles são plotados sequencialmente de forma que os geoms posteriores sejam plotados sobre os anteriores.
30.5 Mapeando dados ao gráfico
A maioria das “funções geom” devem ser informadas do que usar para criar suas formas - portanto, você deve dizer-lhes como devem mapear (atribuir) colunas em seus dados aos componentes do gráfico como os eixos, cores das formas, tamanhos das formas, etc. Para a maioria dos geoms, os componentes essenciais que devem ser mapeados para colunas nos dados são o eixo x, e (se necessário) o eixo y.
Este “mapeamento” ocorre com o argumento mapping =. Os mapeamentos que você fornece ao mapping devem ser envolvidos na função aes(), assim você escreveria algo como mapping = aes(x = col1, y = col2), como mostrado abaixo.
Abaixo, no comando ggplot(), os dados são definidos como o caso linelist. No argumento mapping = aes() a coluna age é mapeada para o eixo x, e a coluna wt_kg é mapeada para o eixo y.
Depois de um +, os comandos de plotagem continuam. Uma forma é criada com a função “geom” geom_point(). Este geom herda os mapeamentos do comando ggplot() anterior - ele conhece as atribuições eixo-coluna e procede para visualizar essas relações como pontos na área do gráfico.
ggplot(data = linelist, mapping = aes(x = age, y = wt_kg))+
geom_point()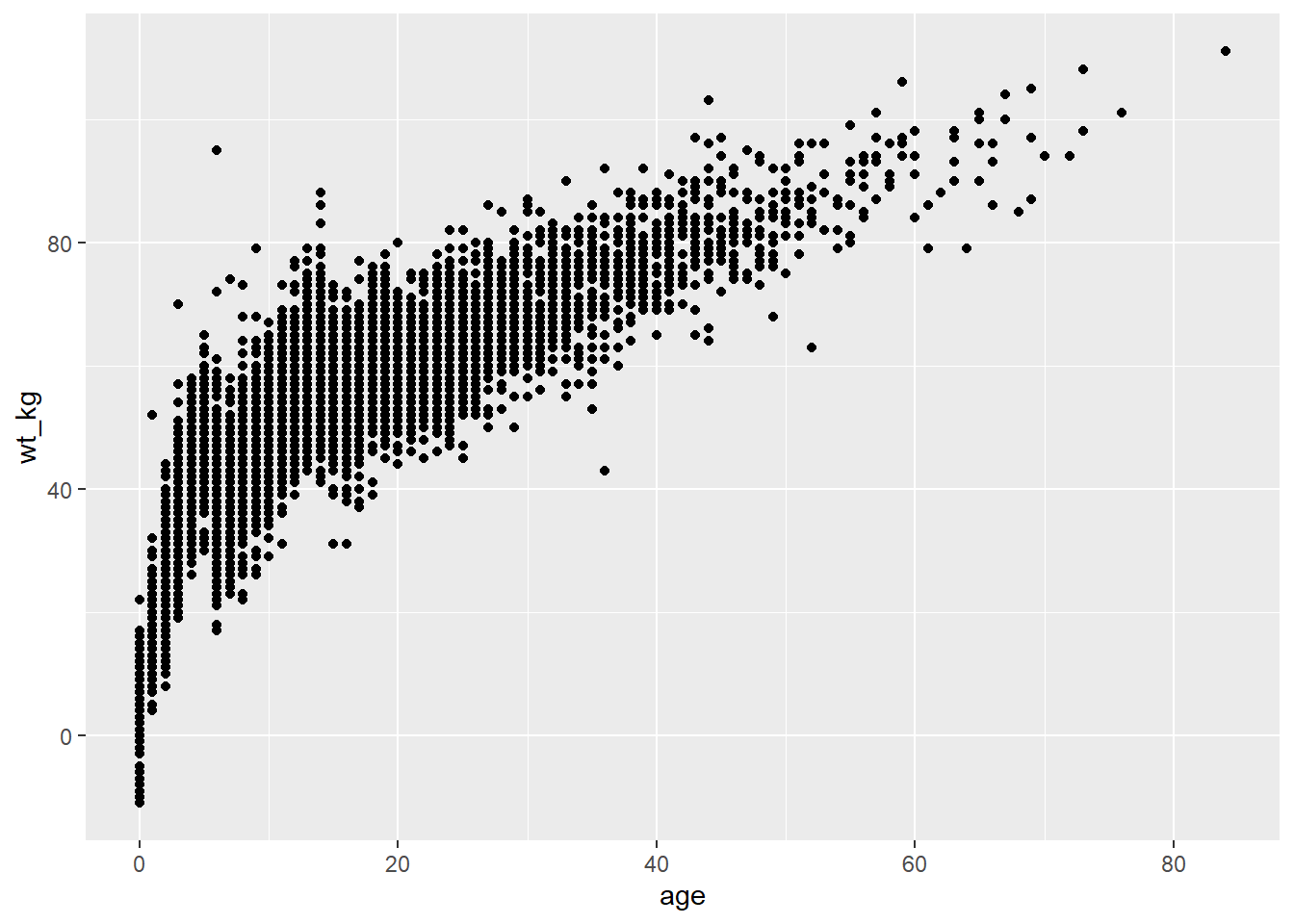
# o nome dos eixos fica automaticamente com o nome da variável na base
# que está em inglês. É possível traduzir na base ou usando a camada
# labs() para escrever o nome dos eixos como se querComo outro exemplo, os seguintes comandos utilizam os mesmos dados, um mapeamento um pouco diferente e um geom diferente. A função geom_histogram() requer apenas uma coluna mapeada para o eixo x, pois as contagens do eixo y são geradas automaticamente.
ggplot(data = linelist, mapping = aes(x = age))+
geom_histogram()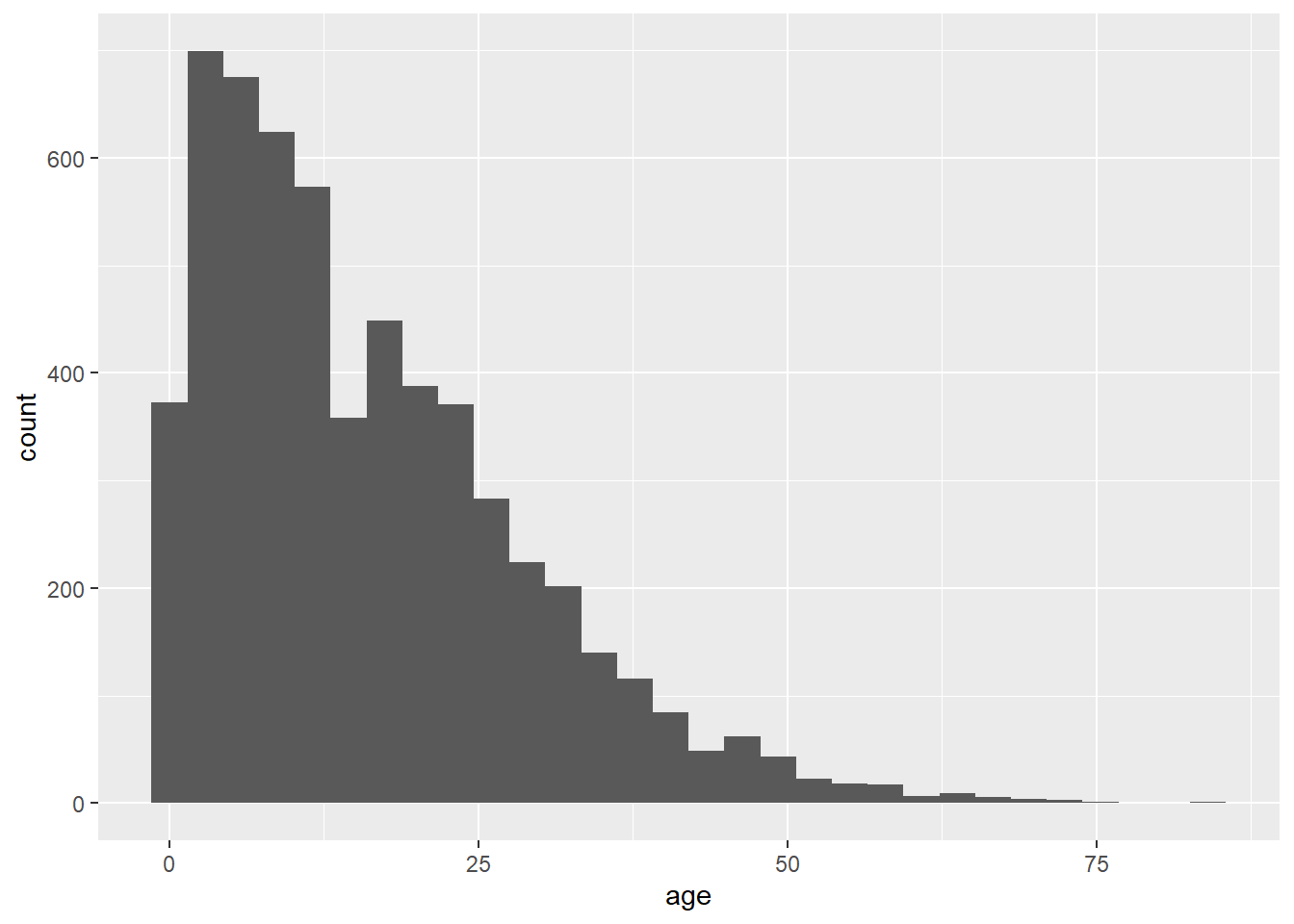
As estéticas do gráfico
Na terminologia ggplot, uma “estética” do gráfico tem um significado específico. Ela se refere a uma propriedade visual de dados plotados. Note que “estético” aqui se refere aos dados que estão sendo plotados em geometrias/formas - não ao display ao redor, como títulos, etiquetas de eixos, cor de fundo, que você pode associar com a palavra “estética”. No ggplot, esses detalhes são chamados de “themes” (temas) e são ajustados dentro de um comando theme() (veja esta seção).
Portanto, os objetos aesthetics podem ser cores, tamanhos, transparências, posição, etc. dos dados traçados. Nem todos os geoms terão as mesmas opções de aesthetics, mas muitos podem ser usados pela maioria dos geoms. Aqui estão alguns exemplos:
shape =Mostra um ponto degeom_point()como um círculo, estrela, triângulo…fill =A cor de preenchimento (ex. de uma barra ou boxplot)color =A linha exterior de uma barra ou boxplot, ou a cor do ponto se usar ogeom_point()size =tamanho (ex. grossura da linha, tamanho do ponto)alpha =Transparencia (1 = opaco, 0 = invisível)binwidth =Largura das classes do histogramawidth =Largura das barras do gráfico de barraslinetype =Tipo de linha (ex. sólida, tracejada, pontilhada)
A esses objetos do gráfico podem ser atribuídos valores de duas maneiras:
- Atribuindo um valor estático (por exemplo,
color = "blue") a ser aplicado em todas as observações plotadas
- Atribuído a uma coluna de dados (por exemplo, “color = hospital”) de tal forma que a exibição de cada observação depende de seu valor nessa coluna
Configurar para um valor estático
Se você quiser que a estética do objeto do gráfico seja estática, ou seja - para ser a mesma para cada observação nos dados, você escreve sua atribuição dentro do geom desejado mas fora de qualquer mapping = aes(). Essas atribuições poderiam ser size = 1 ou color = "blue". Aqui estão dois exemplos:
No primeiro exemplo, o
mapping = aes()está no comandoggplot()e os eixos são mapeados para as colunas de idade e peso nos dados. A estética do gráficocolor =,size =, ealpha =(transparência) são atribuídos a valores estáticos. Para maior clareza, isto é feito na funçãogeom_point(), pois você pode adicionar outras geometrias posteriormente que levariam valores diferentes.No segundo exemplo, o histograma requer apenas o eixo x mapeado para uma coluna. O histograma
binwidth =,color =,fill =(cor de preenchimento), ealpha =são novamente definidos dentro do geom para valores estáticos.
# gráfico de dispersão
ggplot(data = linelist, mapping = aes(x = age, y = wt_kg))+ # configurar mapeamento dos dados e eixos
geom_point(color = "darkgreen", size = 0.5, alpha = 0.2) # configurar a estética estática dos pontos
# histograma
ggplot(data = linelist, mapping = aes(x = age))+ # configurar mapeamento dos dados e eixos
geom_histogram( # mostra o histograma
binwidth = 7, # largura das classes
color = "red", # cor da linha da classe
fill = "blue", # cor de preenchimento da barra
alpha = 0.1) # transparência da barra
Responsivo a valores de uma coluna
A alternativa é mapear os argumentos da estética de um gráfico a uma coluna (variável) do seus dados. Nesta abordagem, a exibição deste aesthetics dependerá do valor desta observação naquela coluna dos dados. Se os valores da coluna forem contínuos, a escala de exibição (legenda) para aquele aesthetics será contínua. Se os valores da coluna forem discretos, a legenda exibirá cada valor e os dados plotados aparecerão “agrupados” de forma distinta (leia mais na seção agrupamento desta página).
Para conseguir isso, você mapeia esse aesthetics do gráfico para um nome de coluna (não entre aspas). Isto deve ser feito *em uma função mapping = aes() (nota: há vários lugares no código que você pode fazer estas atribuições de mapeamento, como discutido abaixo)).
Dois exemplos estão abaixo.
- No primeiro exemplo, a aesthetics
color =(de cada ponto) é mapeada para a colunaage- e uma escala de cores apareceu na legenda! Por enquanto, basta observar que a escala existe - mostraremos como modificá-la em seções posteriores.
- No segundo exemplo, duas novas aesthetics do gráfico também são mapeados para colunas (
color =esize =), enquanto a aesthetics do gráficoshape =ealpha =são mapeados para valores estáticos fora de qualquer funçãomapping = aes().
# gráfico de dispersão
ggplot(data = linelist, # escolha os dados
mapping = aes( # mapeie as aesthetics para coluna de valores
x = age, # mapeie o eixo x para idade (coluna age)
y = wt_kg, # mapeie o eixo y para peso (wt_kg)
color = age) # mapeie a cor segundo a idade
)+
geom_point() # mostre como pontos
# gráfico de dispersão
ggplot(data = linelist, # escolha os dados
mapping = aes( # mapeie as aesthetics para coluna de valores
x = age, # mapeie o eixo x para idade (coluna age)
y = wt_kg, # mapeie o eixo y para peso (wt_kg)
color = age, # mapeie a cor segundo a idade
size = age))+ # mapeie o tamanho segundo a idade
geom_point( # mostre como pontos
shape = "diamond", # pontos como losangos (diamantes)
alpha = 0.3) # transparência do ponto a 30%
Nota: Os argumentos referentes aos eixos são sempre atribuídos a colunas dos dados (não a valores estáticos), e isto é sempre feito dentro de mapping = aes().
Torna-se importante acompanhar as camadas e a aesthetics de seus gráficos à medida que vão ficando mais complexos - por exemplo, gráficos com múltiplos geoms. No exemplo abaixo, a aesthetic size = é atribuída duas vezes - uma para geom_point() e outra para geom_smooth() - ambas as vezes como um valor estático.
ggplot(data = linelist,
mapping = aes( # mapeia a aesthetics para as colunas
x = age,
y = wt_kg,
color = age_years)
) +
geom_point( # addiciona pontos para cada linha de dados
size = 1,
alpha = 0.5) +
geom_smooth( # adiciona uma linha de tendência
method = "lm", # com um método linear
size = 2) # tamanho (grossura da linha) de 2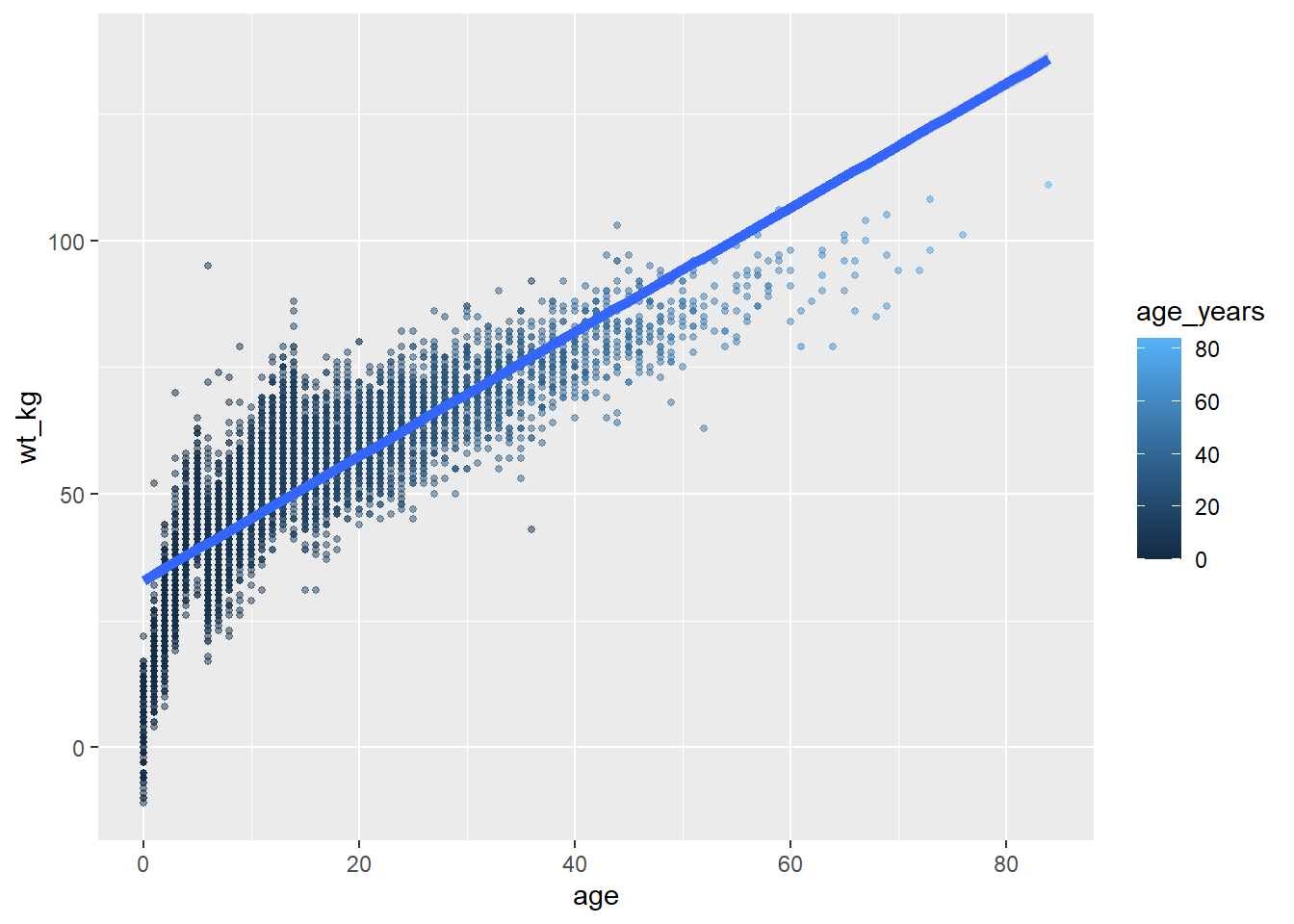
Onde incluir os atributos de mapeamento
O mapeamento das aesthetics dentro de mapping = aes() pode ser escrito em vários lugares em seus comandos para criar o gráfico, podendo até mesmo ser escrito mais de uma vez. Isto pode ser escrito no comando superior ggplot(), e/ou para cada geom individual abaixo. As nuances incluem:
- As atribuições de mapeamento feitas no primeiro comando
ggplot()serão herdadas como padrão em qualquer geom abaixo, da mesma forma comox =ey =são herdadas - Outros mapeamentos feitos dentro de um geom se aplicam somente a esse geom
Da mesma forma, o parâmetro data = (do inglês dados) especificado no primeiro comando ggplot() será aplicado por padrão a qualquer geom abaixo, mas você também poderia especificar dados novos para cada geom (mas isto é mais complicado).
Assim, cada um dos seguintes comandos irá criar o mesmo gráfico:
# Esses comandos irão criar o mesmo gráfico
ggplot(data = linelist, mapping = aes(x = age))+
geom_histogram()
ggplot(data = linelist)+
geom_histogram(mapping = aes(x = age))
ggplot()+
geom_histogram(data = linelist, mapping = aes(x = age))Grupos
Você pode facilmente agrupar os dados e “plotar por grupo”. Na verdade, você já fez isso!
Atribua a coluna de “agrupamento” à aesthetic apropriada do gráfico, dentro de um mapping = aes(). Acima, demonstramos isso utilizando valores contínuos quando atribuímos o ponto size = à coluna age (idade). Entretanto, isto funciona da mesma forma para colunas discretas/categóricas.
Por exemplo, se você quiser que os pontos sejam exibidos por gênero, você definiria mapping = aes(color = gender). Uma legenda aparece automaticamente. Esta atribuição pode ser feita dentro do comando mapping = aes() no ggplot() do topo (e ser herdada pelo geom), ou pode ser definida em um mapping = aes() separado dentro do geom. Ambas as abordagens são mostradas abaixo:
ggplot(data = linelist,
mapping = aes(x = age, y = wt_kg, color = gender))+
geom_point(alpha = 0.5)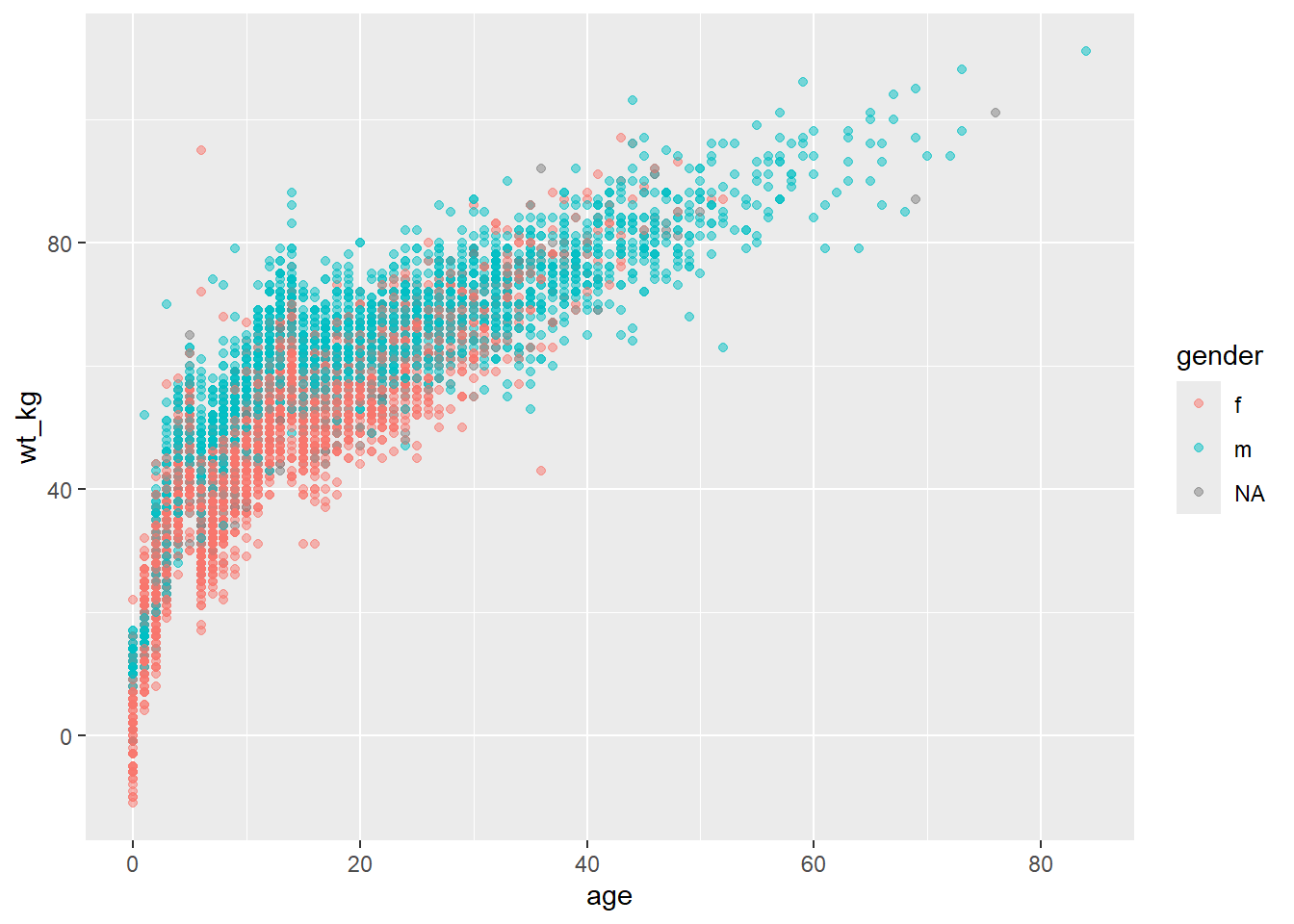
# Este código alternativo produz o mesmo gráfico
ggplot(data = linelist,
mapping = aes(x = age, y = wt_kg))+
geom_point(
mapping = aes(color = gender),
alpha = 0.5)Observe que, dependendo do geom, será necessário utilizar argumentos diferentes para agrupar os dados. Para geom_point() você provavelmente utilizará color =, shape = ou size =. Enquanto para geom_bar() é mais provável que você utilize fill =. Isto depende apenas do geom e do tipo de aesthetic do gráfico que você deseja usar para refletir os agrupamentos.
Para sua informação - a forma mais básica de agrupar os dados é utilizando apenas o argumento group = dentro do mapping = aes(). Entretanto, isto por si só não mudará as cores, o preenchimento ou as formas. Tampouco criará uma legenda. No entanto, os dados são agrupados, de modo que as exibições estatísticas poderão ser afetadas.
Para ajustar a ordem dos grupos em um gráfico, veja a página Dicas para o ggplot ou a página em Fatores. Há muitos exemplos de gráficos agrupados nas seções abaixo sobre a plotagem de dados contínuos e categóricos.
30.6 Facetas / Pequenos-Múltiplos
Facetas, ou “pequenos-múltiplos”, são usadas para dividir uma parcela em uma figura de vários painéis, com um painel (“faceta”) por grupo de dados. O mesmo tipo de gráfico é criado várias vezes, cada um usando um subgrupo do mesmo conjunto de dados.
O Facetamento (Faceting) é uma funcionalidade que vem com ggplot2, portanto as legendas e eixos dos “painéis” de faceta são automaticamente alinhados. Há outros pacotes discutidos na página Dicas para o ggplot que são usados para combinar gráficos completamente diferentes (cowplot e patchwork) em uma única figura.
O facetamento é feito com uma das seguintes funções ggplot2:
-
facet_wrap()Para mostrar um painel diferente para cada nível de uma variável única. Um exemplo disso poderia ser mostrar uma curva epidêmica diferente para cada hospital de uma região. As facetas são ordenadas alfabeticamente, a menos que a variável seja um fator com outra ordenação definida.
- Você pode invocar certas opções para determinar o layout das facetas, por exemplo
nrow = 1ouncol = 1para controlar o número de linhas ou colunas dentro das quais as facetas estão dispostas.
-
facet_grid()Isto é utilizado quando se deseja trazer uma segunda variável para a disposição das facetas. Aqui cada painel de uma “grade” (grid) mostra a interseção entre os valores em duas colunas. Por exemplo, curvas epidêmicas para cada combinação hospital-idade com hospitais ao longo do topo (colunas) e faixas etárias ao longo dos lados (linhas).
- “nrow” e “ncol” não são relevantes, pois os subgrupos são apresentados em um grid
Cada uma destas funções aceita uma sintaxe de fórmula para especificar a(s) coluna(s) de faceta(s). Ambas aceitam até duas colunas, uma de cada lado de um til `~’.
Para
facet_wrap()na maioria das vezes você escreverá apenas uma coluna precedida por um til~comofacet_wrap(~hospital). Entretanto, você pode escrever duas colunasfacet_wrap(outcome ~ hospital)- cada combinação única será exibida em um painel separado, mas não serão dispostas em um grid. Os cabeçalhos mostrarão termos combinados e estes não terão uma lógica específica para as colunas vs. linhas. Se você estiver fornecendo apenas uma variável facetada, um ponto.é utilizado como um espaço reservado no outro lado da fórmula - veja os exemplos de código.Para
facet_grid()você também pode especificar uma ou duas colunas para a fórmula (gridlinhas ~ colunas). Se você quiser especificar apenas uma, você pode colocar um ponto.no outro lado do til comofacet_grid(. ~ hospital)oufacet_grid(hospital ~ .).
As facetas podem rapidamente conter uma quantidade avassaladora de informações - é bom garantir que você não tenha muitos níveis de cada variável que você escolher facetar. Aqui estão alguns exemplos rápidos com o conjunto de dados sobre malária (ver Baixar manual e dados) que consiste em contagens diárias de casos de malária para estabelecimentos, por faixa etária.
A seguir, importamos e fazemos algumas modificações rápidas para simplificar:
# Esses dados correspondem a contagens diárias de malária, por estabelecimento-dia
malaria_data <- import(here("data", "malaria_facility_count_data.rds")) %>% # importar
select(-submitted_date, -Province, -newid) # remove colunas desnecessáriasAs primeiras 50 filas dos dados sobre a malária estão abaixo. Observe que existe uma coluna malaria_tot, mas também colunas para contagens por faixa etária (estas serão utilizadas no segundo exemplo referente ao facet_grid() ).
facet_wrap()
No momento, vamos nos concentrar nas colunas malaria_tot e District. Ignore por enquanto as colunas de contagem por idade. Vamos traçar curvas epidêmicas com geom_col(), que produz uma coluna para cada dia com a altura do eixo y sendo especificada com o valor obtido na coluna malaria_tot (os dados já são contagens diárias, então utilizamos geom_col() - veja a seção “Bar plot” abaixo).
Quando adicionamos o comando facet_wrap(), especificamos um til e depois a coluna para facetar sobre (neste caso, District). Você pode colocar outra coluna no lado esquerdo do til - isto criará uma faceta para cada combinação - mas recomendamos que você faça isto com facet_grid() em seu lugar. Neste caso de uso, uma faceta é criada para cada valor único de District.
# Um gráfico com facetas por distrito
ggplot(malaria_data, aes(x = data_date, y = malaria_tot)) +
geom_col(width = 1, fill = "darkred") + # plote a contagem como colunas
theme_minimal()+ # simplifique os paineis de fundo
labs( # aficione rótulos, títulos, etc.
x = "Data dos registros",
y = "Casos de malária",
title = "Casos de malária por distrito") +
facet_wrap(~District) # As facetas são criadas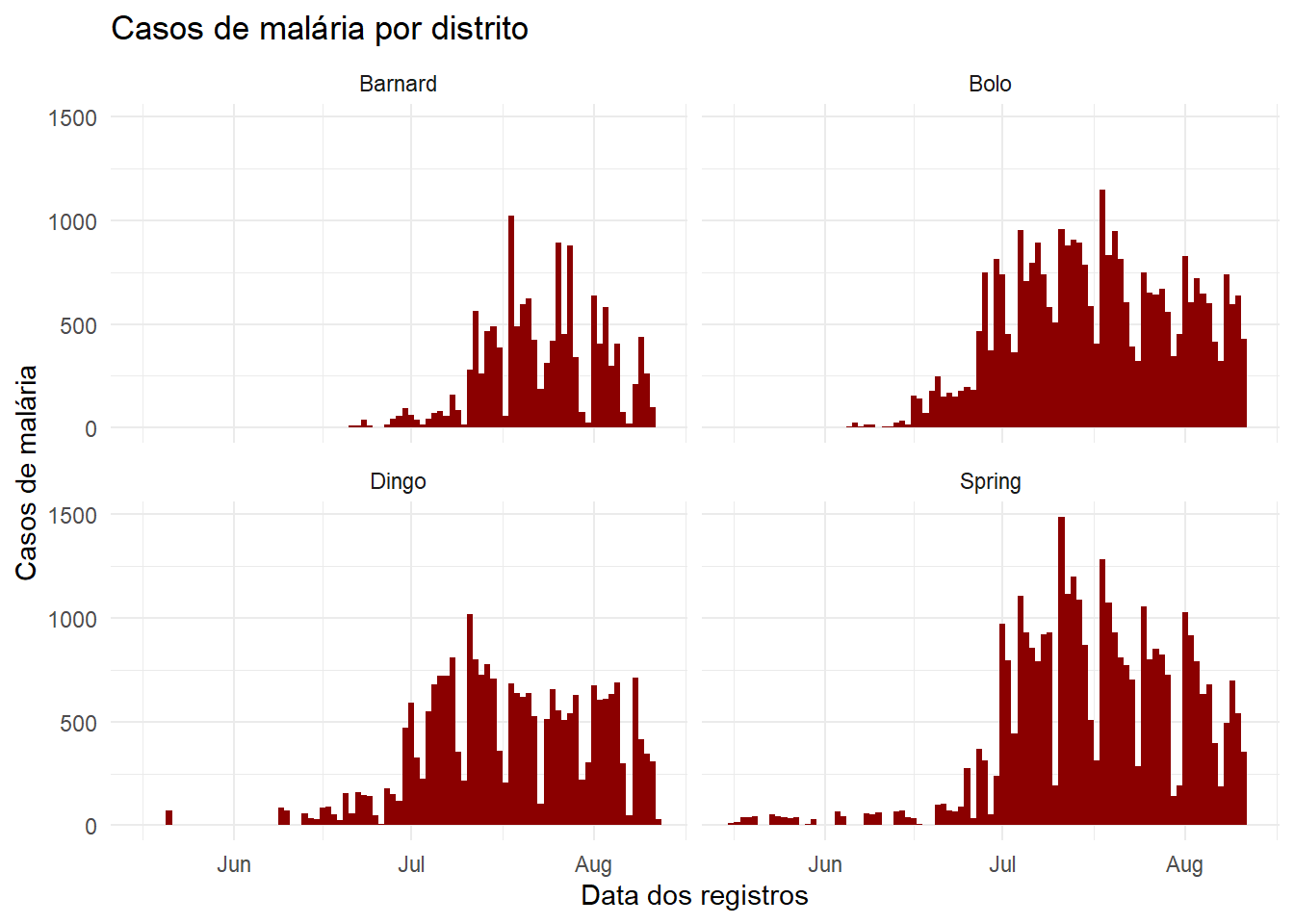
facet_grid()
Podemos utilizar uma abordagem facet_grid() para cruzar duas variáveis. Digamos que queremos cruzar o Distrito (District) e a idade (age). Bem, precisamos fazer algumas transformações de dados nas colunas de idade para obter esses dados no formato “longo”, preferido pelo ggplot. Todos os grupos etários têm suas próprias colunas - queremo-los em uma única coluna chamada faixa_etaria e outra chamada num_casos. Consulte a página em Pivoteamento de dados para obter mais informações sobre este processo.
malaria_age <- malaria_data %>%
select(-malaria_tot) %>%
pivot_longer(
cols = c(starts_with("malaria_rdt_")), # escolha as colunas que quer pivotear para o formato longo
names_to = "faixa_etaria", # column names become age group
values_to = "num_casos" # values to a single column (num_casos)
) %>%
mutate(
faixa_etaria = str_replace(faixa_etaria, "malaria_rdt_", ""),
faixa_etaria = forcats::fct_relevel(faixa_etaria, "5-14", after = 1))Agora as primeiras 50 linhas dos dados aparecem assim:
Quando você passa as duas variáveis para facet_grid(), o mais fácil é utilizar notação de fórmula (por exemplo x ~ y) onde x corresponde às linhas e y às colunas. Aqui está o gráfico, utilizando facet_grid() para mostrar os gráficos para cada combinação das colunas faixa_etaria e District.
ggplot(malaria_age, aes(x = data_date, y = num_casos)) +
geom_col(fill = "darkred", width = 1) +
theme_minimal()+
labs(
x = "Data dos registros",
y = "Casos de malária",
title = "Casos de malária por distrito e faixa etária"
) +
facet_grid(District ~ faixa_etaria)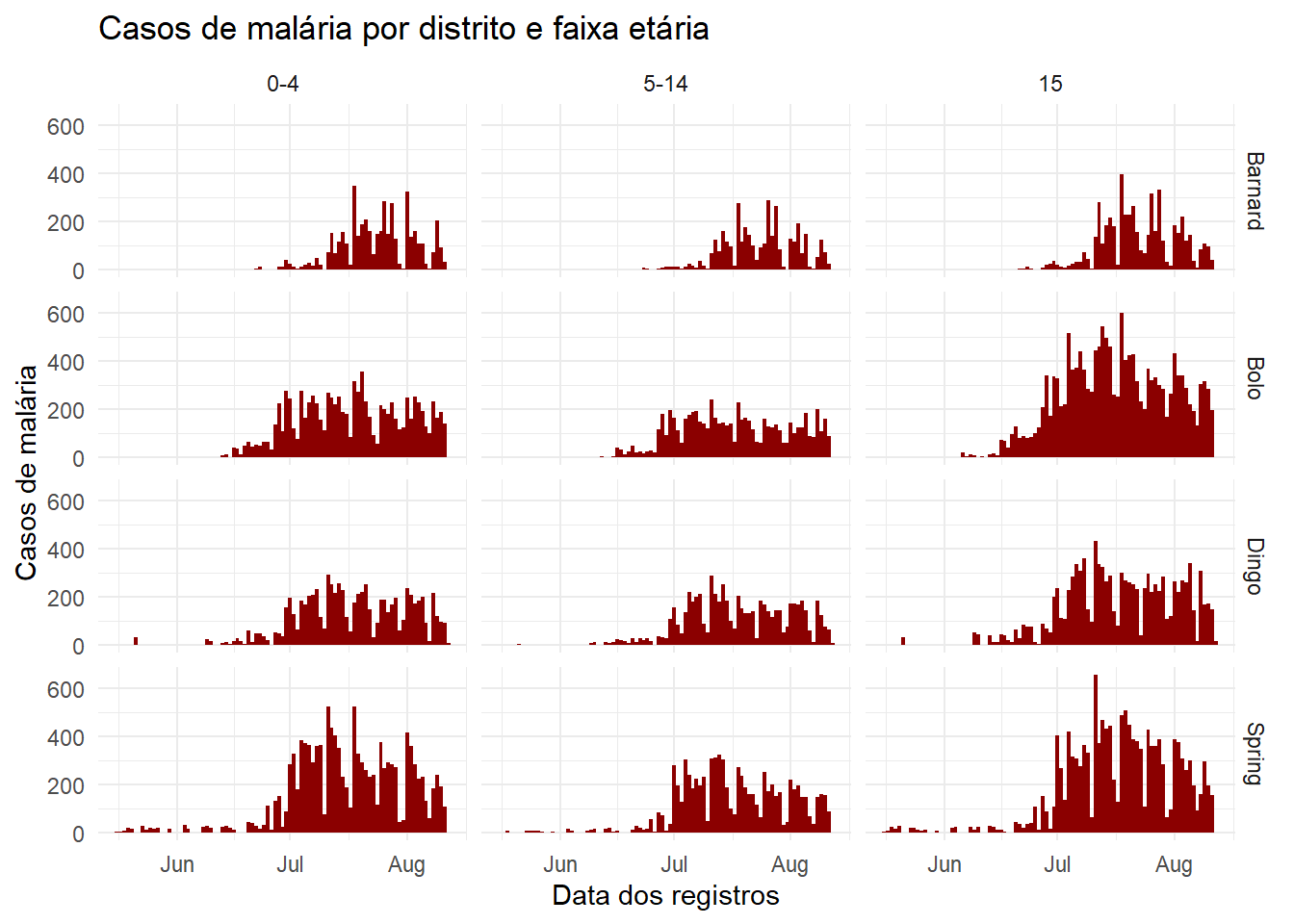
Eixos livres ou fixos
As escalas de eixos exibidas quando realizamos o facetamento é por padrão a mesma (ou seja, fixa) em todas as facetas. Isto é útil para a comparação cruzada, mas nem sempre apropriado.
Ao utilizar facet_wrap() ou facet_grid(), podemos adicionar scales = "free_y" para “liberar” os eixos y dos painéis para escalar adequadamente seu subconjunto de dados. Isto é particularmente útil se as contagens reais forem pequenas para uma das subcategorias e se as tendências forem difíceis de se observar de outra forma. Em vez de “free_y” também podemos escrever “free_x” para fazer o mesmo para o eixo x (por exemplo, para datas) ou apenas “free” para ambos os eixos. Note que em facet_grid, a escala y será a mesma para facetas na mesma linha, e a escala x será a mesma para facetas na mesma coluna.
Ao utilizar somente facet_grid, podemos adicionar space = "free_y" ou space = "free_x" para que a altura ou largura real da faceta seja ponderada para os valores da figura dentro. Isto só funciona se scales = "free" (y ou x) já estiver aplicado.
# Eixo y livre
ggplot(malaria_data, aes(x = data_date, y = malaria_tot)) +
geom_col(width = 1, fill = "darkred") + # plote os dados de contagem como colunas
theme_minimal()+ # simplifique os painel de fundo
labs( # adicione rótulos, título, etc.
x = "Data de registro",
y = "Casos de malária",
title = "Casos de malária por distrito - Eixos x e y 'livres'") +
facet_wrap(~District, scales = "free") # as facetas são criadas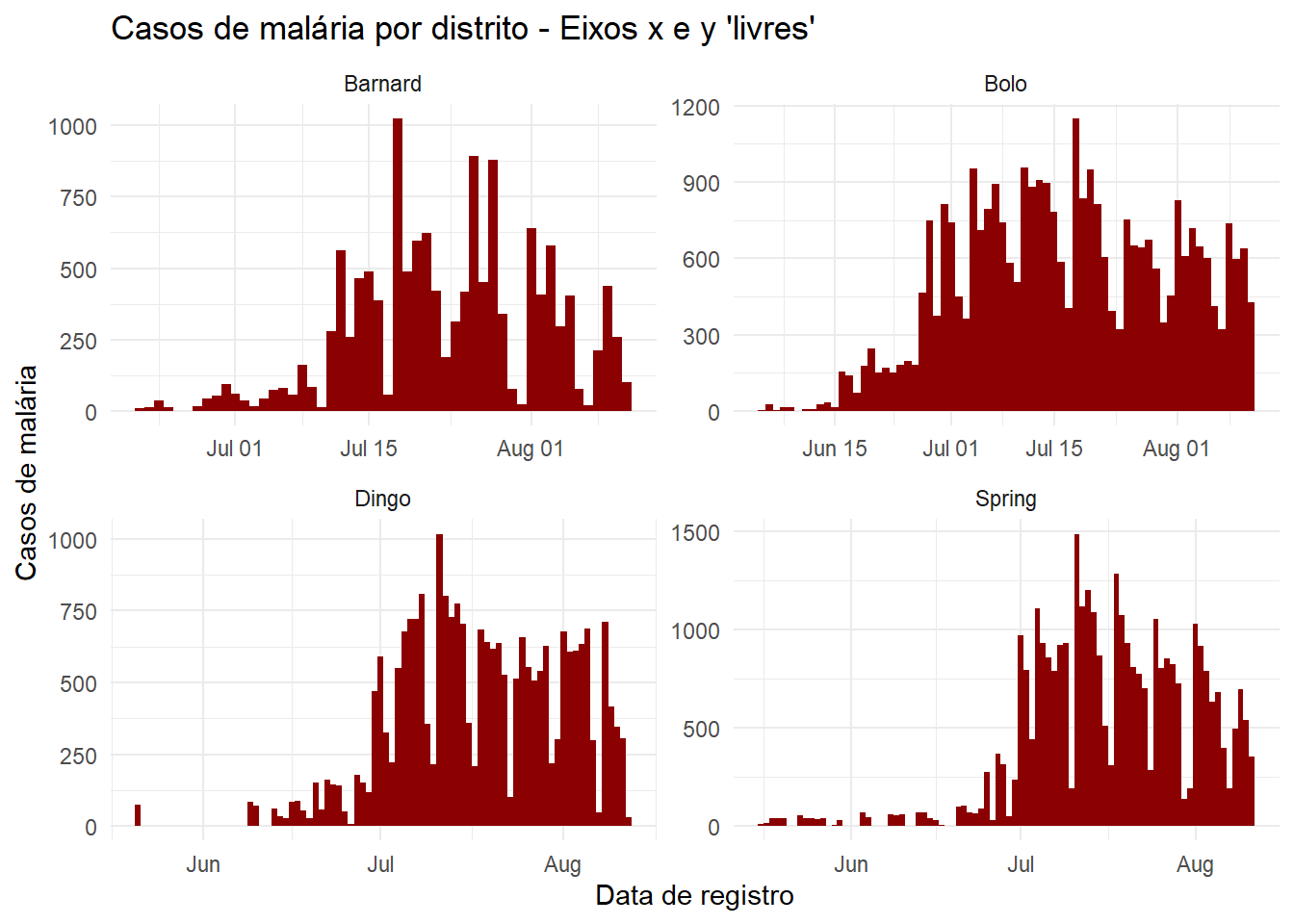
Ordem dos fatores nas facetas
Veja este post sobre como reordenar os níveis de um fator dentro de cada faceta.
30.7 Armazenando gráficos
Salvando gráficos
Por padrão, quando você executa um comando ’ggplot(), o gráfico será apresentado no painel Plots do RStudio. Entretanto, você também pode salvar o gráfico como um objeto utilizando o operador de atribuição<-e dando-lhe um nome. Então, ele não será exibido a menos que o próprio nome do objeto seja executado. Você também pode imprimi-lo envolvendo o nome do gráfico comprint()`, mas isto só é necessário em certas circunstâncias, como se o gráfico for criado dentro de um loop utilizado para imprimir vários gráficos de uma vez (veja a página Iteração, laços e listas).
# Atribua o gráfico a um objeto
age_by_wt <- ggplot(data = linelist, mapping = aes(x = age_years, y = wt_kg, color = age_years))+
geom_point(alpha = 0.1)
# exiba
age_by_wt 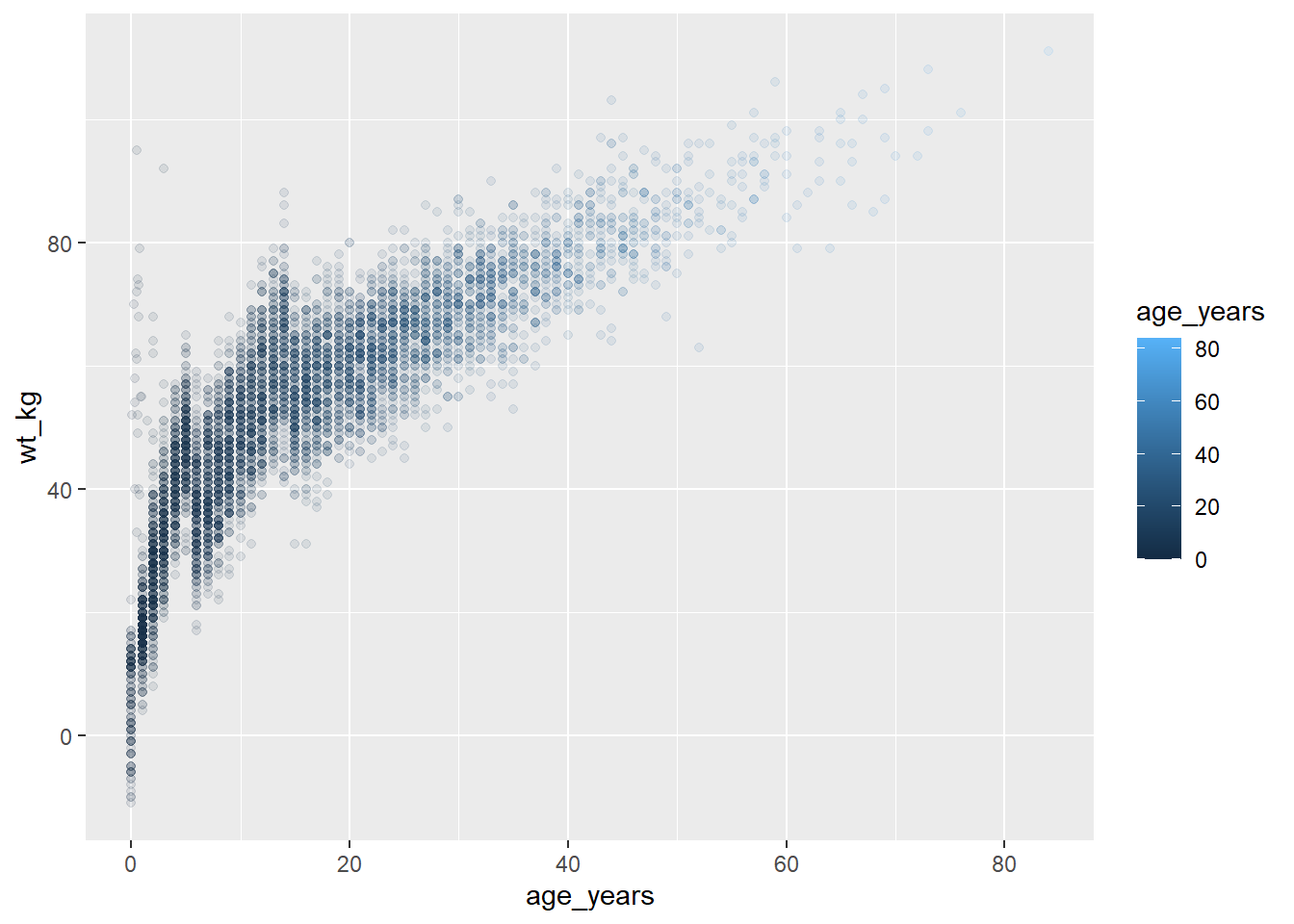
Modificando gráficos salvos
Uma coisa legal sobre ggplot2 é que você pode definir um gráfico (como acima), e depois adicionar camadas a ele começando com seu nome. Você não precisa repetir todos os comandos que criaram o gráfico original!
Por exemplo, para modificar o gráfico age_by_wt que foi definida acima, para incluir uma linha vertical aos 50 anos de idade, basta adicionar um + e começar a adicionar camadas adicionais ao gráfico.
age_by_wt+
geom_vline(xintercept = 50)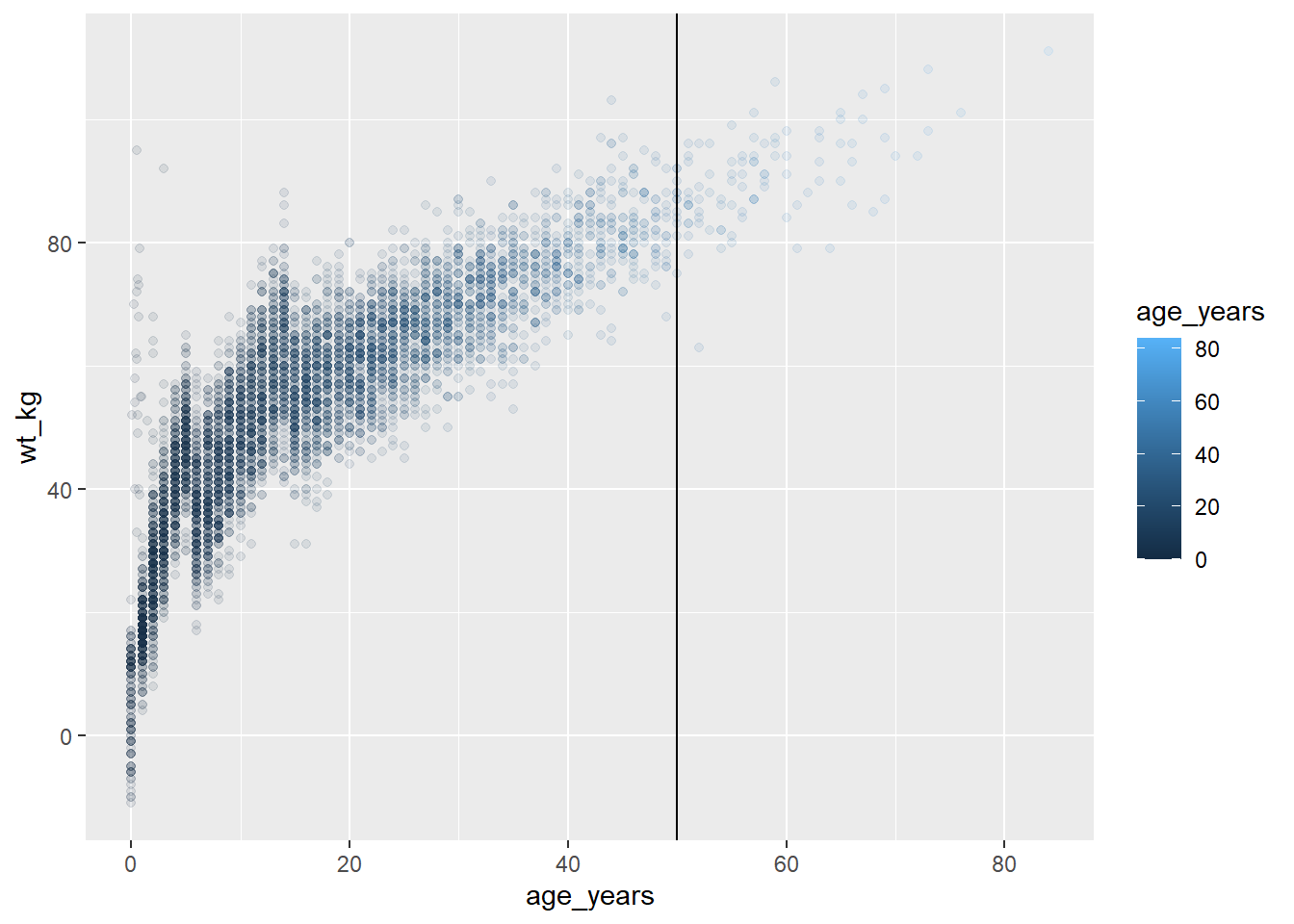
Exportando gráficos
A exportação de gráficos feitos no ggplot é facilitada com a função ggsave() de ggplot2. Ela pode funcionar de duas maneiras:
-
Especifique o nome do objeto do gráfico, depois o caminho do arquivo e o nome com extensão
- Por exemplo:
ggsave(my_plot, here("plots", "my_plot.png"))
- Por exemplo:
-
Execute o comando com apenas o parâmetro do caminho de arquivo, para salvar o último gráfico que foi feito
- Por exemplo:
ggsave(here("plots", "my_plot.png"))
- Por exemplo:
Você pode exportar como png, pdf, jpeg, tiff, bmp, svg, ou vários outros tipos de arquivo, especificando a extensão do arquivo no caminho do arquivo.
Você também pode especificar os argumentos width =, (largura) height = (altura), e units = (ou “in”, “cm”, ou “mm”). Você também pode especificar dpi = com um número para a resolução da imagem a ser salva (por exemplo, 300). Veja os detalhes da função digitando ?ggsave ou lendo a documentação online.
Lembre-se de que você pode utilizar a sintaxe da função here() para fornecer o caminho de arquivo desejado. Consulte a página Importar e exportar para obter mais informações.
30.8 Rótulos
Certamente você vai querer adicionar ou ajustar os rótulos (elementos de texto) do gráfico. Estes ajustes são mais facilmente feitos dentro da função labs() que é adicionada ao gráfico com + tal como os geoms eram.
Dentro de labs() você pode fornecer strings para estes parâmetros:
-
x =ey =O título do eixo x e do eixo y (etiquetas)
-
title =O título principal do gráfico -
subtitle =O subtítulo do gráfico, em texto menor abaixo do título
-
caption =A legenda do gráfico, na parte inferior direita por padrão
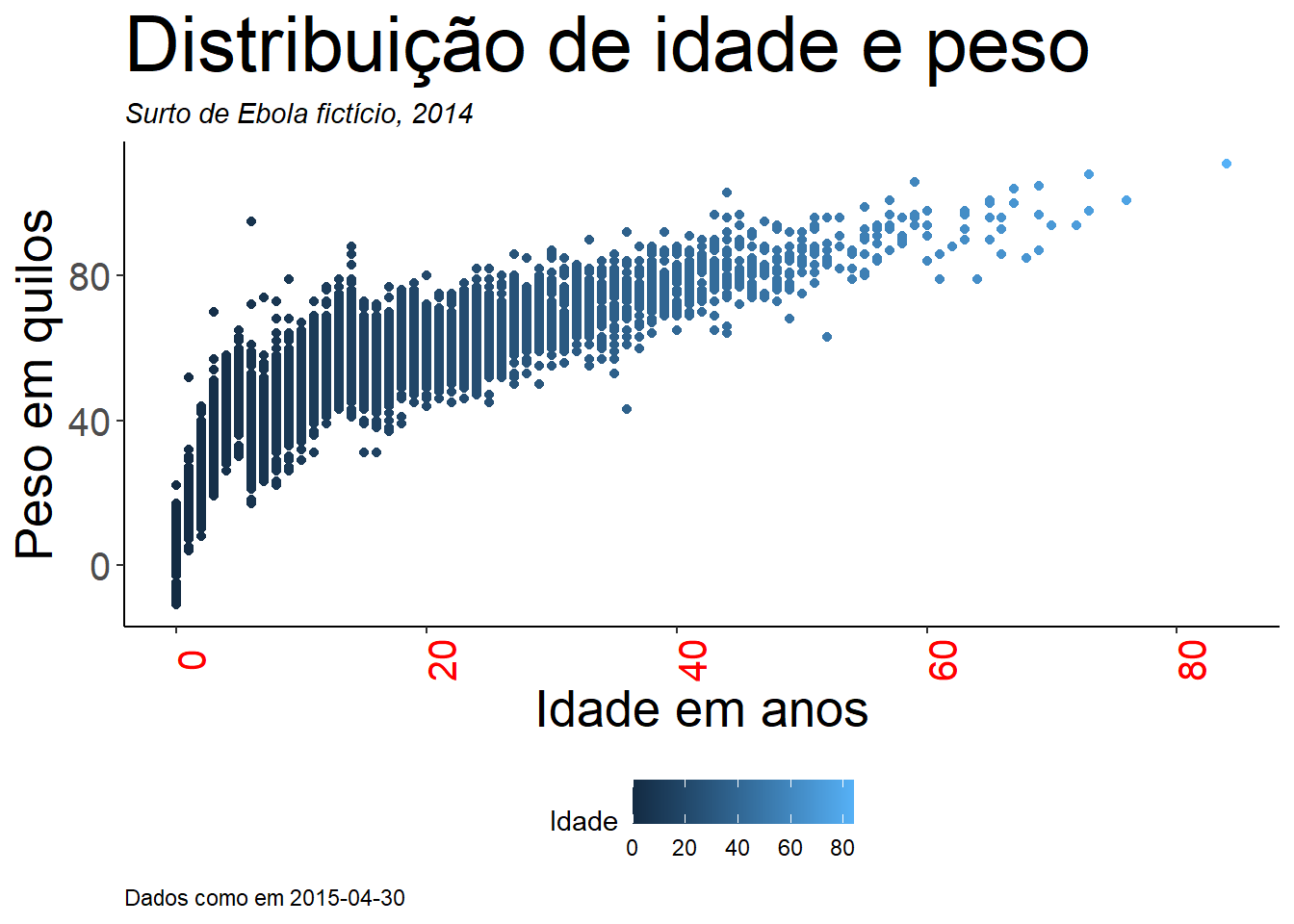
Aqui está um gráfico que fizemos anteriormente, mas com rótulos mais bonitos:
age_by_wt <- ggplot(
data = linelist, # especifique o objeto com os dados
mapping = aes( # mapeie as aesthetics para colunas desses dados
x = age, # mapeie o eixo x para idade (coluna age)
y = wt_kg, # mapeie o eixo x para peso (coluna wt_kg)
color = age))+ # mapeie a cor para a idade
geom_point()+ # mostre os dados como pontos
labs(
title = "Distribuição de idade e peso",
subtitle = "Surto de Ebola fictício, 2014",
x = "Idade em anos",
y = "Peso em quilos",
color = "Idade",
caption = stringr::str_glue("Dados como em {max(linelist$date_hospitalisation, na.rm=T)}"))
age_by_wt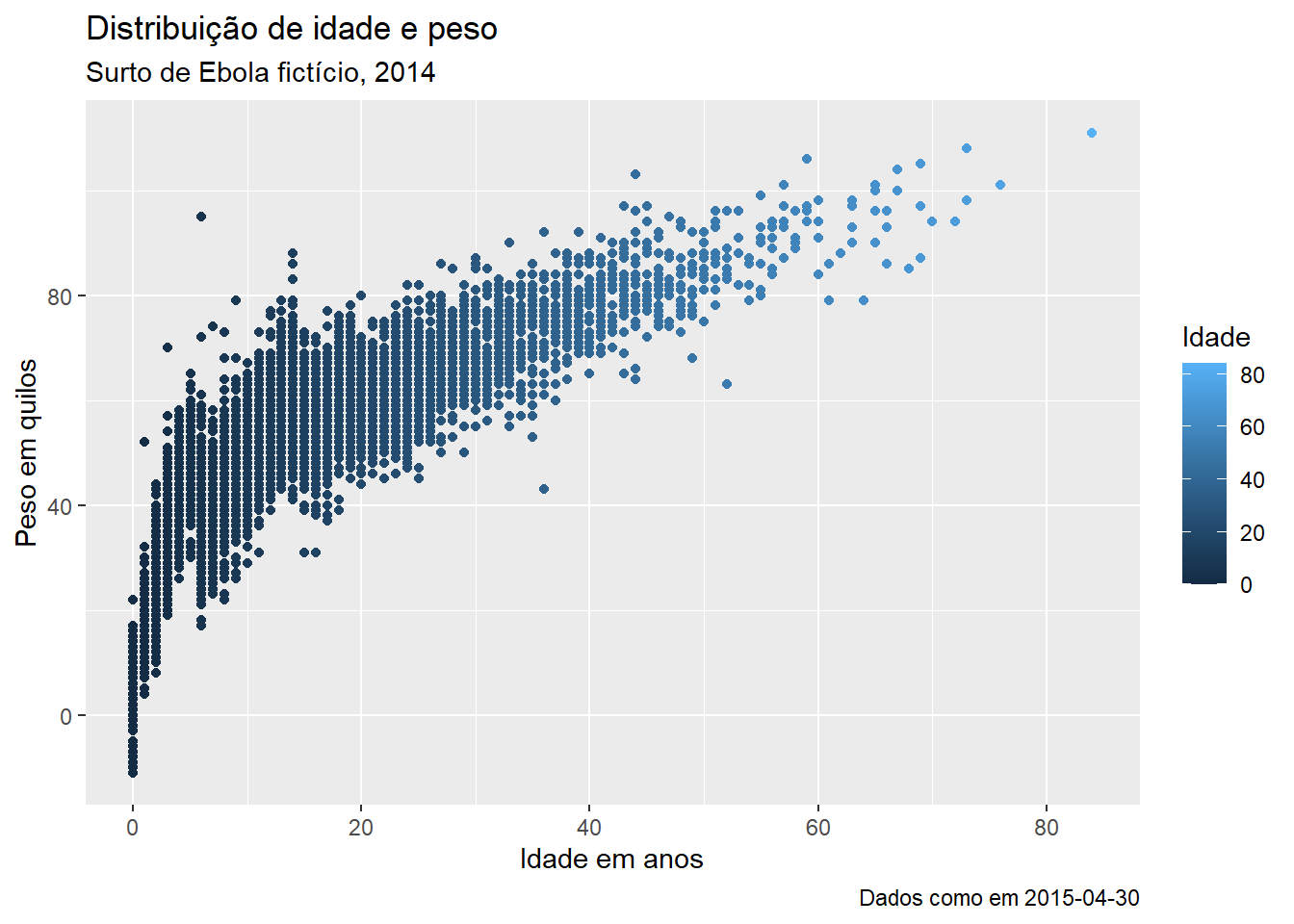
Observe como na atribuição do título utilizamos str_glue() do pacote stringr para implantar código R dinâmico dentro do texto da string. O legenda mostrará os “Dados a partir de”: “data que reflete a data máxima de hospitalização na linelist”. Leia mais sobre isto na página em Caracteres e strings.
Uma nota sobre a especificação do título da legenda: Não há nenhum argumento de “título da legenda”, pois você poderia ter múltiplas escalas em sua legenda. Dentro de labs(), você pode escrever o argumento da aesthetic do gráfico utilizada para criar a legenda, e fornecer o título desta forma. Por exemplo, acima atribuímos color = age para criar a legenda. Portanto, fornecemos color = a labs() e atribuímos o título da legenda desejada (“Idade” com I maiúsculo). Se você criar a legenda com aes(fill = COLUMN), então em labs() você escreveria fill = para ajustar o título dessa legenda. A seção sobre escalas de cores na página Dicas para o ggplot fornece mais detalhes sobre edição de legendas, e uma abordagem alternativa utilizando funções scales_().
30.9 Temas
Uma das melhores partes do ggplot2 é a quantidade de controle que você tem sobre o gráfico - você pode definir qualquer coisa! Como mencionado acima, o desenho do gráfico que não está relacionado às formas/geometrias dos dados são ajustados dentro da função theme(). Por exemplo, a cor de fundo do gráfico, presença/ausência de linhas de grade e a fonte/tamanho/cor/alinhamento do texto (títulos, subtítulos, legendas, texto do eixo…). Estes ajustes podem ser feitos de uma de duas maneiras:
*Adicionar um tema completo theme_()função para fazer ajustes de varredura - estes incluem theme_classic(), theme_minimal(), theme_dark(), theme_light()theme_grey(),theme_bw()` entre outros
- Ajuste cada pequeno aspecto do gráfico individualmente dentro de
theme()
Temas completos
Como eles são bastante diretos, demonstraremos as funções temáticas completas abaixo e não as descreveremos mais aqui. Note que quaisquer micro-ajustes com theme() devem ser feitos após a utilização de um tema completo.
Escreva-os com parênteses vazios.
ggplot(data = linelist, mapping = aes(x = age, y = wt_kg))+
geom_point(color = "darkgreen", size = 0.5, alpha = 0.2)+
labs(title = "Tema classic")+
theme_classic()
ggplot(data = linelist, mapping = aes(x = age, y = wt_kg))+
geom_point(color = "darkgreen", size = 0.5, alpha = 0.2)+
labs(title = "Tema bw")+
theme_bw()
ggplot(data = linelist, mapping = aes(x = age, y = wt_kg))+
geom_point(color = "darkgreen", size = 0.5, alpha = 0.2)+
labs(title = "Tema minimal")+
theme_minimal()
ggplot(data = linelist, mapping = aes(x = age, y = wt_kg))+
geom_point(color = "darkgreen", size = 0.5, alpha = 0.2)+
labs(title = "Tema gray")+
theme_gray()
Modifique o tema
A função theme() pode levar um grande número de argumentos, cada um dos quais edita um aspecto muito específico do gráfico. Não há como cobrir todos os argumentos, mas vamos descrever o padrão geral para eles e mostrar-lhe como encontrar o nome do argumento que você precisa. A sintaxe básica é esta:
- Dentro de
theme()escreva o nome do argumento para o elemento do gráfico que você deseja editar, comoplot.title =
- Fornecer uma função
element_()para o argumento
- Na maioria das vezes, utilize
element_text(), mas outros incluemelement_rect()para cores de fundo de tela, ouelement_blank()para remover os elementos do gráfico
- Dentro da função
element_(), escreva atribuições de argumentos para fazer os ajustes finos que você deseja
Essa descrição foi bastante abstrata, portanto, aqui estão alguns exemplos.
O gráfico abaixo parece bastante tolo, mas serve para mostrar uma variedade de maneiras de ajustar seu gráfico.
- Começamos com o gráfico
age_by_wtdefinido logo acima e acrescentamostheme_classic()
- Para ajustes mais finos, adicionamos
theme()e incluímos um argumento para cada elemento do gráfico a ser ajustado
Pode ser bom organizar os argumentos em seções lógicas. Para descrever apenas alguns dos utilizados abaixo:
-
legend.position =é único no sentido de aceitar valores simples como “bottom”, “top”, “left”, e “right”. Mas geralmente, os argumentos relacionados ao texto exigem que você coloque os detalhes noelement_text().
- tamanho do título com
element_text(size = 30).
- O alinhamento horizontal do título com
element_text(hjust = 0)(da direita para a esquerda)
- O subtítulo está em itálico com
element_text(face = "italic")
age_by_wt +
theme_classic()+ # ajustes de tema pré-definidos
theme(
legend.position = "bottom", # move a legenda para baixo
plot.title = element_text(size = 30), # ajusta o tamanho do título para 30
plot.caption = element_text(hjust = 0), # alinha a Legenda da figura a esquerda
plot.subtitle = element_text(face = "italic"), # deixa subtítulo em itálico
axis.text.x = element_text(color = "red", size = 15, angle = 90), # ajusta o texto o eixo x
axis.text.y = element_text(size = 15), # ajusta o texto o eixo y
axis.title = element_text(size = 20) # ajusta o texto de ambos os eixos
) 
Aqui estão alguns argumentos especialmente comuns em theme(). Você reconhecerá alguns padrões, tais como acrescentar .x' ou.y’ para aplicar a mudança somente em um eixo.
Argumento theme()
|
O que é ajustado |
|---|---|
plot.title = element_text() |
O título |
plot.subtitle = element_text() |
O subtítulo |
plot.caption = element_text() |
A legenda da figura (parâmetros: family, face, color, size, angle,…) |
axis.title = element_text() |
Títulos e ambos eixos (ambos x e y) (parâmetros: size, face, color…) |
axis.title.x = element_text() |
Título do eixo x (use .y para apenas eixo Y) |
axis.text = element_text() |
Texto do eixo x (ambos x and y) |
axis.text.x = element_text() |
Texto do eixo x (use .y para apenas eixo Y) |
axis.ticks = element_blank() |Remove marcações de escalas do eixo axis.line = element_line() |Linhas do eixo (parâmetros: colour, linetype: solid dashed dotted etc) strip.text = element_text() |Texto do rótulo da faceta (parâmetros: colour, face, size, angle…) strip.background = element_rect()|Rótulo da faceta (parâmetros: fill, colour, size…)
Mas há tantos argumentos para temas! Como eu poderia me lembrar de todos eles? Não se preocupe - é impossível lembrar-se de todos eles. Felizmente, existem algumas ferramentas para ajudá-lo:
A documentação sobre modificação do tema, que tem uma lista completa.
DICA: Rode theme_get() do ggplot2 para listar os mais de 90 argumentos da função theme() no console .
DICA: Se você em algum momento quiser remover um elemento do gráfico, você também o pode fazer com o theme(). Apenas passe o parâmetro element_blank() para um argumento para que ele desapareca completamente. Para legendas, configure legend.position = "none".
30.10 Cores
Por favor veja a seção sobre escala de cores na página de dicas do ggplot.
30.11 Usando o pipe (%>%) no ggplot2
Ao utilizar pipes (%>%) para limpar e transformar seus dados, é fácil passar os dados transformados em ggplot().
Os pipes que passam o conjunto de dados de função para função passarão a ser um símbolo de mais + assim que a função ggplot() for chamada. Observe que, neste caso, não há necessidade de especificar o argumento data = (data), pois este é automaticamente definido como o conjunto de dados que vinha sendo usado no pipe.
Esta é a aparência que pode ter:
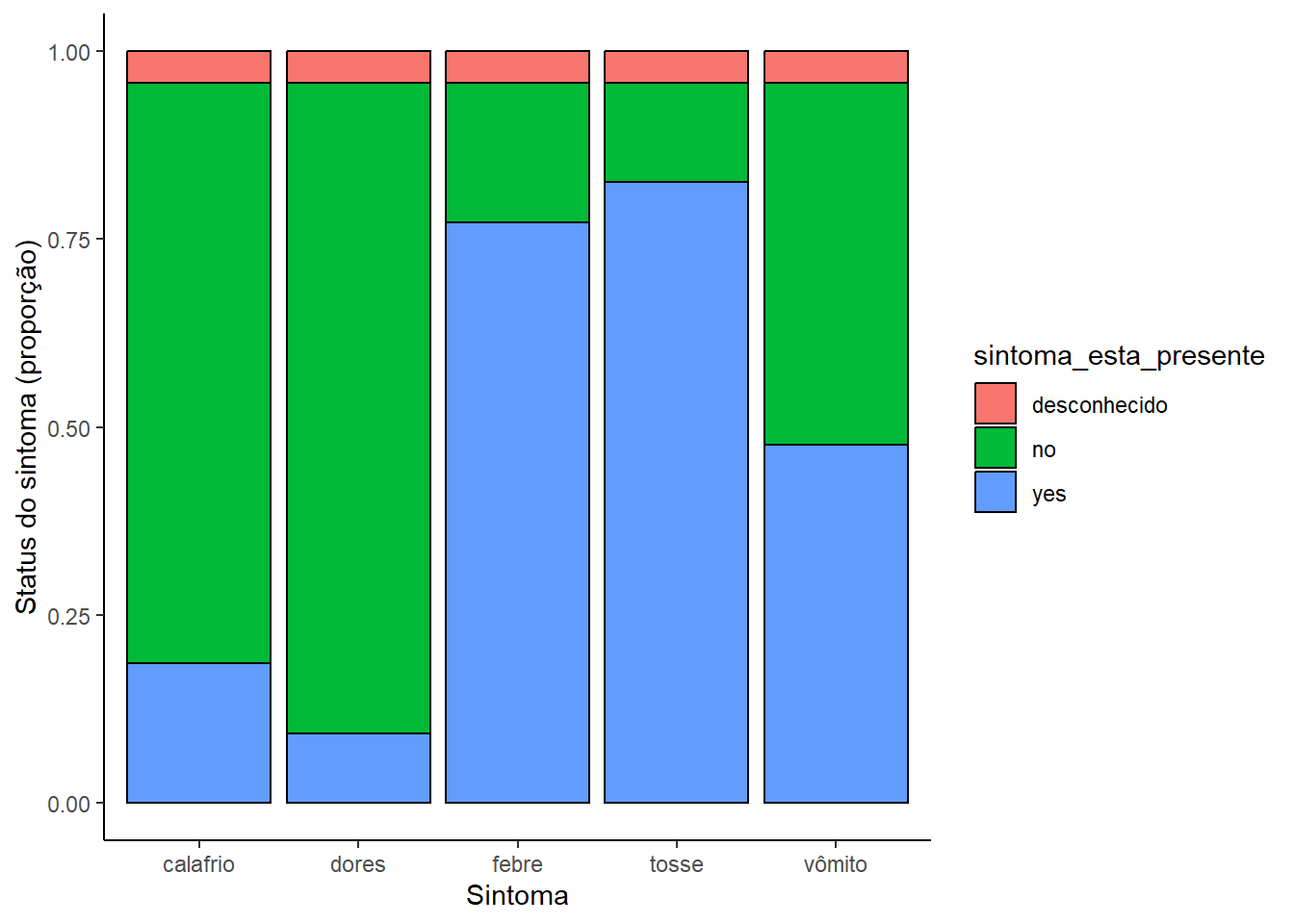
linelist %>% # comece com a linelist
rename(tosse=cough,
febre=fever,
vômito=vomit,
dores=aches,
calafrio=chills) %>% #traduzindo o nome dos sintomas pois a base está em inglês
select(c(case_id, febre, calafrio, tosse, dores, vômito)) %>% # selecione as colunas
pivot_longer( # faça o pivotamento para ficar mais longo
cols = -case_id,
names_to = "nome_sintoma",
values_to = "sintoma_esta_presente") %>%
mutate( # substitua valores faltantes
sintoma_esta_presente = replace_na(sintoma_esta_presente, "desconhecido")) %>%
ggplot( # comece o gráfico!
mapping = aes(x = nome_sintoma, fill = sintoma_esta_presente))+
geom_bar(position = "fill", col = "black") +
theme_classic() +
labs(
x = "Sintoma",
y = "Status do sintoma (proporção)"
)
30.12 Fazer gráficos de dados contínuos
Ao longo desta página, você já viu muitos exemplos de gráficos de dados contínuos. Aqui nós os consolidamos brevemente e apresentamos algumas variações.
As visualizações aqui abordadas incluem:
Gráficos para uma variável contínua:
Histograma, um gráfico clássico para apresentar a distribuição de uma variável contínua. * Diagramas de caixa (box-plots), para mostrar os percentis 25%, 50% e 75%, pontas de cauda da distribuição e outliers (limitações importantes).
* Gráfico Jitter, para mostrar todos os valores como pontos que estão ‘tremidos’ para que possam (principalmente) ser todos vistos, mesmo onde dois têm o mesmo valor.
* Gráfico Violino, mostrar a distribuição de uma variável contínua com base na largura simétrica do ‘violino’. * Gráfico Sina, são uma combinação de gráficos de jitter e violino, onde são mostrados pontos individuais mas na forma simétrica da distribuição (via ggforce pacote). (Nota do Tradutor: Jitter em inglês significa “agitado, nervoso” e se remete ao fato dos pontos, nesse gráfico ficarem mais “espalhados” de forma a não ficarem sobrepostos ) * Gráfico de dispersão Para duas variáveis contínuas.
* Gráficos de calor para três variáveis contínuas (ligados à página gráficos de calor)
Histogramas
Os histogramas podem parecer gráficos de barras, mas são distintos porque medem a distribuição de uma variável contínua. Não há espaços entre as “barras”, e apenas uma coluna é fornecida ao geom_histogram().
Abaixo está o código para gerar histogramas, que agrupam dados contínuos em intervalos e exibem em barras adjacentes de altura variável. Isto é feito utilizando o geom_histogram(). Ver a secção “Gráfico de barra” da página básico do ggplot para compreender a diferença entre geom_histogram(), geom_bar(), e geom_col().
Mostraremos a distribuição das idades dos casos. Dentro de mapping = aes() especifique a coluna de que deseja ver a distribuição. Pode atribuir esta coluna ao eixo x ou ao eixo y.
As linhas serão atribuídas a “caixas/classes” com base na sua idade numérica, e estas classes serão representadas graficamente por barras. Se especificar um número de classes com a aesthetic bins =, os pontos de quebra são uniformemente espaçados entre os valores mínimo e máximo do histograma. Se bins = não estiver especificado, será adivinhado um número apropriado de classes e esta mensagem será exibida após o gráfico:
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Se não quiser especificar um número de classes para bins =, pode, em alternativa, especificar binwidth = nas unidades do eixo. Apresentamos alguns exemplos que mostram diferentes quantidades e larguras de classes:
# A) Histograma regular
ggplot(data = linelist, aes(x = age))+ # forneça a variável do eixo x
geom_histogram()+
labs(title = "A) Histograma padrão (30 classes)")
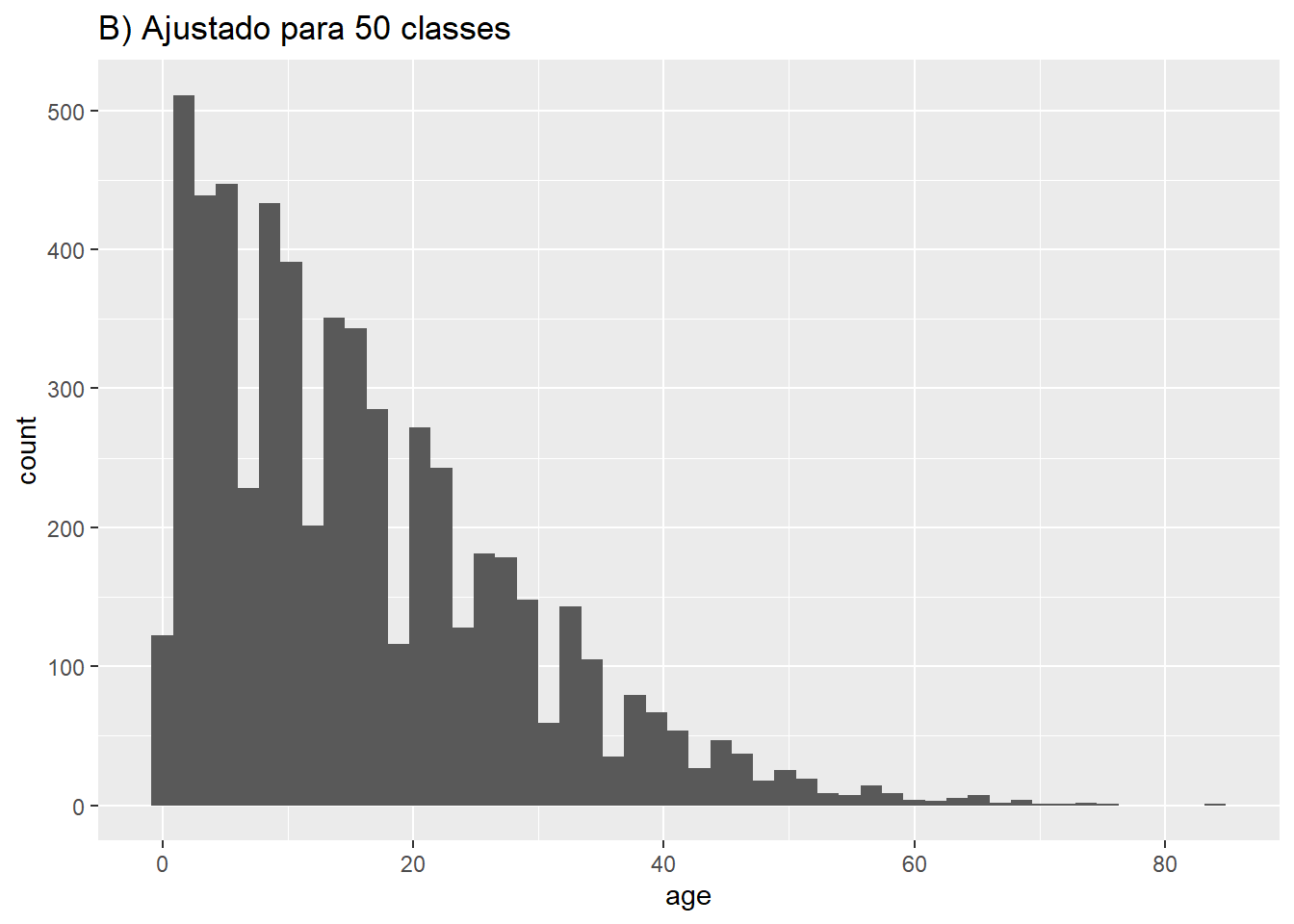
# B) Mais classes
ggplot(data = linelist, aes(x = age))+ # forneça a variável do eixo x
geom_histogram(bins = 50)+
labs(title = "B) Ajustado para 50 classes")
# C) Menos classes
ggplot(data = linelist, aes(x = age))+ # forneça a variável do eixo x
geom_histogram(bins = 5)+
labs(title = "C) Ajustado para 5 classes")
# D) Mais classes
ggplot(data = linelist, aes(x = age))+ # forneça a variável do eixo x
geom_histogram(binwidth = 1)+
labs(title = "D) Largura da classe = 1")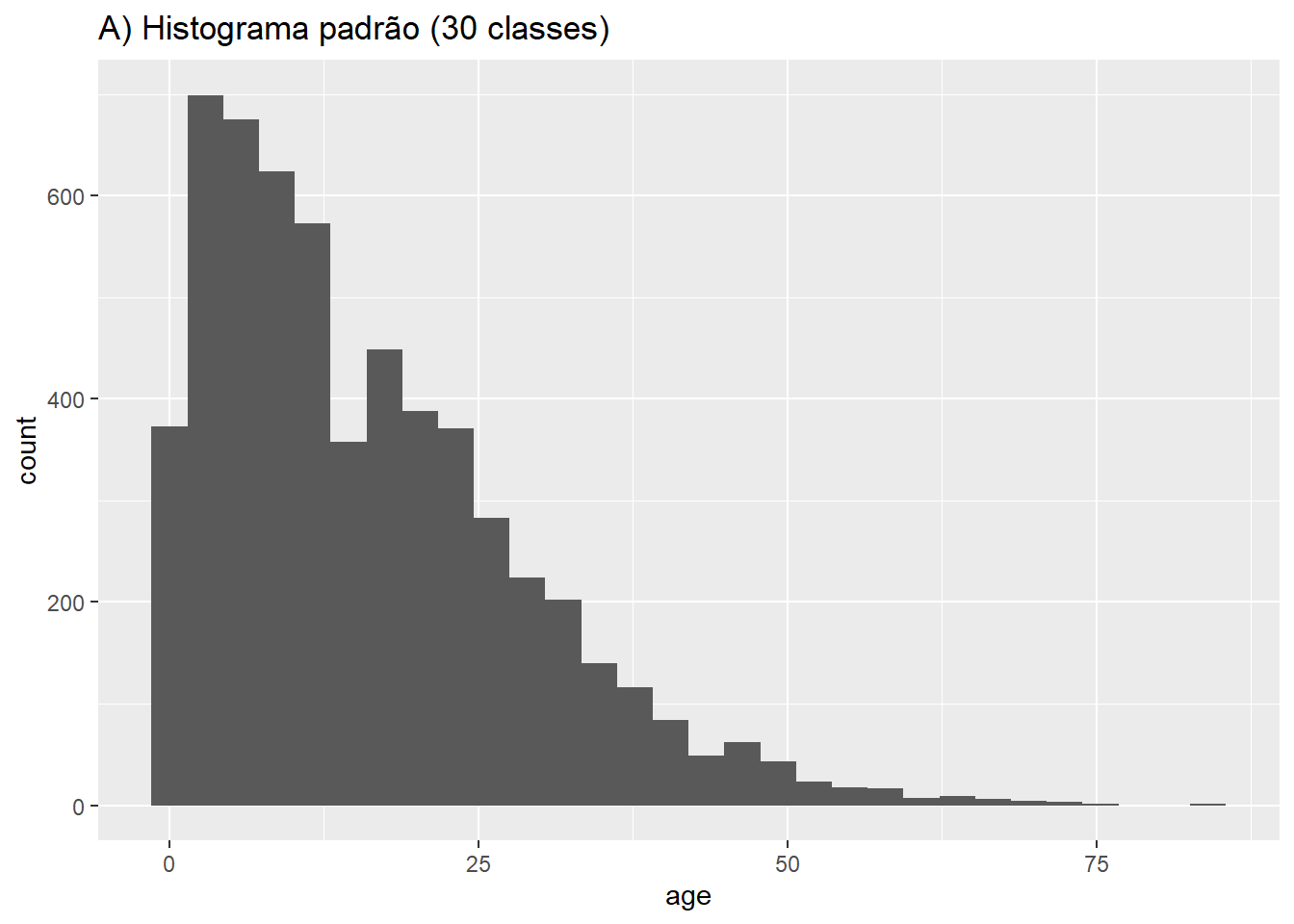
Para obter proporções suavizadas, pode utilizar geom_density():
# Frequencia com eixos de proporção, suavizadas.
ggplot(data = linelist, mapping = aes(x = age)) +
geom_density(size = 2, alpha = 0.2)+
labs(title = "Densidade proporcional")
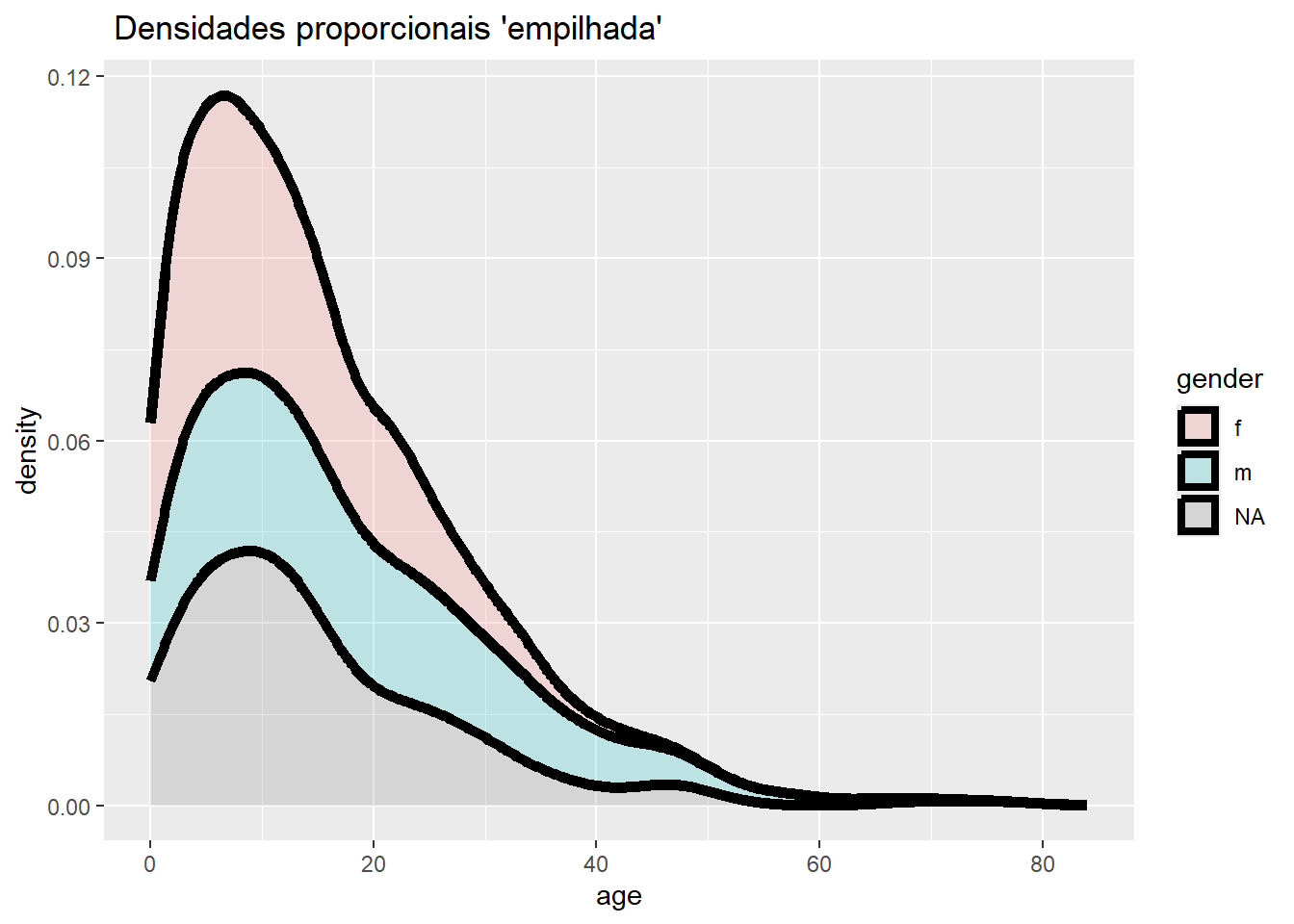
# Frequência empilhada com eixo proporcional, suavizada
ggplot(data = linelist, mapping = aes(x = age, fill = gender)) +
geom_density(size = 2, alpha = 0.2, position = "stack")+
labs(title = " Densidades proporcionais 'empilhada'")
Para obter um histograma “empilhado” (de uma coluna contínua de dados), você pode fazer uma das seguintes ações:
- Utilize
geom_histogram()com ofill =argumento dentro deaes()e atribuído à coluna de agrupamento, ou
- Utilize
geom_freqpoly(), que provavelmente é mais fácil de ler (você ainda pode definirbinwidth =)
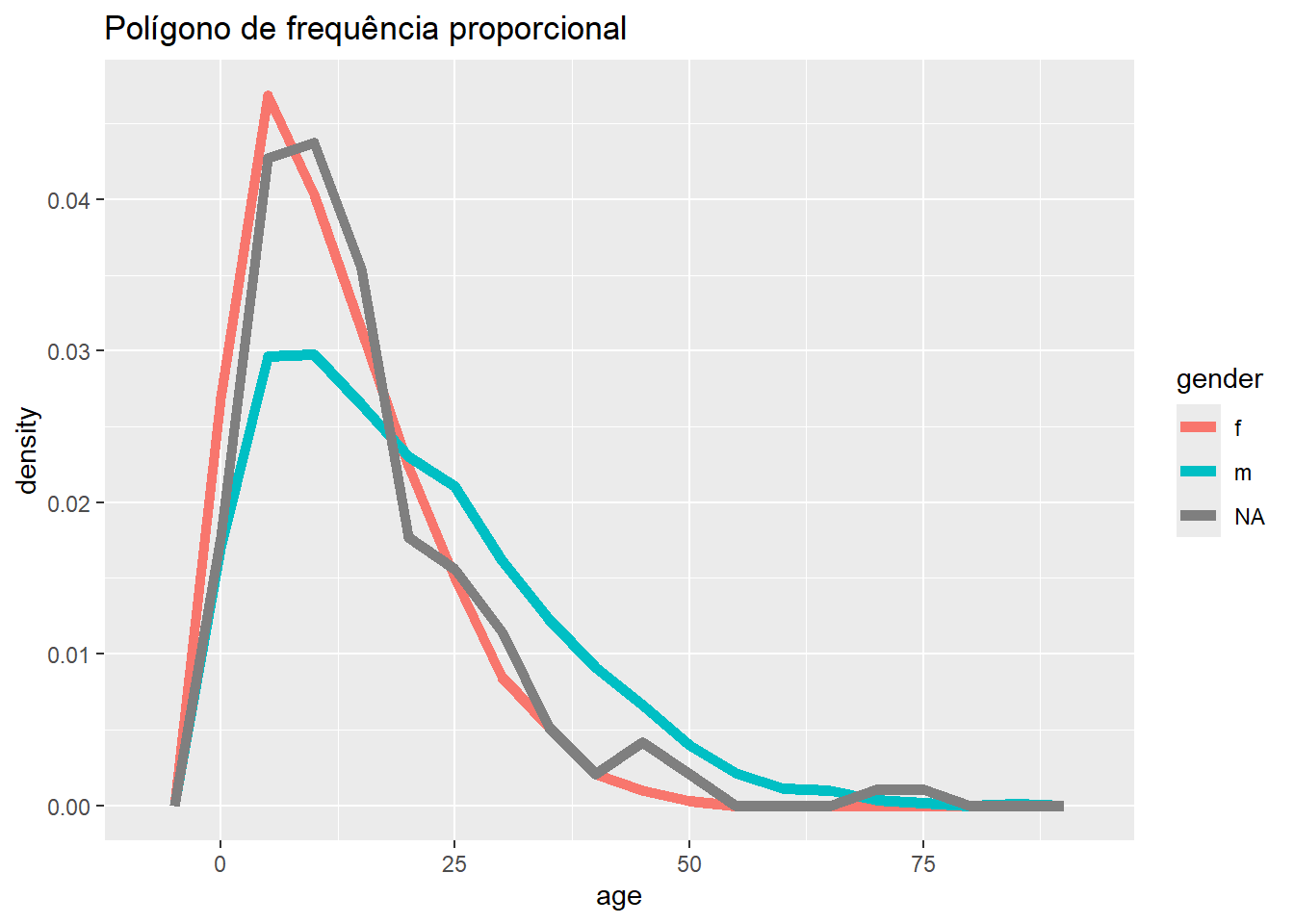
- Para ver as proporções de todos os valores, defina o
y = after_stat(density)(utilize esta sintaxe exatamente - não alterada para seus dados). Nota: estas proporções mostrarão por grupo.
Cada uma delas é mostrada abaixo (*notar a utilização de color = vs. fill = em cada uma):
# Histograma *empilhado*
ggplot(data = linelist, mapping = aes(x = age, fill = gender)) +
geom_histogram(binwidth = 2)+
labs(title = "histograma 'empilhado'")
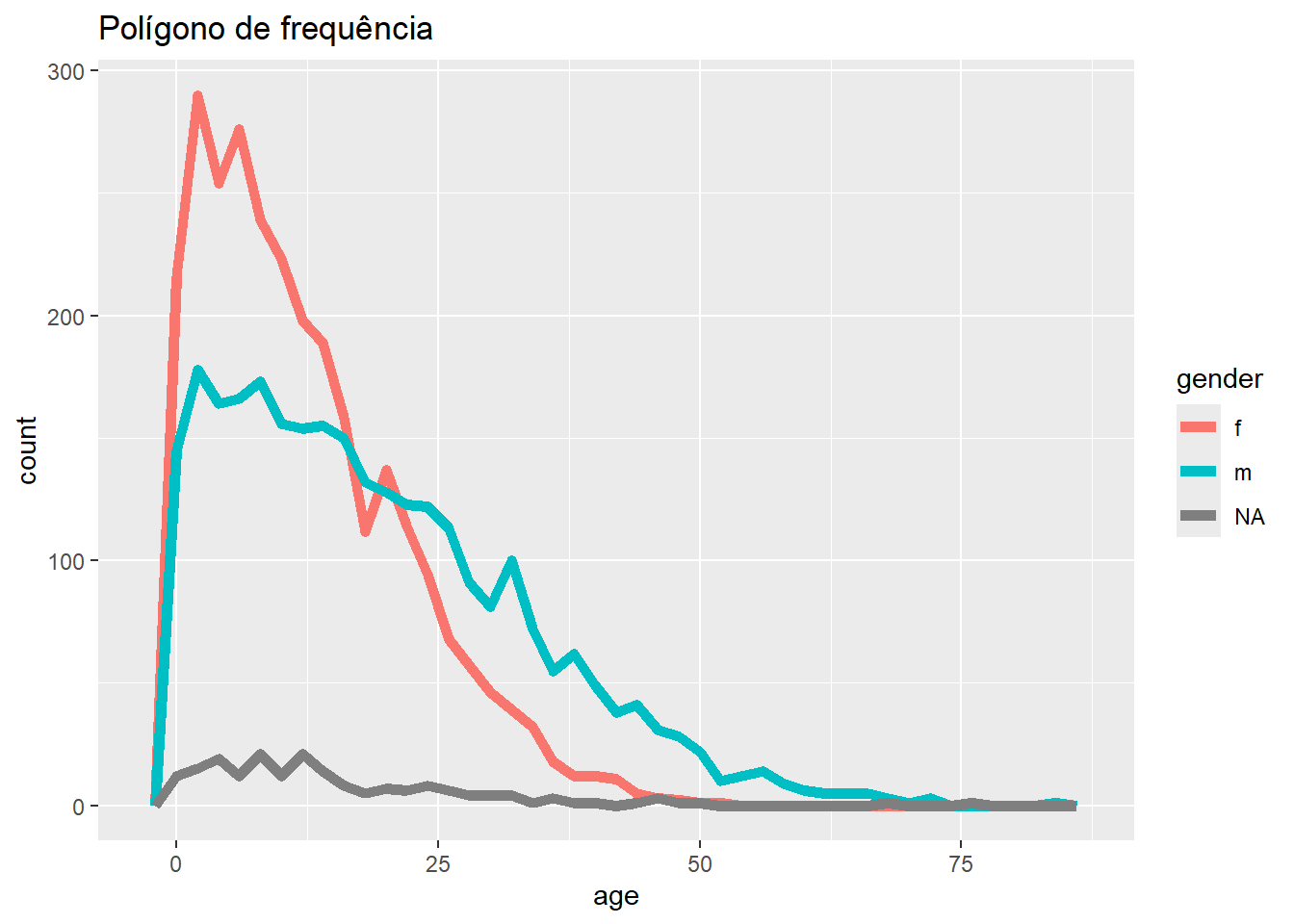
# Frequência
ggplot(data = linelist, mapping = aes(x = age, color = gender)) +
geom_freqpoly(binwidth = 2, size = 2)+
labs(title = "Polígono de frequência")
# Freqüência com eixo de proporção
ggplot(data = linelist, mapping = aes(x = age, y = after_stat(density), color = gender)) +
geom_freqpoly(binwidth = 5, size = 2)+
labs(title = "Polígono de frequência proporcional")
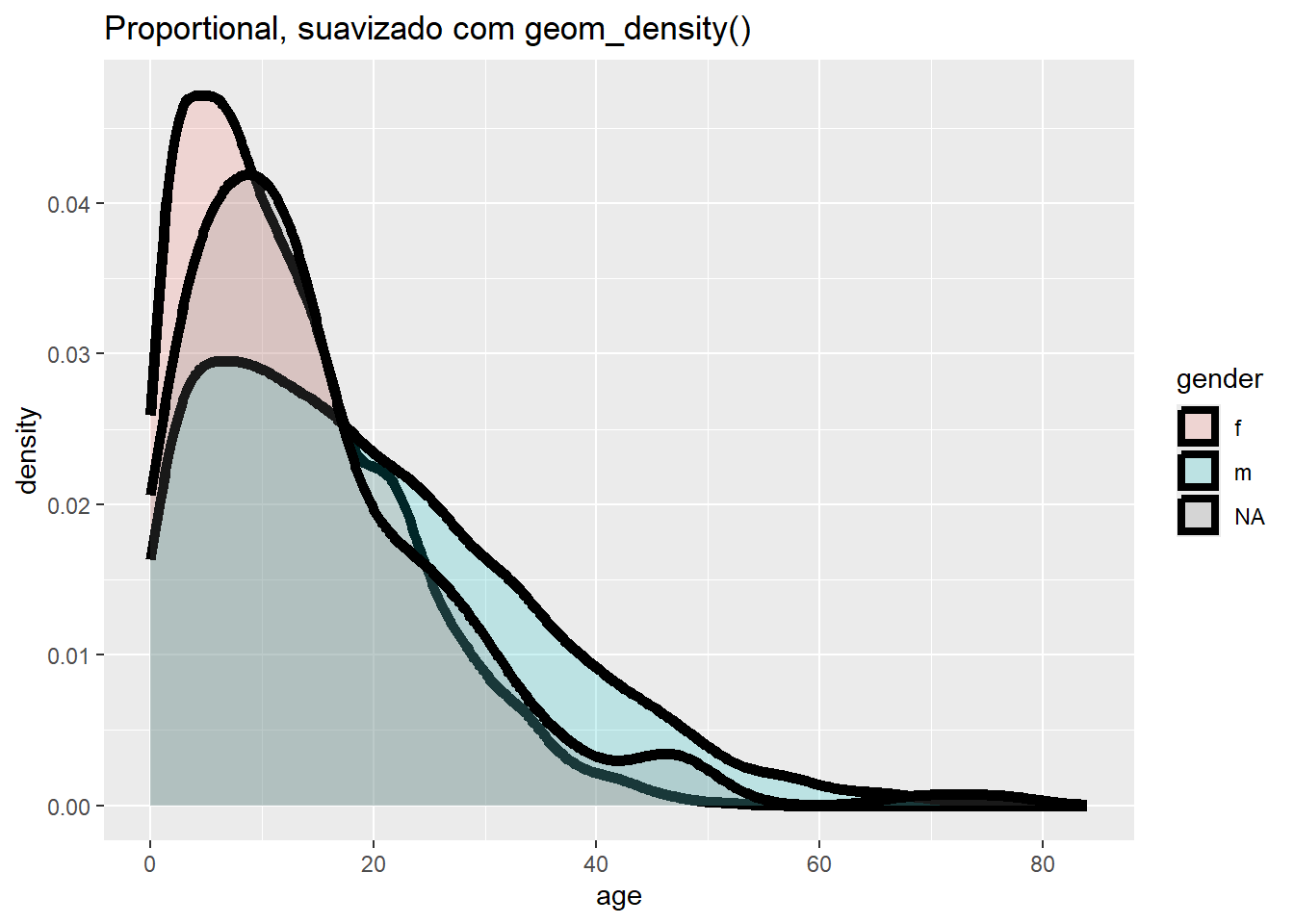
# Freqüência com eixo de proporção , suavizado
ggplot(data = linelist, mapping = aes(x = age, y = after_stat(density), fill = gender)) +
geom_density(size = 2, alpha = 0.2)+
labs(title = "Proportional, suavizado com geom_density()")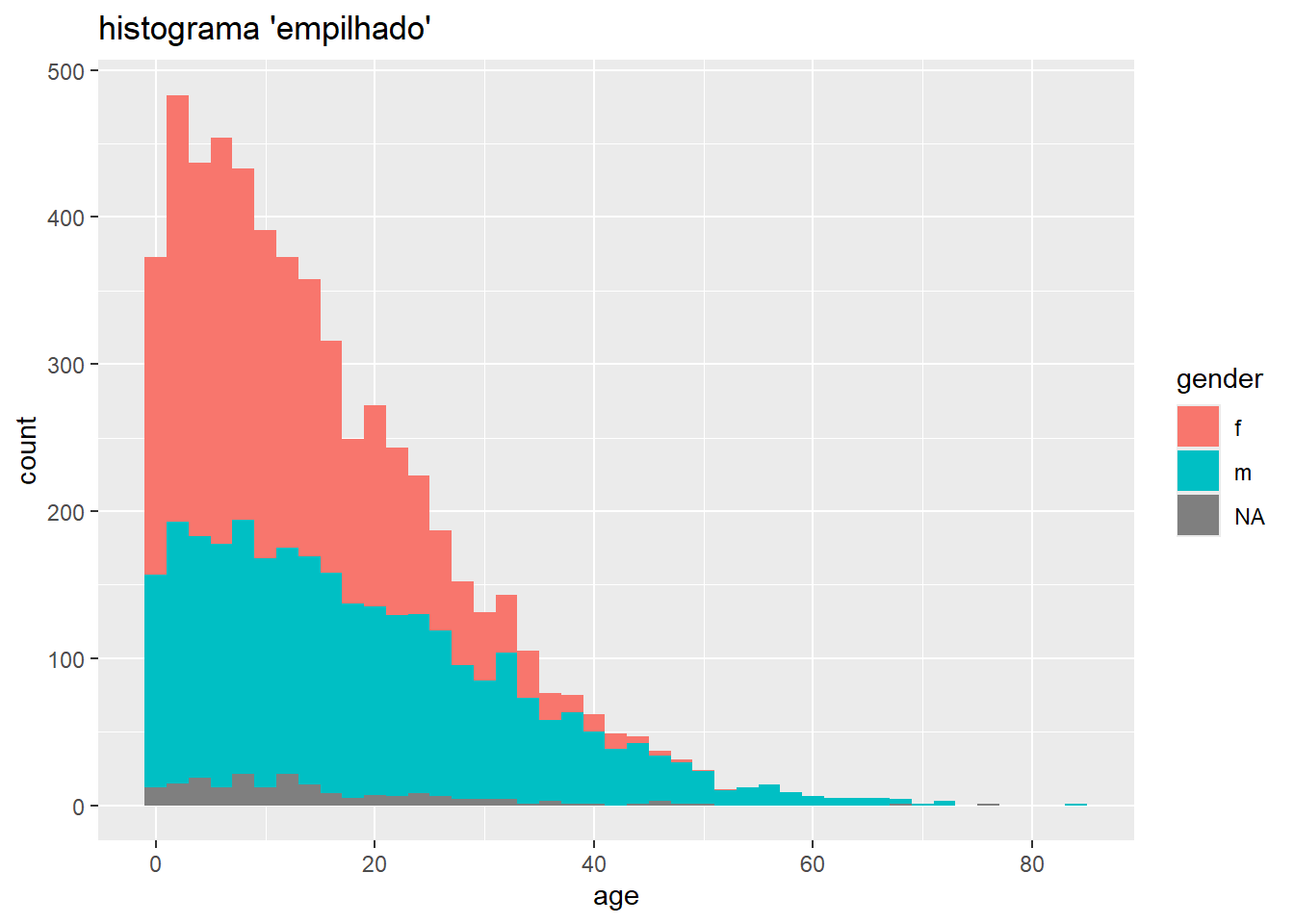
Se você quiser se divertir, tente ‘geom_density_ridges’ do pacote ggridges* (vinheta aqui.
Leia mais em detalhes sobre histogramas no tidyverse página em geom_histogram().
Box plots
Os bos-plots são comuns, mas têm limitações importantes. Elas podem obscurecer a distribuição real - por exemplo, uma distribuição bi-modal. Veja este galeria de gráficos R e este artigo data-to-viz para mais detalhes. Entretanto, eles exibem bem a faixa inter-quartil e aberturas - de modo que podem ser sobrepostos em cima de outros tipos de gráficos que mostram a distribuição em mais detalhes.
Abaixo lembramos os vários componentes de um boxplot:
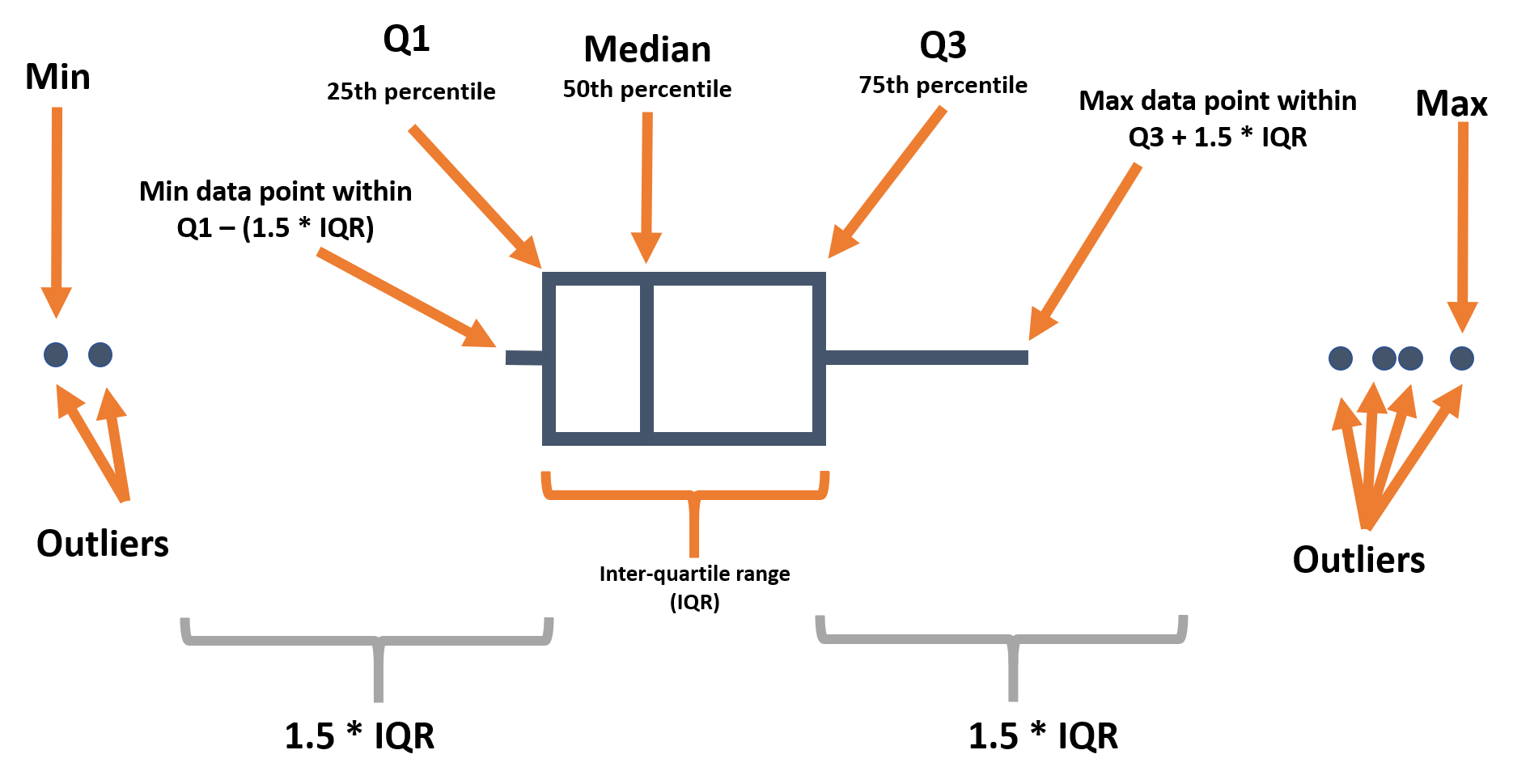
Ao utilizar geom_boxplot() para criar diagrama de caixas (box-plot), você geralmente mapeia apenas um eixo (x ou y) dentro de aes(). O eixo especificado determina se as parcelas são horizontais ou verticais.
Na maioria dos geoms, você cria um gráfico por grupo mapeando uma estética como color = ou fill = para uma coluna dentro de aes(). Entretanto, para box-plots, isso é conseguido atribuindo a coluna de agrupamento ao eixo não atribuído (x ou y). Abaixo está o código para um boxplot de todos os valores de idade no conjunto de dados, e o segundo é o código para exibir um box plot para cada sexo (não-faltante) no conjunto de dados. Observe que os valores NA (ausentes) aparecerão como um gráfico de caixa separado, a menos que seja removido. Neste exemplo, também definimos o fill para a coluna outcome, para que cada gráfico seja de uma cor diferente - mas isto não é necessário.
# A) Boxplot geral
ggplot(data = linelist)+
geom_boxplot(mapping = aes(y = age))+ # apenas o y é mapeado
labs(title = "A) Boxplot geral")
# B) Box plot por grupo
ggplot(data = linelist, mapping = aes(y = age, x = gender, fill = gender)) +
geom_boxplot()+
theme(legend.position = "none")+ # remove a legenda
labs(title = "B) Box plot por sexo") 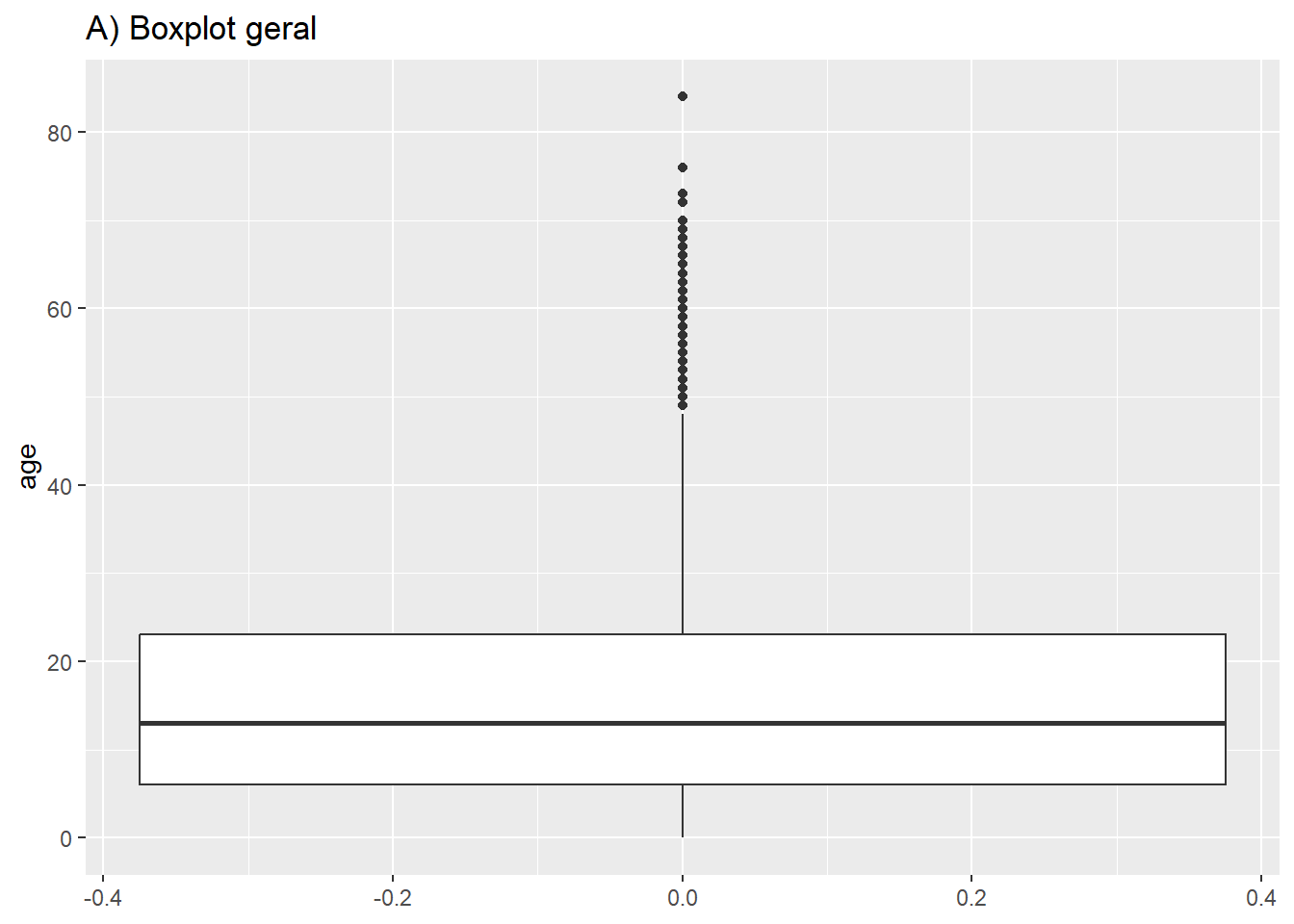
Para obter o código para adicionar um boxplot às bordas de um gráfico de dispersão (gráficos “marginais”) veja a página [Dicas para o ggplot].
Gráficos: Violino, jitter, sina
Below is code for creating violin plots (geom_violin) and jitter plots (geom_jitter) to show distributions. You can specify that the fill or color is also determined by the data, by inserting these options within aes().
# A) Gráfico de jitter por grupo
ggplot(data = linelist %>% drop_na(outcome), # remove valores faltantes
mapping = aes(y = age, # variável contínua escolhida
x = outcome, # variável de agrupamento
color = outcome))+ # variável para cor
geom_jitter()+ # criar o gráfico ´Jitter
labs(title = "A) Um grafico 'jitter' por gênero" )
# B) Gráfico de violino
ggplot(data = linelist %>% drop_na(outcome), # remove valores faltantes
mapping = aes(y = age, # Variável contínua
x = outcome, # Variável de agrupamento
fill = outcome))+ # variável de cor para preenchimento
geom_violin()+ # criar o gráfico de violino
labs(title = "B) Gráfico de violino por gênero") 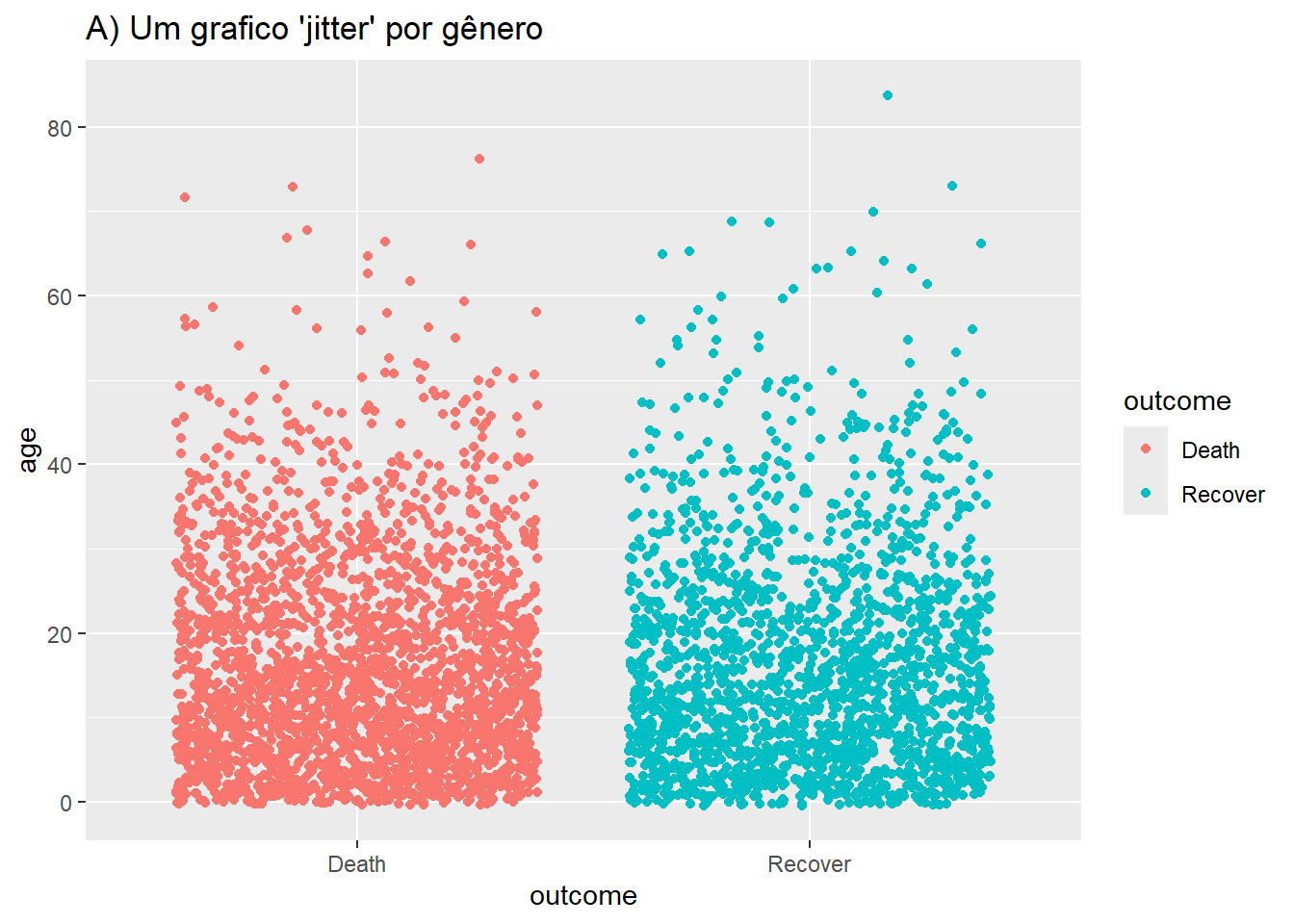
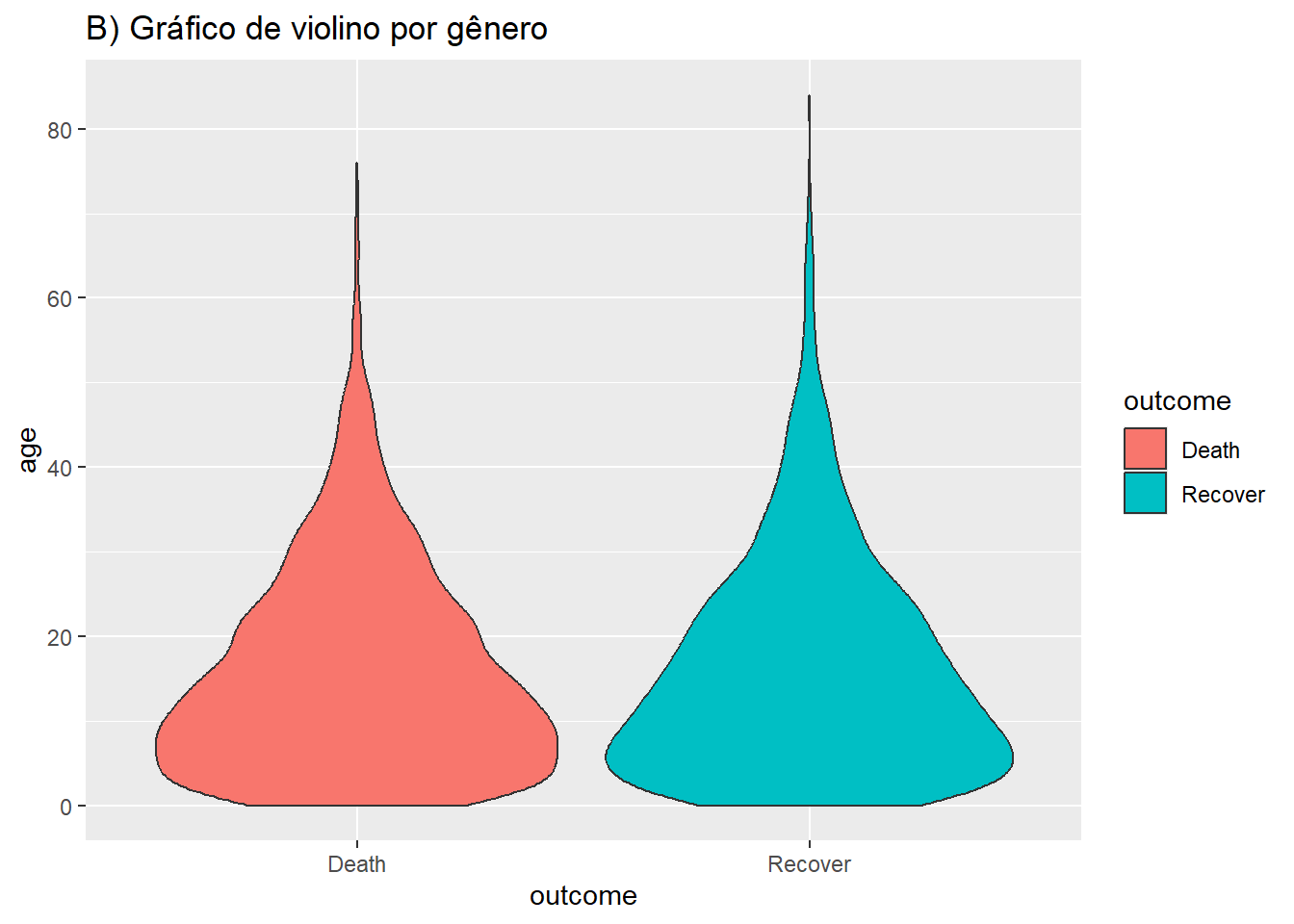
Você pode combinar os dois utilizando a função geom_sina() do pacote ggforce. Esse gráfico traça os pontos do gráfico jitter na forma do gráfico de violino. Quando sobrepostos (ajustando as transparências), isto pode ser mais fácil de interpretar visualmente.
# Um gráfico Sina por grupo
ggplot(
data = linelist %>% drop_na(outcome),
aes(y = age, # variável numérica
x = outcome)) + # variável de agrupamento
geom_violin(
aes(fill = outcome), # mapeie o preenchimento (cor do fundo do violino) segundo uma coluna
color = "white", # borda exterior branca
alpha = 0.2)+ # transparencia
geom_sina(
size=1, # Mude o tamanho do "jitter"
aes(color = outcome))+ # cor dos pontos
scale_fill_manual( # defina as cores de preenchimento do violino
values = c("Death" = "#bf5300", #óbito
"Recover" = "#11118c")) + # recuperado
scale_color_manual( # defina as cores de preenchimento dos pontos
values = c("Death" = "#bf5300",
"Recover" = "#11118c")) +
theme_minimal() + # Remove o fundo cinza
theme(legend.position = "none") + # Remove legendas desnecessárias
labs(title = "Gráfico Sina e Violino por gênero, com formtações extras") 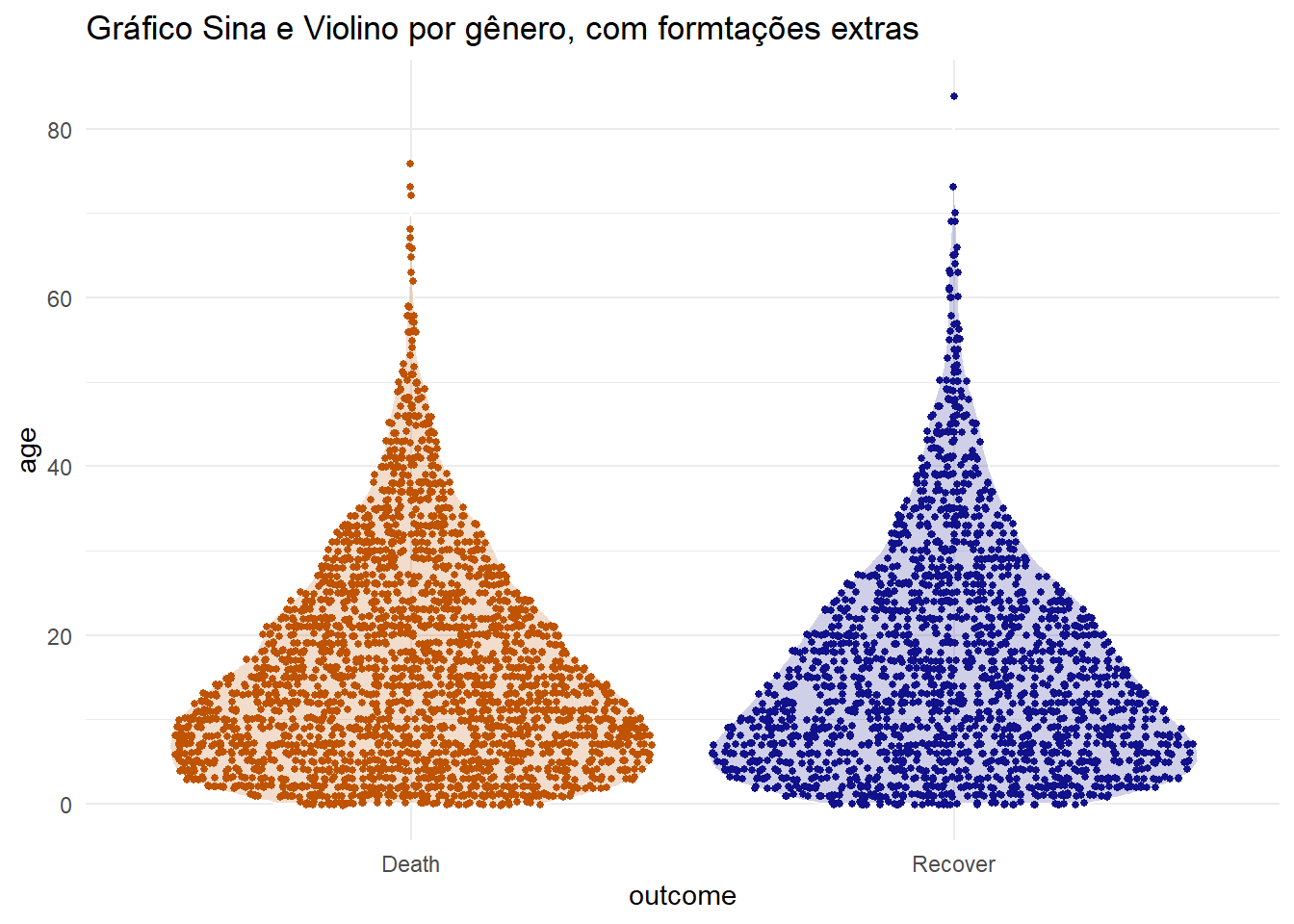
Duas variáveis contínuas
Seguindo uma sintaxe semelhante, geom_point() permitirá traçar duas variáveis contínuas uma contra a outra em uma gráfico de dispersão. Isto é útil para mostrar os valores reais ao invés de suas distribuições. Um gráfico básico de dispersão de idade vs peso é mostrado em (A). Em (B) utilizamos novamente facet_grid() para mostrar a relação entre duas variáveis contínuas na linelist.
#Gráfico de dispersão básico para idade e peso
ggplot(data = linelist,
mapping = aes(y = wt_kg, x = age))+
geom_point() +
labs(title = "A) Gráfico de dispesão para idade e peso")
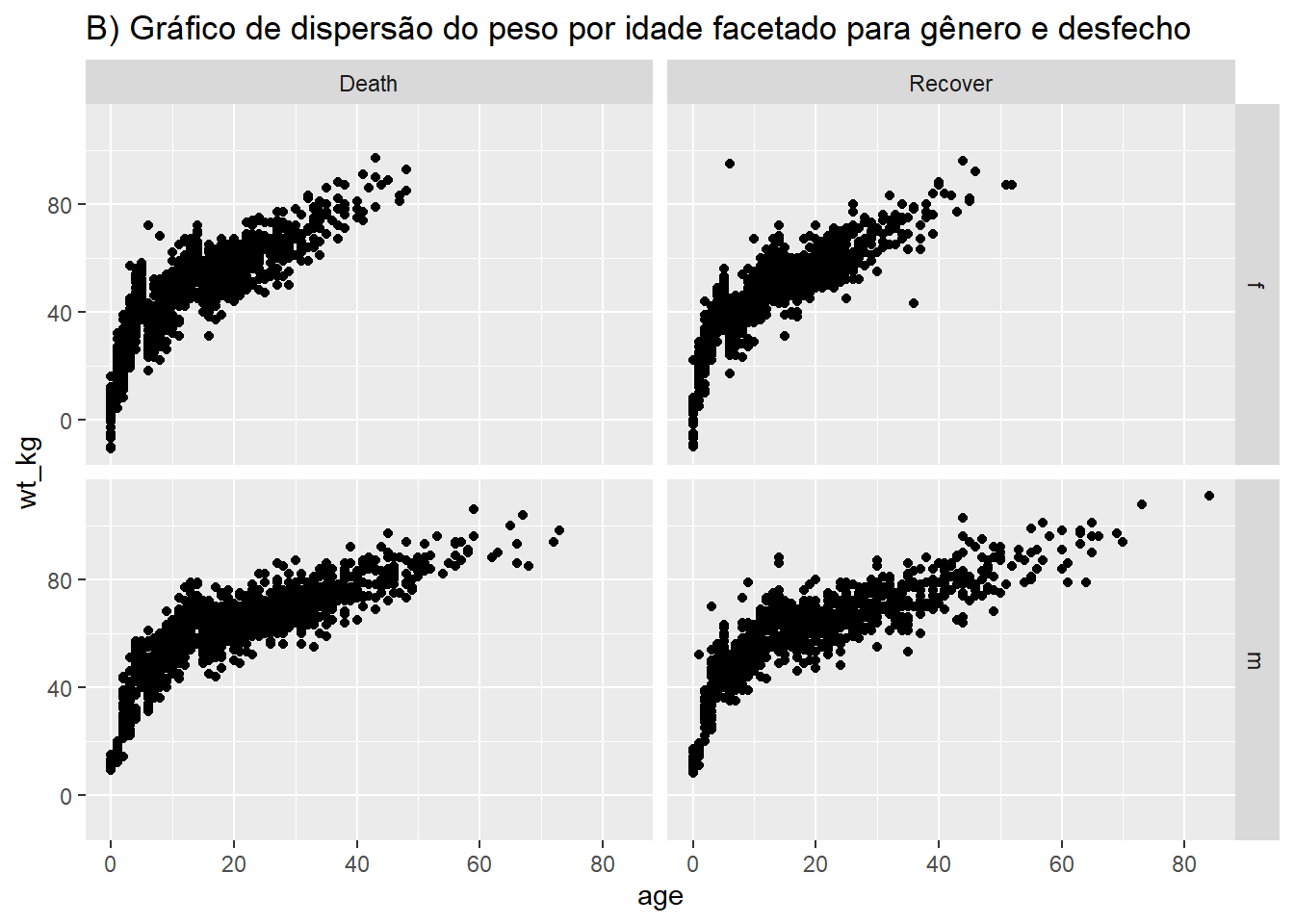
# Gráfico de dispersão de peso e idade por gênero e desfecho para o Ebola
ggplot(data = linelist %>% drop_na(gender, outcome), # filtro mantém apenas gênero e desfecho não faltantes
mapping = aes(y = wt_kg, x = age))+
geom_point() +
labs(title = "B) Gráfico de dispersão do peso por idade facetado para gênero e desfecho")+
facet_grid(gender ~ outcome) 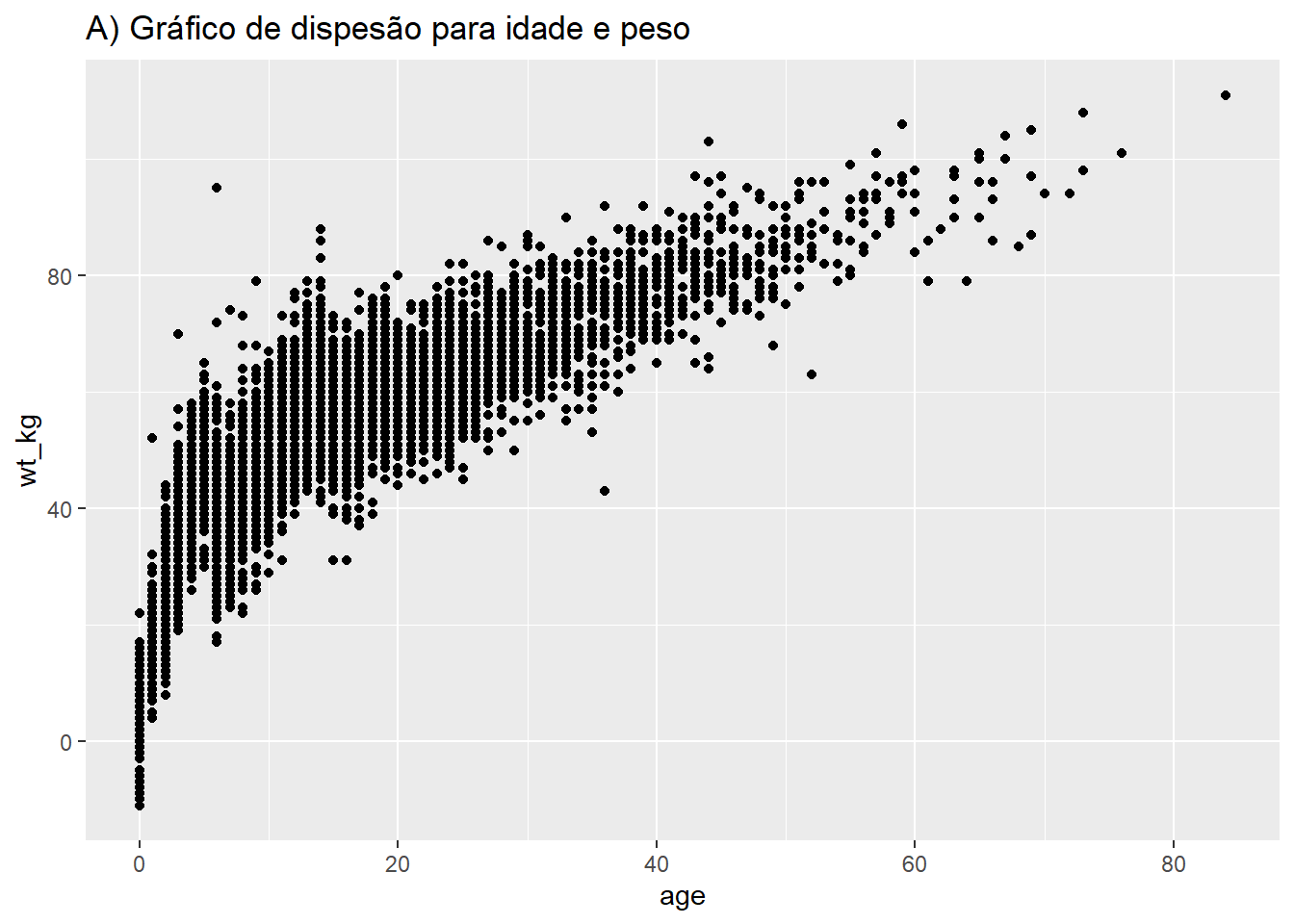
Três variáveis contínuas
Você pode exibir três variáveis contínuas utilizando o argumento fill = para criar um gráfico de calor. A cor de cada “célula” irá refletir o valor da terceira coluna contínua de dados. Veja a página Dicas para o ggplot e a página em Gráficos de calor para mais detalhes e vários exemplos.
Existem maneiras de fazer gráficos 3D em R, mas para a epidemiologia aplicada, estes são freqüentemente difíceis de interpretar e, portanto, menos úteis para a tomada de decisões.
30.13 Gráficos de dados categóricos
Dados categóricos podem ser variáveis do tipo caractere ou variáveis lógicas (TRUE/FALSE. VERDADEIRO/FALSO), ou ainda fatores (veja a página Fatores).
Preparação
Estrutura dos dados
A primeira coisa a entender sobre seus dados categóricos é se eles em sua forma bruta existem observações como uma lista de casos, ou como um quadro resumido ou agregados que contém contagens ou proporções. O estado de seus dados terá impacto na função de gráficos que você utiliza:
- Se seus dados forem observações em bruto com uma linha por observação, você provavelmente utilizará
geom_bar()
- Se seus dados já estiverem agregados em contagens ou proporções, você provavelmente utilizará
geom_col()
Classe da coluna e ordenamento dos valores
Em seguida, examine a classe das colunas que você deseja traçar. Examinamos hospital, primeiro com a função class() do R base, e com tabyl() dO pacote janitor.
# Veja a classe da coluna hospital - podemos ver que é um caracter
class(linelist$hospital)[1] "character"# Veja os valores e proporções dentro dessa coluna "hospital"
linelist %>%
tabyl(hospital) hospital n percent
Ausente 1469 0.24949049
Central Hospital 454 0.07710598
Military Hospital 896 0.15217391
Other 885 0.15030571
Port Hospital 1762 0.29925272
St. Mark's Maternity Hospital (SMMH) 422 0.07167120Podemos ver que os valores dentro são caracteres, pois se tratam de nomes de hospitais, e por padrão são ordenados alfabeticamente. Existem também “outros” e “faltam” valores, que preferimos que sejam as últimas subcategorias ao apresentarmos as subdivisões. Portanto, transformamos esta coluna em um fator e a reordenamos. Isto é tratado com mais detalhes na página Fatores.
# Converte para fator e define a ordem dos níveis para que "Other" (outros) e "Missing" (faltantes) sejam os últimos a aparecer
linelist <- linelist %>%
mutate(
hospital = fct_relevel(hospital,
"St. Mark's Maternity Hospital (SMMH)",
"Port Hospital",
"Central Hospital",
"Military Hospital",
"Other",
"Missing"))Warning: There was 1 warning in `mutate()`.
ℹ In argument: `hospital = fct_relevel(...)`.
Caused by warning:
! 1 unknown level in `f`: Missinglevels(linelist$hospital)[1] "St. Mark's Maternity Hospital (SMMH)"
[2] "Port Hospital"
[3] "Central Hospital"
[4] "Military Hospital"
[5] "Other"
[6] "Ausente" geom_bar()
Utilize geom_bar() se você quiser que a altura da barra (ou a altura dos componentes da barra empilhada) reflita o número de linhas relevantes nos dados. Essas barras terão espaços entre elas, a menos que a aesthetic largura ( width = ) esteja ajustada.
- Forneça apenas uma atribuição de coluna de um eixo (tipicamente eixo x). Se você fornecer x e y, você receberá
Error: stat_count() só pode ter uma estética x ou y.
- Você pode criar barras empilhadas, adicionando uma atribuição de
fill =coluna dentro demapping = aes().
- O eixo oposto será intitulado “count” por padrão, pois representa o número de linhas
A seguir, designamos o resultado para o eixo y, mas poderia ser igualmente fácil no eixo x. Se você tiver valores de caracteres mais longos, às vezes pode parecer melhor virar as barras para o lado e colocar a legenda embaixo. Isto pode ter impacto na forma como os níveis do seu fator são ordenados - neste caso os revertemos com fct_rev() para colocar “Other” e “Missing” na parte inferior.
# A) Desfecho em todos os casos
ggplot(linelist %>% drop_na(outcome)) +
geom_bar(aes(y = fct_rev(hospital)), width = 0.7) +
theme_minimal()+
labs(title = "A) Número de casos por hospital",
y = "Hospital")
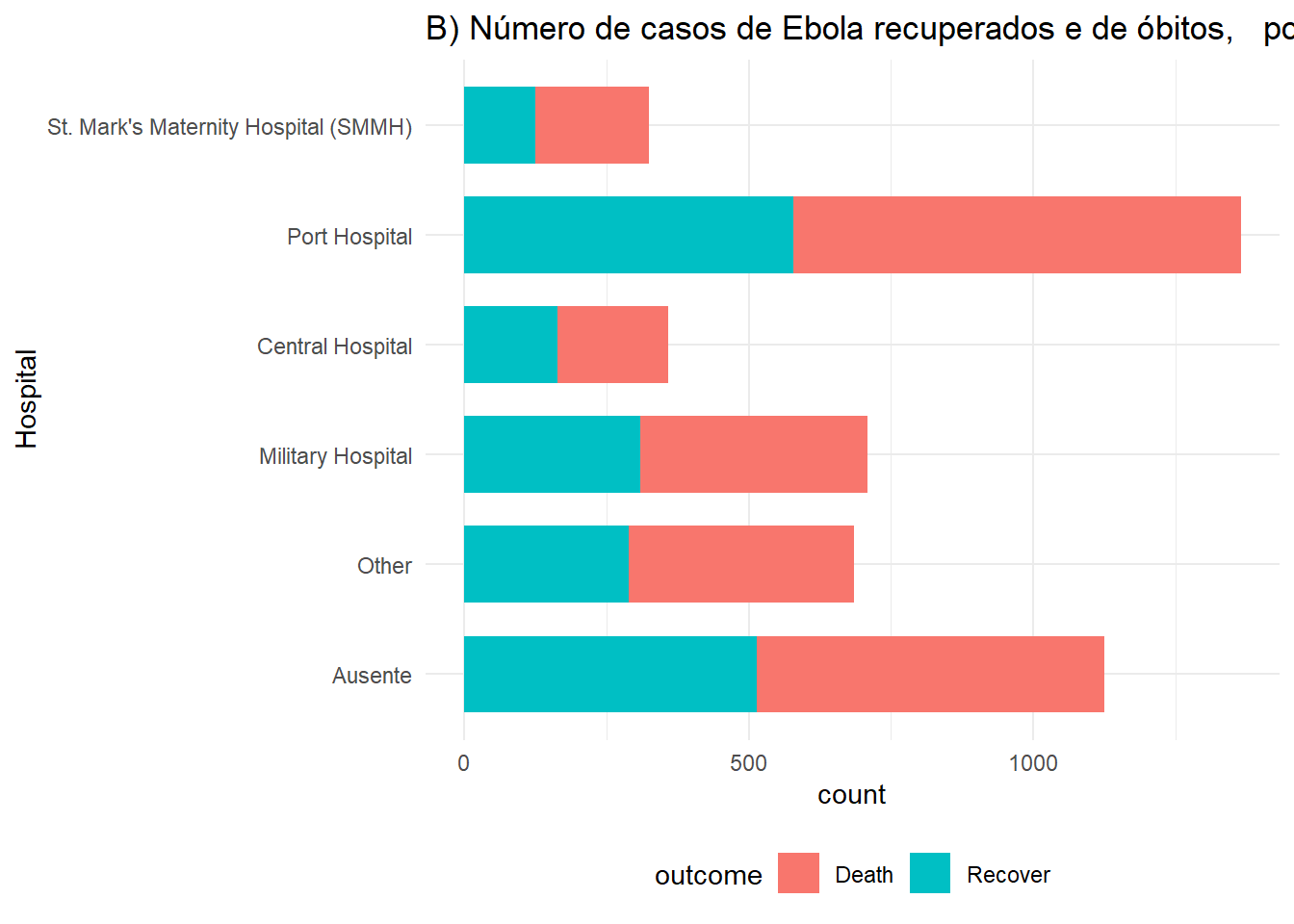
# B) Desfecho em todos os casos por hospital
ggplot(linelist %>% drop_na(outcome)) +
geom_bar(aes(y = fct_rev(hospital), fill = outcome), width = 0.7) +
theme_minimal()+
theme(legend.position = "bottom") +
labs(title = "B) Número de casos de Ebola recuperados e de óbitos, por hospital",
y = "Hospital")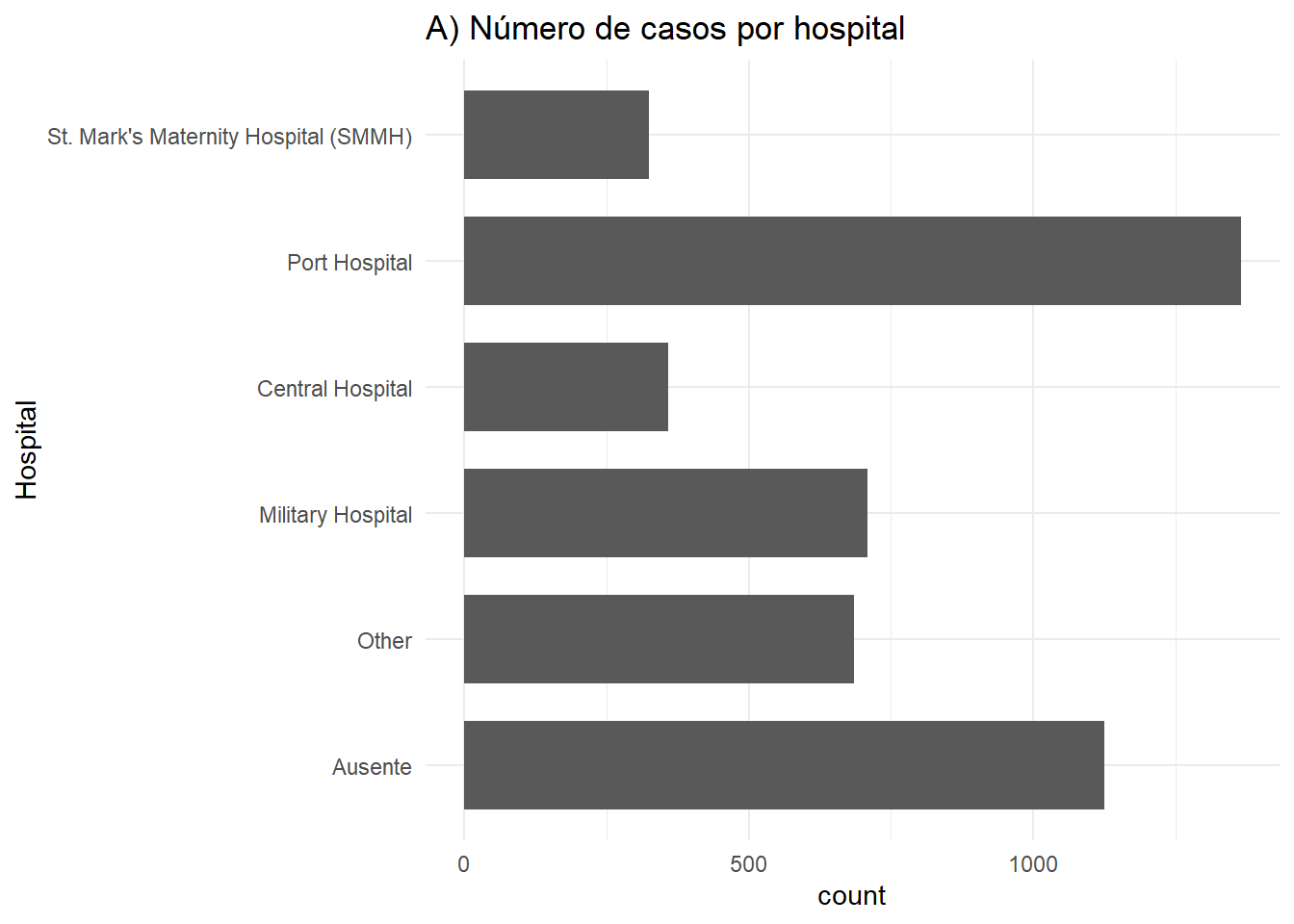
geom_col()
Utilize geom_col() se você quiser que a altura da barra (ou altura dos componentes da barra empilhados) reflita os valores pré-calculados que existem nos dados. Muitas vezes, estas são contagens sumárias ou “agregadas”, ou proporções.
Forneça atribuições de colunas para ambos eixos para geom_col(). Normalmente, sua coluna do eixo x é discreta e sua coluna do eixo y é numérica.
Digamos que temos este conjunto de dados “resultados”:
# A tibble: 2 × 3
outcome n proporcao
<chr> <int> <dbl>
1 Recuperado 796 43.8
2 Óbito 1022 56.2Abaixo está o código utilizando geom_col para criar gráficos de barras simples para mostrar a distribuição dos resultados dos pacientes com Ebola. Com o geom_col, tanto x como y precisam ser especificados. Aqui x é a variável categórica ao longo do eixo x, e y é a coluna de proporções geradas proporcao.
# Desfecho em todos os casos
ggplot(outcomes) +
geom_col(aes(x=outcome, y = proporcao)) +
labs(subtitle = "Número de casos recuperados e óbitos de Ebola")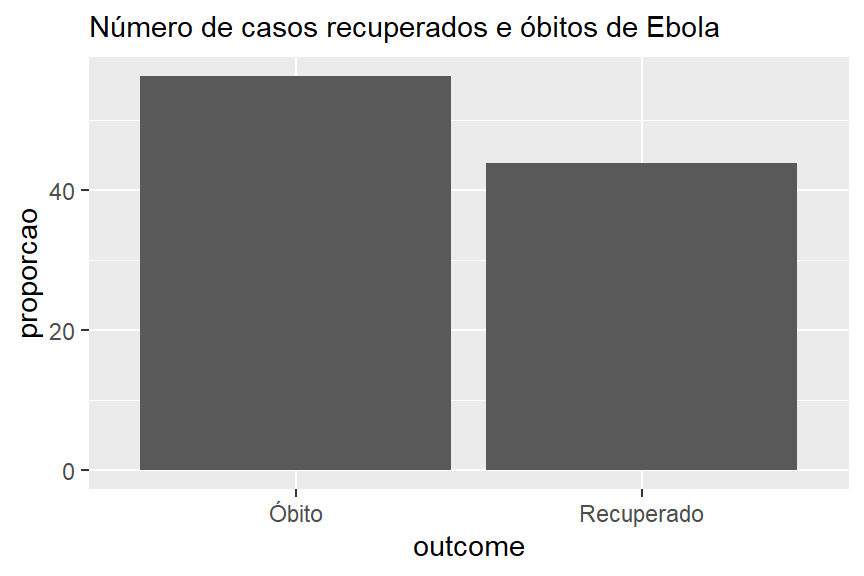
Para mostrarmos as detalhamentos por hospital, precisaríamos que nossa tabela contivesse mais informações e que estivesse em formato “longo”. Criamos esta tabela com as freqüências das categorias combinadas outcome (Desfecho) e hospital (ver página Agrupando dados para dicas de agrupamento).
outcomes2 <- linelist %>%
drop_na(outcome) %>%
count(hospital, outcome) %>% # obtém contagens para hospital e desfecho
group_by(hospital) %>% # Agrupa para que proporção esteja fora do total do hospital
mutate(proportion = n/sum(n)*100) # Calcula as proporções
head(outcomes2) # Veja uma prévia dos dados# A tibble: 6 × 4
# Groups: hospital [3]
hospital outcome n proportion
<fct> <chr> <int> <dbl>
1 St. Mark's Maternity Hospital (SMMH) Death 199 61.2
2 St. Mark's Maternity Hospital (SMMH) Recover 126 38.8
3 Port Hospital Death 785 57.6
4 Port Hospital Recover 579 42.4
5 Central Hospital Death 193 53.9
6 Central Hospital Recover 165 46.1Criamos então o ggplot com alguma formatação adicional:
-
Rotação do eixo: Trocamos o eixo com
coord_flip()para que pudéssemos ler os nomes dos hospitais. -
Colunas lado a lado: Acrescentou o argumento
position = "dodge"para que as barras de óbitos e recuperação sejam apresentadas lado a lado em vez de empilhadas. Note que as barras empilhadas são o padrão. - Largura da coluna: Largura especificada, de modo que as colunas são agora metade da largura normal.
-
Ordem das colunas: Inverteu a ordem das categorias no eixo y para que ‘Other’ (Outros) e ‘Missing’ (Faltantes) estejam na parte inferior, com
scale_x_discrete(limits=rev). Note que utilizamos isso em vez descale_y_discreteporque o hospital é indicado no argumento ‘x’ de ’aes()`, mesmo que visualmente esteja no eixo y. Fazemos isso porque ggplot parece apresentar categorias ao contrário, a menos que digamos lhe o contrário.
-
Outros detalhes: Etiquetas/títulos e cores adicionadas dentro de
labsescale_fill_colorrespectivamente.
# Desfecho em todos os casos por hospital
ggplot(outcomes2) +
geom_col(
mapping = aes(
x = proportion, # apresenta os dados calculados previamente
y = fct_rev(hospital), # reordenas os níveis do fator, colocando na base os desejados
fill = outcome), # empilhados por desfecho
width = 0.5)+ # barras mais finas (valores menores que 1)
theme_minimal() + # Tema mínimo
theme(legend.position = "bottom")+
labs(subtitle = "Número de casos recuperados e óbitos por Ebola, por hospital",
fill = "Desfecho", # título da legenda
y = "Contagem", # título do eixo y
x = "Hospital de admissão")+ # título do eixo x
scale_fill_manual( # escolhendo as cores manualmente
values = c("Death"= "#3B1c8C", # para óbito
"Recover" = "#21908D" )) # para recuperado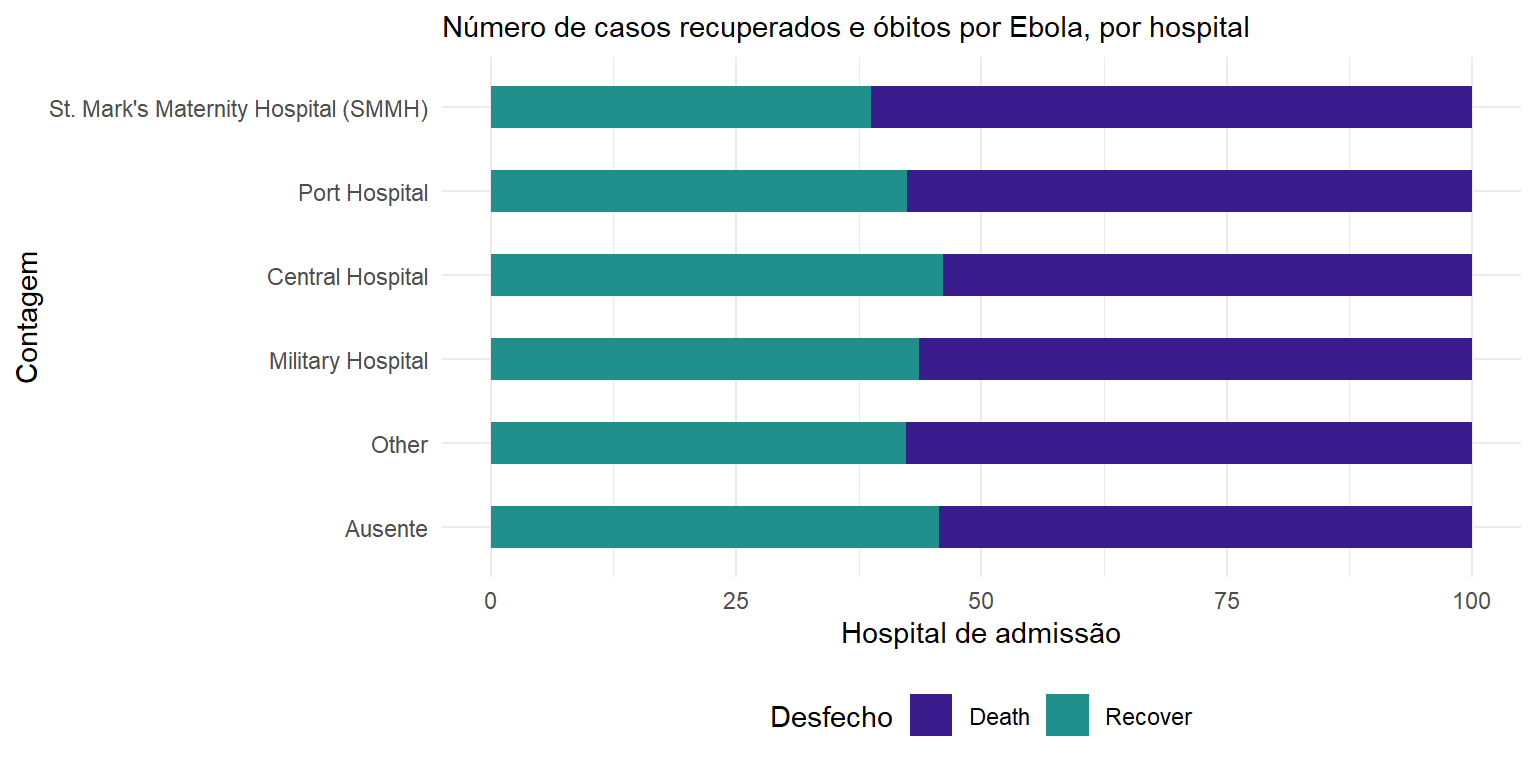
Note que as proporções são binárias, por isso podemos preferir abandonar a “recuperação” e apenas mostrar a proporção de quem morreu. Isto é apenas para fins ilustrativos.
Se utilizar geom_col() com dados de datas (por exemplo, uma epicurva a partir de dados agregados) - você vai querer ajustar o argumento width = (largura) para remover as linhas de “espaço” entre as barras. Se utilizar o conjunto de dados diário, ajuste width = 1. Se for semanal, ajuste width = 7. Os meses não são possíveis de serem visualizados dessa forma, porque cada mês tem um número de dias diferente.
geom_histogram()
Os histogramas podem parecer gráficos de barras, mas são distintos porque medem a distribuição de uma variável contínua. Não há espaços entre as “barras”, e apenas uma coluna é fornecida para geom_histogram(). Há argumentos específicos para histogramas como bin_width = e breaks = para especificar como os dados devem ser cdivididos em classes. A seção acima sobre dados contínuos e a página sobre Curvas Epidemiológicas fornecem detalhes adicionais.
30.14 Recursos
Há uma enorme quantidade de ajuda online, especialmente com o ggplot. Veja: