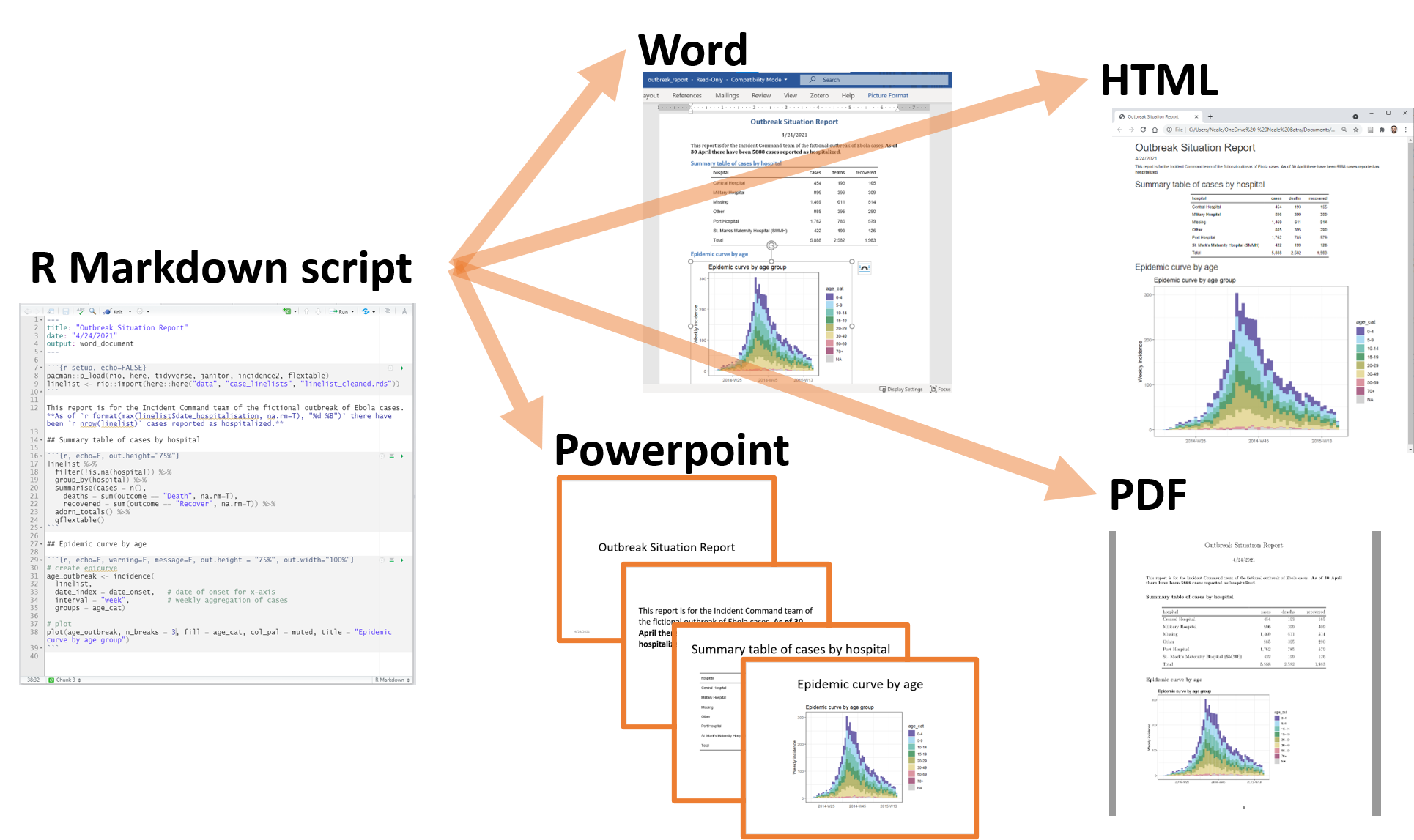
40 Production de rapports avec R Markdown
R Markdown est un outil largement utilisé pour créer des résultats automatisés, reproductibles et prêts à être partagés, tels que des rapports. Il peut générer des sorties statiques ou interactives, aux formats Word, PDF, HTML, Powerpoint et autres.
Un script R Markdown associe le code R et le texte de sorte que le script devient votre document de sortie. Vous pouvez créer un document formaté complet, y compris un texte narratif (qui peut être dynamique pour changer en fonction de vos données), des tableaux, des figures, des puces/chiffres, des bibliographies, etc.
Ces documents peuvent être produits pour être mis à jour régulièrement (par exemple, des rapports de surveillance quotidiens) et/ou être exécutés sur des sous-ensembles de données (par exemple, des rapports pour chaque compétence).
D’autres pages de ce manuel traitent de ce sujet :
- La page Organisation des rapports de routine montre comment organiser la production de vos rapports avec des dossiers horodatés générés automatiquement.
- La page Tableaux de bord avec R Markdown explique comment formater un rapport R Markdown en tant que tableau de bord.
Il convient de noter que le projet R4Epis a développé des modèles de scripts R Markdown pour les épidémies et les scénarios d’enquête les plus courants rencontrés sur les sites des projets MSF.
40.1 Préparation
Contexte du R Markdown
Pour expliquer certains des concepts et des “packages” impliqués :
- Markdown est un “langage” qui vous permet d’écrire un document en texte brut, qui peut être converti en HTML et autres formats. Il n’est pas spécifique à R. Les fichiers écrits en Markdown ont une extension ‘.md’.
- R Markdown : est une variante de markdown qui est spécifique à R - il vous permet d’écrire un document en utilisant markdown pour produire du texte et pour incorporer du code R et afficher leurs sorties. Les fichiers R Markdown ont une extension ‘.Rmd’.
- rmarkdown - le “package” : Il est utilisé par R pour convertir le fichier .Rmd en la sortie souhaitée. Il se concentre sur la conversion de la syntaxe markdown (texte), nous avons donc également besoin de…
- knitr : Ce “package” R lira les morceaux de code, les exécutera et les ” tricotera” dans le document. C’est ainsi que les tableaux et les graphiques sont inclus à côté du texte.
- Pandoc : Enfin, pandoc convertit le résultat en Word/PDF/Powerpoint, etc. Il s’agit d’un logiciel distinct de R mais qui est installé automatiquement avec RStudio.
En résumé, le processus qui se déroule en arrière-plan (vous n’avez pas besoin de connaître toutes ces étapes !) consiste à transmettre le fichier .Rmd à knitr, qui exécute les morceaux de code R et crée un nouveau fichier .md (markdown) comprenant le code R et son résultat rendu. Le fichier .md est ensuite traité par pandoc pour créer le produit fini : un document Microsoft Word, un fichier HTML, un document Powerpoint, un PDF, etc.

(source: https://rmarkdown.rstudio.com/authoring_quick_tour.html):
Installation
Pour créer une sortie R Markdown, vous devez avoir installé les éléments suivants :
- Le package rmarkdown (knitr sera également installé automatiquement).
- Pandoc, qui doit être installé avec RStudio. Si vous n’utilisez pas RStudio, vous pouvez télécharger Pandoc ici.
- Si vous souhaitez générer une sortie PDF (un peu plus délicat), vous devrez installer LaTeX. Pour les utilisateurs de R Markdown qui n’ont pas installé LaTeX auparavant, nous vous recommandons d’installer TinyTeX. Vous pouvez utiliser les commandes suivantes:
pacman::p_load(tinytex) # installer le package tinytex
tinytex::install_tinytex() # commande R pour installer TinyTeX 40.2 Démarrage
Installer le package R rmarkdown
Installez le “package” R rmarkdown. Dans ce manuel, nous mettons l’accent sur la fonction p_load() du “package” pacman, qui installe le (ou une liste de) “package (s)” que si nécessaire (uniquement si le package n’est pas déjà installé) et le charge pour l’utiliser . On peut également charger des “packages” avec library() à partir de R base. Voir la page sur R - les bases pour plus d’informations sur les packages R.
pacman::p_load(rmarkdown)Créer un nouveau fichier Rmd
Dans RStudio, ouvrez un nouveau fichier R markdown, en commençant par ‘File’, puis ‘New file’ et enfin ‘R markdown…’.
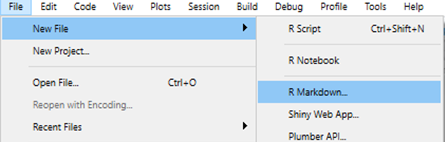
R Studio vous donnera quelques options de sortie parmi lesquelles choisir. Dans l’exemple ci-dessous, nous sélectionnons “HTML” car nous voulons créer un document HTML. Le titre et les noms des auteurs ne sont pas importants. Si le type de document de sortie que vous voulez n’est pas l’un de ceux-là, ne vous inquiétez pas - vous pouvez choisir n’importe lequel et le changer dans le script plus tard.
Cela ouvrira un nouveau script .Rmd.
Important à savoir
Le répertoire de travail
Le répertoire de travail d’un fichier markdown est l’endroit où le fichier Rmd lui-même est enregistré. Par exemple, si le projet R se trouve dans ~/Documents/projetX et que le fichier Rmd lui-même se trouve dans un sous-dossier ~/Documents/projetX/markdownfiles/markdown.Rmd, le code read.csv("data.csv") dans le markdown cherchera un fichier csv dans le dossier markdownfiles, et non dans le dossier racine du projet où les scripts dans les projets chercheraient normalement automatiquement.
Pour faire référence à des fichiers ailleurs, vous devrez soit utiliser le chemin complet du fichier, soit utiliser le package here. Le package here définit le répertoire de travail comme étant le dossier racine du projet R et est expliqué en détail dans les pages Projets R et Importer et exporter des données de ce manuel. Par exemple, pour importer un fichier appelé “data.csv” depuis le dossier projectX, le code serait import(here("data.csv")).
Notez que l’utilisation de setwd() dans les scripts R Markdown n’est pas recommandée – elle ne s’applique qu’au morceau de code dans lequel elle est écrite.
Travailler sur un disque plutôt que sur votre ordinateur
Parce que R Markdown peut rencontrer des problèmes avec pandoc lorsqu’il est exécuté sur un serveur de stockage partagé, il est recommandé que votre dossier soit sur votre machine locale, par exemple dans un projet dans “Mes Documents”. Si vous utilisez Git (fortement recommandé !), cela vous sera familier. Pour plus de détails, consultez les pages du manuel intitulées R sur les lecteurs réseau et Erreurs fréquentes.
40.3 Les composantes du R Markdown
Un document R Markdown peut être édité dans RStudio tout comme un script R standard. Lorsque vous démarrez un nouveau script R Markdown, RStudio essaie d’être utile en affichant un modèle qui explique les différentes sections d’un script R Markdown.
Ce qui suit est ce qui apparaît lorsque vous démarrez un nouveau script Rmd destiné à produire une sortie HTML (comme dans la section précédente).
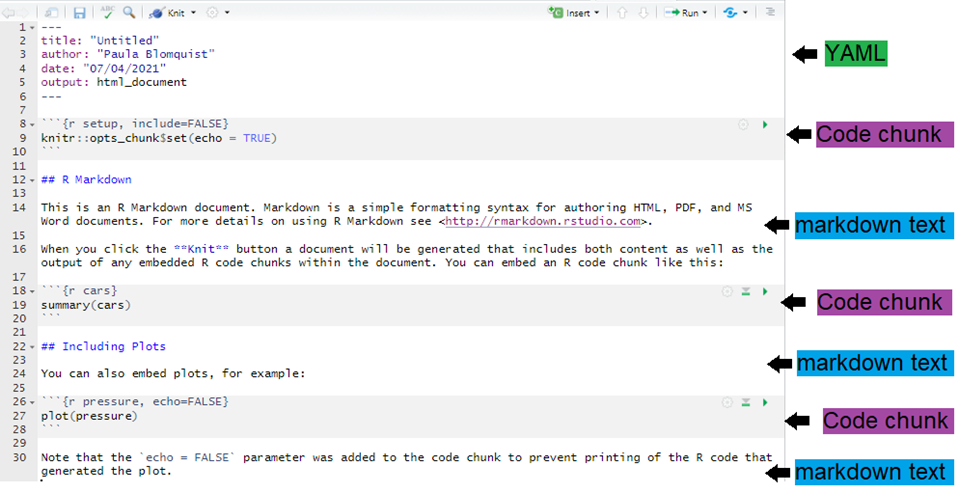
Comme vous pouvez le constater, un fichier Rmd comporte trois éléments de base : YAML, le texte Markdown et les morceaux de code R.
Ces éléments vont créer et devenir votre document de sortie. Voir le diagramme ci-dessous :
![]()
Métadonnées YAML
Appelées “métadonnées YAML” ou simplement “YAML”, elles se trouvent en haut du document R Markdown. Cette section du script indique à votre fichier Rmd le type de sortie à produire, les préférences de formatage et d’autres métadonnées telles que le titre du document, l’auteur et la date. Il existe d’autres utilisations qui ne sont pas mentionnées ici (mais auxquelles il est fait référence dans la section “Produire une sortie”). Notez que l’indentation est importante ; les tabulations ne sont pas acceptées, mais les espaces le sont.
Cette section doit commencer par une ligne contenant seulement trois tirets --- et doit se terminer par une ligne contenant seulement trois tirets ---. Les paramètres YAML se présentent sous forme de paires key:value. L’emplacement des deux points dans YAML est important : les paires key:value sont séparées par des deux points (et non par des signes égaux !).
Le fichier YAML doit commencer par les métadonnées du document. L’ordre de ces paramètres YAML primaires (non indentés) n’a pas d’importance. Par exemple :
title: "Mon document"
author: "Moi"
date: "2024-09-18"Vous pouvez utiliser du code R dans des valeurs YAML en l’écrivant en tant que code en ligne (précédé de r dans les crochets arrière) mais aussi entre guillemets (voir l’exemple ci-dessus pour date:).
Dans l’image ci-dessus, parce que nous avons cliqué que notre sortie par défaut serait un fichier html, nous pouvons voir que le YAML dit output: html_document. Cependant, nous pouvons aussi changer cela pour dire powerpoint_presentation ou word_document ou même pdf_document.
Texte
Il s’agit de la narration de votre document, y compris les titres et les en-têtes. Il est écrit dans le langage “markdown”, qui est utilisé dans de nombreux logiciels différents.
Vous trouverez ci-dessous les principales façons d’écrire ce texte. Vous trouverez une documentation plus complète sur l’antisèche R Markdown sur le site Web de RStudio.
Nouvelles lignes
Dans le format R Markdown, pour aller à une nouvelle ligne, saisissez deux espaces à la fin de la ligne précédente, puis appuyez sur Entrée/Retour.
Police
Entourez votre texte normal de ces caractères pour modifier la façon dont il apparaît dans le fichier de sortie.
- Caractères de soulignement (
_text_) ou astérisque simple (*text*) pour italiciser. - Double astérisque (
**text**) pour mettre le texte en gras. - Des “quotes” inversés (
text) pour afficher le texte sous forme de code.
L’apparence réelle de la police peut être définie en utilisant des modèles spécifiques (spécifiés dans les métadonnées YAML ; voir l’exemple des onglets).
Couleur
Il n’existe pas de mécanisme simple pour modifier la couleur du texte dans R Markdown. Une solution de contournement, si votre fichier de sortie est un fichier HTML, consiste à ajouter une ligne HTML dans le texte Markdown. Le code HTML ci-dessous imprimera une ligne de texte en rouge gras.
<span style="color: red;">**_DANGER:_** Ceci est un avertissement.</span> DANGER: Ceci est un avertissement.
Titres et en-têtes
Un symbole de hachage dans une partie de texte d’un script R Markdown crée un titre. C’est différent d’un morceau de code R dans le script, dans lequel un symbole de hachage est un mécanisme pour commenter/annoter/désactiver, comme dans un script R normal.
Différents niveaux de titre sont établis avec différents nombres de symboles de hachage au début d’une nouvelle ligne. Un symbole de hachage est un titre ou une rubrique primaire. Deux symboles de hachage correspondent à un sous-titre (deuxième niveau). Les titres de troisième et quatrième niveaux peuvent être établis avec un nombre croissant de symboles de hachage.
# Titre (Titre 1)
## Sous-titre (Titre 2)
### Sous-sous-titre (Titre 3)Puces et numérotation
Utilisez des astérisques (*) pour créer une liste de puces. Terminez la phrase précédente, saisissez deux espaces, tapez sur Entrée/Retour deux fois, puis commencez vos puces. Insérez un espace entre l’astérisque et le texte de votre puce. Après chaque puce, saisissez deux espaces, puis appuyez sur la touche Entrée/Retour. Les sous-puces fonctionnent de la même manière, mais sont en retrait. Les numérotations fonctionnent de la même manière, mais au lieu d’un astérisque, écrivez 1), 2), etc. Voici à quoi pourrait ressembler le texte de votre script R Markdown.
Voici mes puces (il y a deux espaces après ce deux-points):
* Puce 1 (suivi de deux espaces et Entrée/Retour)
* Puce 2 (suivi de deux espaces et Entrée/Retour)
* Sous-puce 1 (suivi de deux espaces et Entrée/Retour)
* Sous-puce 2 (suivi de deux espaces et Entrée/Retour)
Commenter du texte
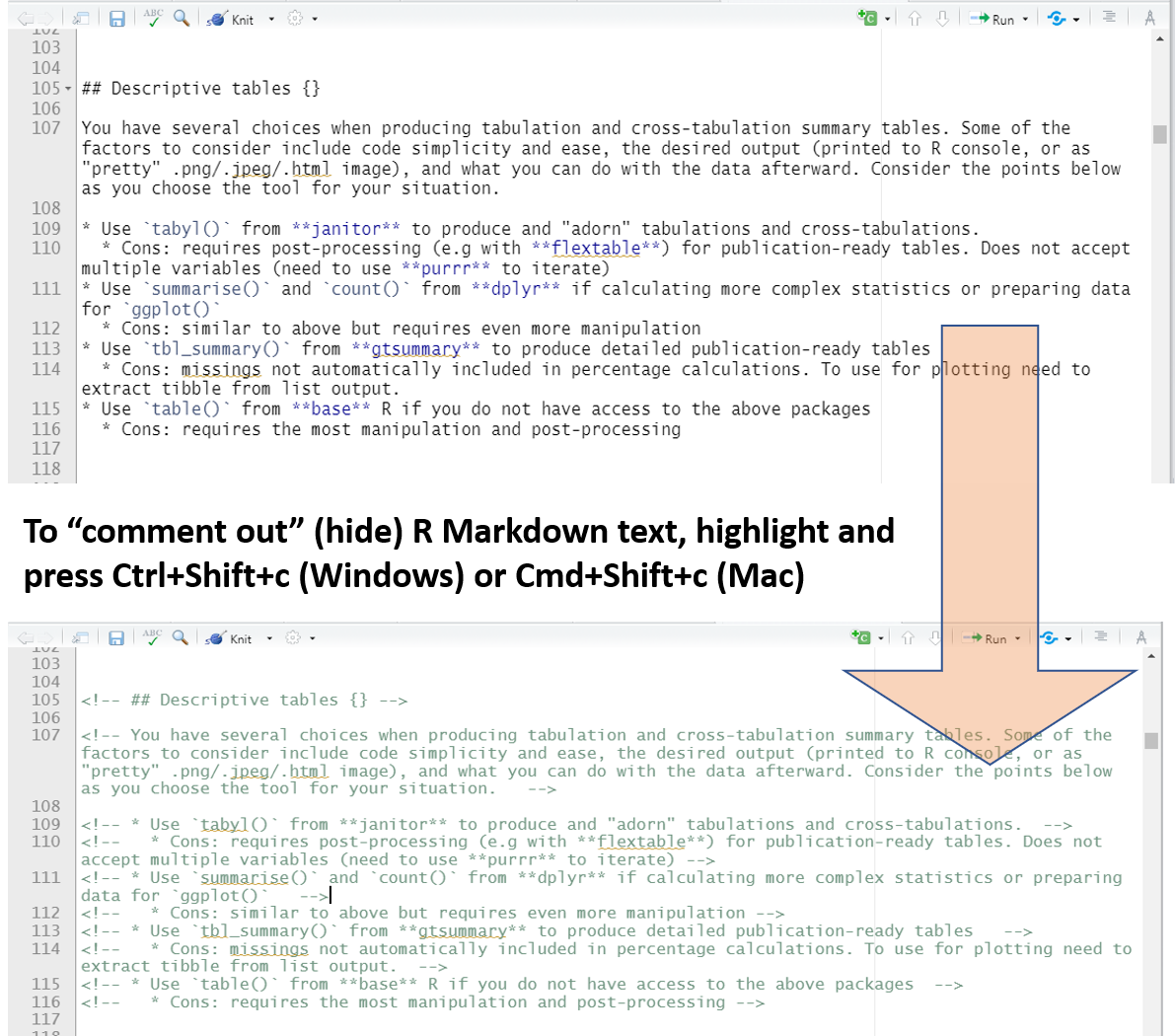
Vous pouvez “commenter” du texte R Markdown de la même manière que vous pouvez utiliser le “#” pour commenter une ligne de code R dans un chunk R. Il suffit de mettre le texte en surbrillance et d’appuyer sur Ctrl+Shift+c (Cmd+Shift+c pour Mac). Le texte sera entouré de flèches et deviendra vert. Il n’apparaîtra pas dans votre résultat.
Morceaux de code
Les sections du script qui sont dédiées à l’exécution du code R sont appelées “chunks”. C’est là que vous pouvez charger des “packages”, importer des données et effectuer la gestion et la visualisation des données. Il peut y avoir de nombreux “chunks” de code (mettez en autant qu’il en faut pour un code plus lisible et comprehensible), ils peuvent donc vous aider à organiser votre code R en parties, éventuellement entrecoupées de texte. Remarque : ces “chunks” auront une couleur de fond légèrement différente de celle de la partie narrative du document.
Chaque chunk s’ouvre sur une ligne qui commence par trois “quotes” inversés et des crochets qui contiennent les paramètres du chunk ({ }). Le chunk se termine par trois autres “quotes” inversés.
Vous pouvez créer un nouveau chunk en le tapant vous-même, en utilisant le raccourci clavier “Ctrl + Alt + i” (ou Cmd + Shift + r sur Mac), ou en cliquant sur l’icône verte “insérer un nouveau chunk de code” en haut de votre éditeur de script.
Quelques remarques sur le contenu des accolades { }:
- Ils commencent par ‘r’ pour indiquer que le nom du langage dans le chunk est R.
- Après le r, vous pouvez éventuellement écrire un “nom” de chunk – ceux-ci ne sont pas nécessaires mais peuvent vous aider à organiser votre travail. Notez que si vous nommez vos morceaux, vous devez TOUJOURS utiliser des noms uniques, sinon R se plaindra lorsque vous essaierez de compiler le rendu.
- Les accolades peuvent également inclure d’autres options, écrites comme
tag=value, telles que : -
eval = FALSEpour ne pas exécuter le code R -
echo = FALSEpour ne pas imprimer le code source R du chunk dans le document de sortie. -
warning = FALSEpour ne pas afficher les avertissements générés par le code R -
message = FALSEpour ne pas imprimer les messages produits par le code R. -
include =soit TRUE/FALSE si l’on veut inclure les sorties du chunk (par exemple les graphiques) dans le document. -
out.width =etout.height =- à fournir dans le styleout.width = "75%" -
fig.align = "center"ajuste l’alignement d’une figure sur la page. -
fig.show='hold'si votre chunk imprime plusieurs figures et que vous souhaitez qu’elles soient affichées les unes à côté des autres (à associer àout.width = c("33%", "67%"). Vous pouvez également définirfig.show='asis'pour les afficher en dessous du code qui les génère,'hide'pour les cacher, ou'animate'pour concaténer plusieurs d’entre elles dans une animation.` - Un en-tête de chunk doit être écrit en une ligne.
- Essayez d’éviter les points, les caractères de soulignement et les espaces. Utilisez des tirets ( - ) à la place si vous avez besoin d’un séparateur.
Lisez plus en détail les options knitr ici.
Certaines des options ci-dessus peuvent être configurées par clique-bouton en utilisant les boutons de réglage en haut à droite du chunk. Ici, vous pouvez spécifier quelles parties du chunk vous voulez que le document rendu inclue, à savoir le code, les sorties et les avertissements. Cela se traduira par des préférences écrites entre les crochets, par exemple echo=FALSE si vous spécifiez que vous voulez seulement afficher le rendu et non le code qui le produit ‘Show output only’.

Il y a aussi deux flèches en haut à droite de chaque chunk, qui sont utiles pour exécuter du code dans un chunk, ou tout le code des chunks précédents. Survolez-les pour voir ce qu’elles font.
Pour que les options globales soient appliquées à tous les chunks du script, vous pouvez les configurer dans le tout premier chunk de code R du script. Par exemple, pour que seules les sorties soient affichées pour chaque chunk de code et non le code lui-même, vous pouvez inclure cette commande dans le chunk de code R :
knitr::opts_chunk$set(echo = FALSE) Inclure du code R dans la partie Texte du Markdown
Vous pouvez également inclure un minimum de code R dans le corps du texte de votre document Markdown en utilisant les “quotes” inversés. Dans les “quotes” inversés, commencez le code par “r” et un espace, afin que RStudio sache qu’il doit évaluer le code en tant que code R. Voir l’exemple ci-dessous.
L’exemple ci-dessous montre plusieurs niveaux de titres, des puces, et utilise du code R pour la date actuelle (Sys.Date()) pour l’évaluer en une date imprimée.
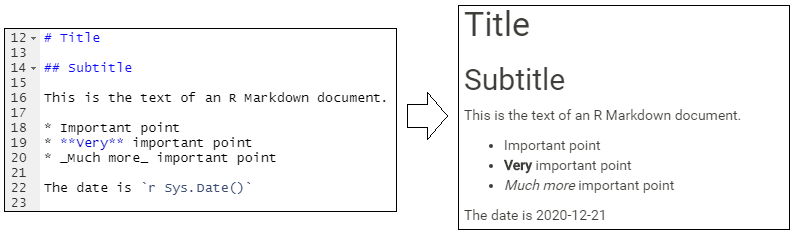
L’exemple ci-dessus est simple (affichage de la date actuelle), mais en utilisant la même syntaxe, vous pouvez afficher des valeurs produites par un code R plus complexe (par exemple, pour calculer le min, la médiane, le max d’une colonne). Vous pouvez également intégrer des objets R ou des valeurs qui ont été créés dans des morceaux de code R plus tôt dans le script.
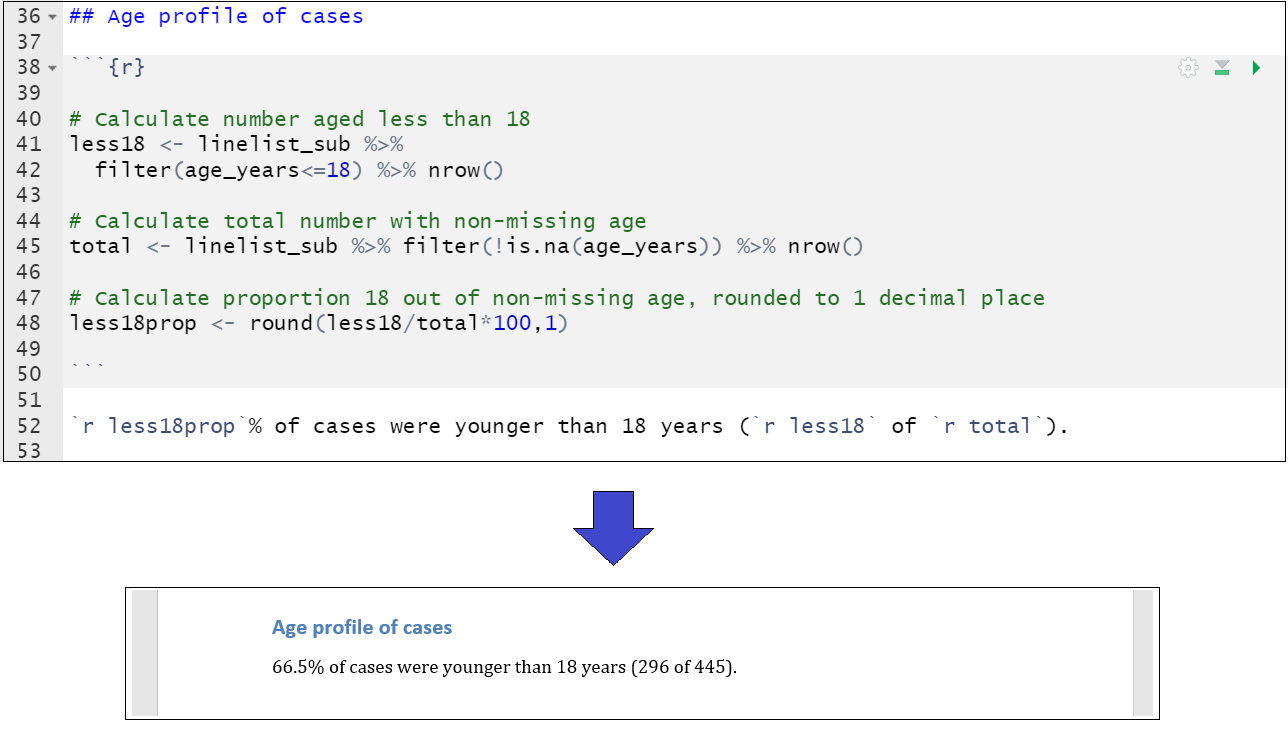
Par exemple, le script ci-dessous calcule la proportion de cas âgés de moins de 18 ans, en utilisant les fonctions tidyverse, et crée les objets less18, total, et less18prop. Cette valeur dynamique est insérée dans le texte suivant. Nous voyons à quoi cela ressemble lorsqu’il est rendu dans un document Word.
Images
Vous pouvez inclure des images dans votre document R Markdown en utilisant l’une des méthodes suivantes:
 Si la première méthode ne marche pas, esssayez d’utiliser: knitr::include_graphics()
knitr::include_graphics("path/to/image.png")Rappelez-vous, votre chemin de fichier pourrait être écrit en utilisant le package. here
knitr::include_graphics(here::here("path", "to", "image.png"))Tables
Créez un tableau en utilisant des traits d’union ( - ) et des barres ( | ). Le nombre de traits d’union avant/entre les barres permet de déterminer le nombre d’espaces dans la cellule avant que le texte ne commence à se positionner.
Column 1 |Column 2 |Column 3
---------|----------|--------
Cell A |Cell B |Cell C
Cell D |Cell E |Cell FLe code ci-dessus produit le tableau ci-dessous :
| Column 1 | Column 2 | Column 3 |
|---|---|---|
| Cell A | Cell B | Cell C |
| Cell D | Cell E | Cell F |
Sections à onglets
Pour les sorties HTML, on peut organiser les sections en “onglets”. Il suffit d’ajouter .tabset dans les accolades { } qui sont ouvertes juste après le titre de la section. Tous les sous-titres situés sous ce titre (jusqu’à un autre titre de même niveau) apparaîtront sous forme d’onglets sur lesquels l’utilisateur pourra cliquer. En savoir plus ici
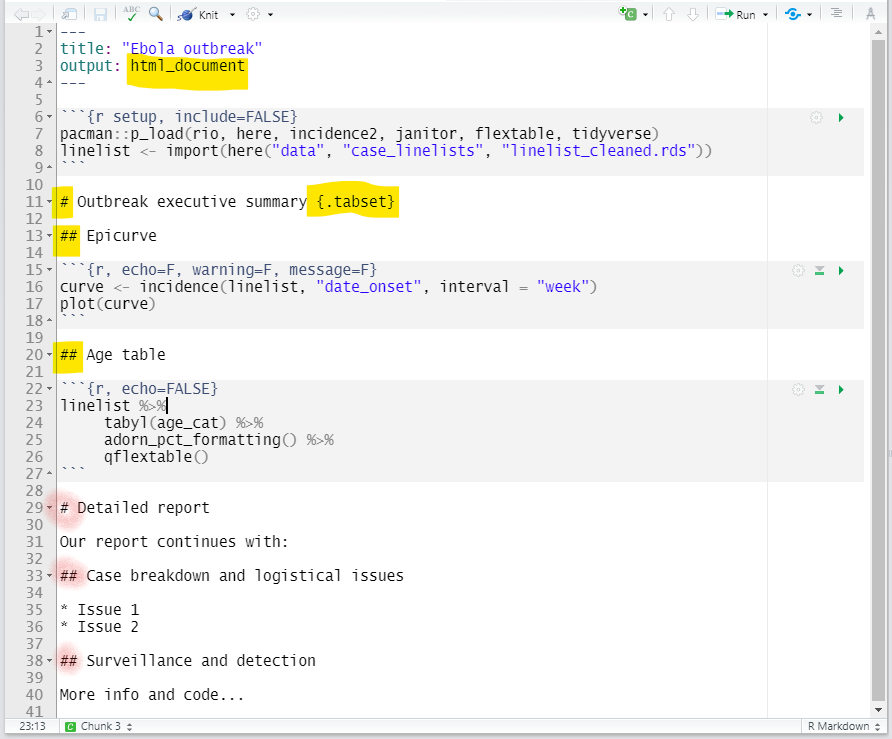
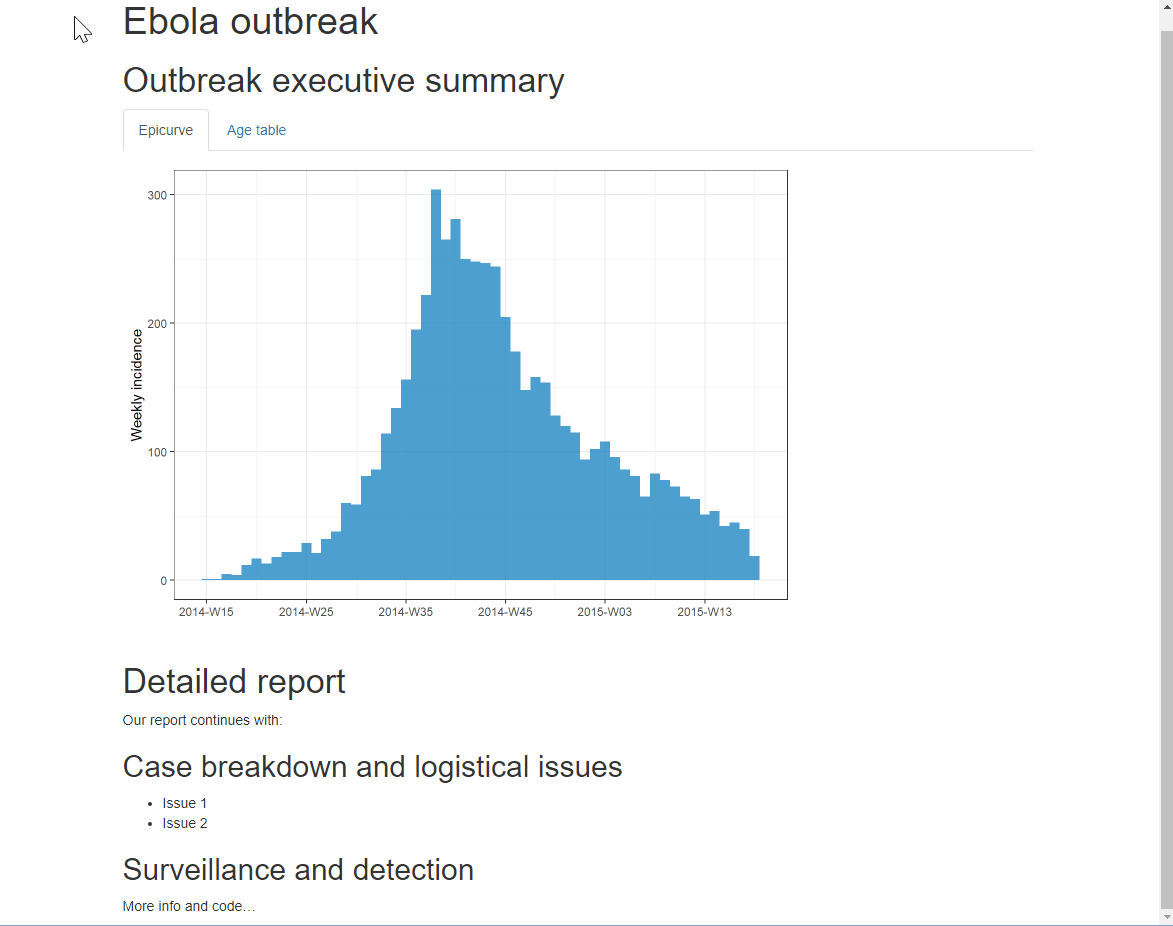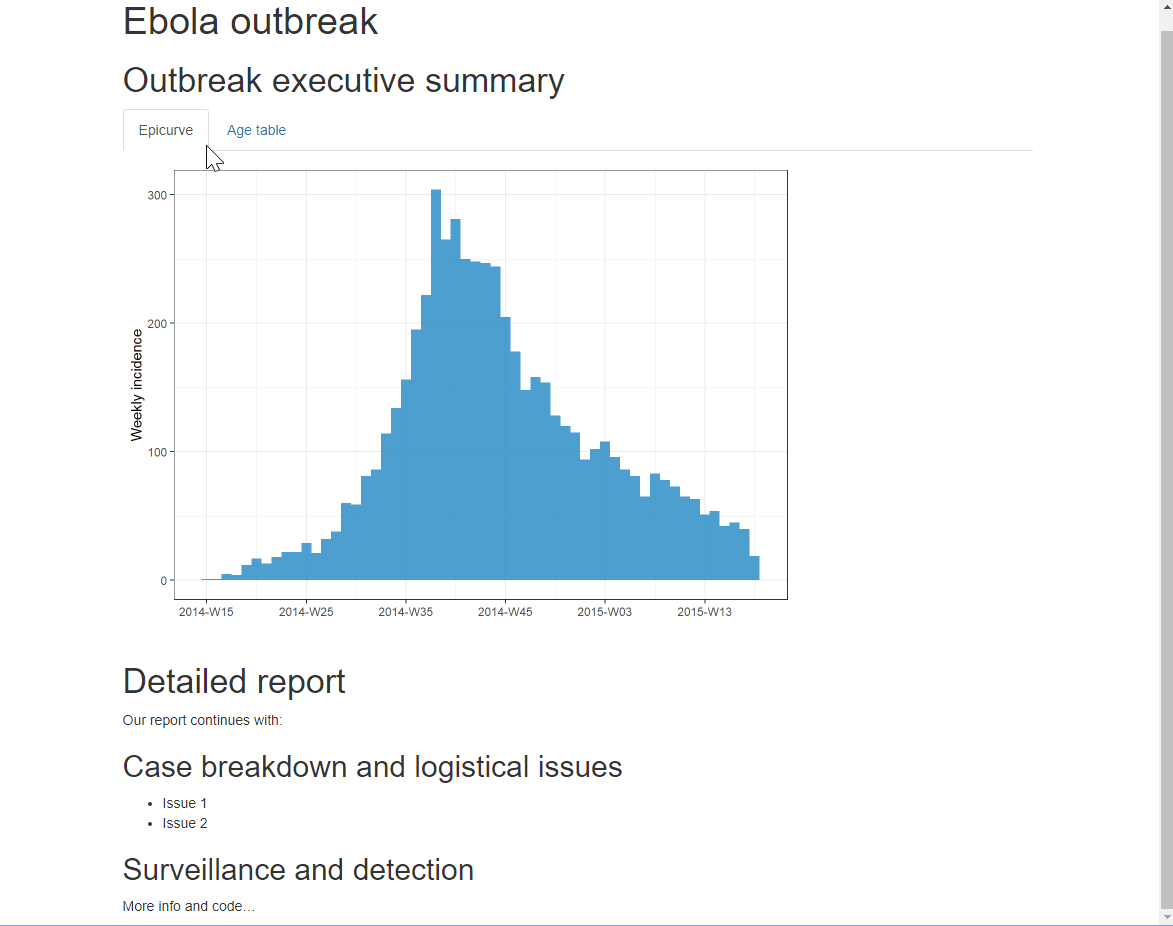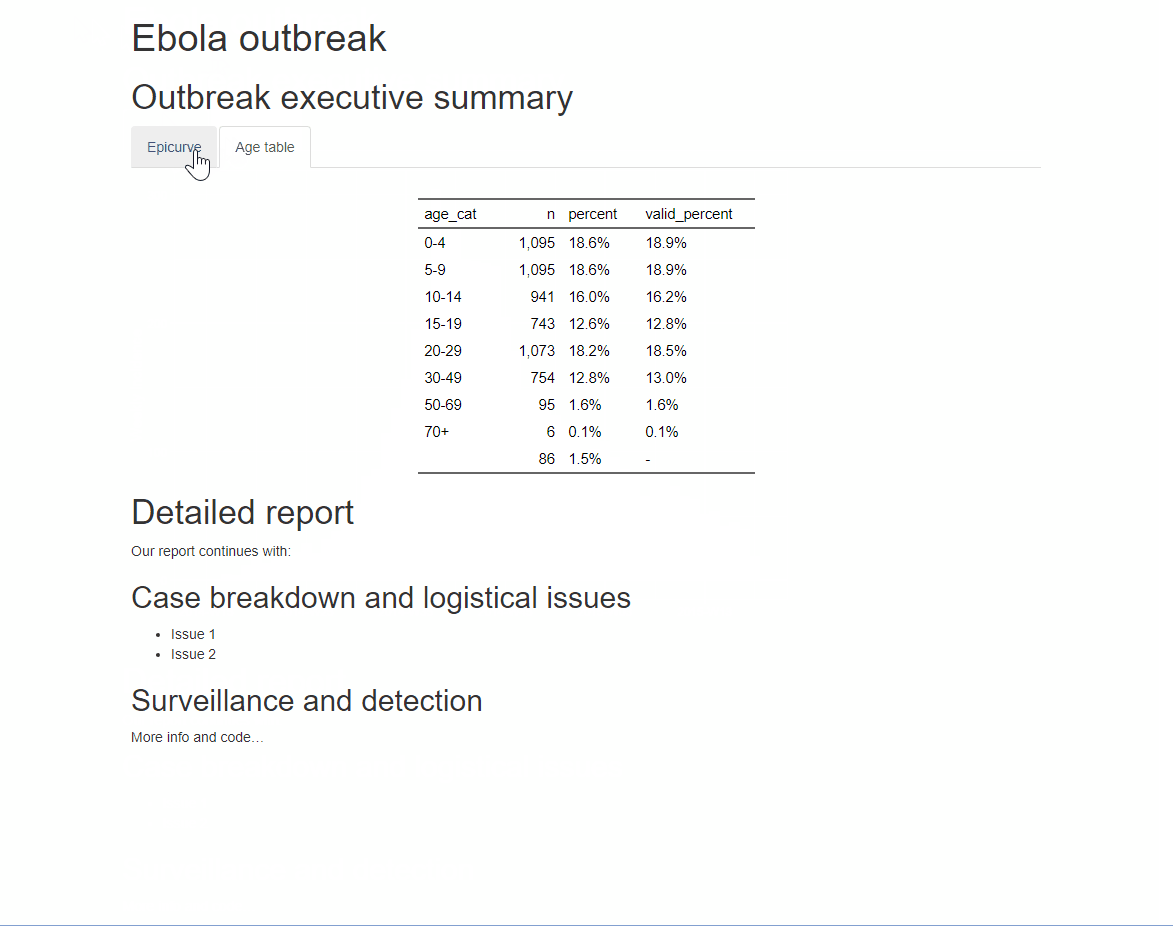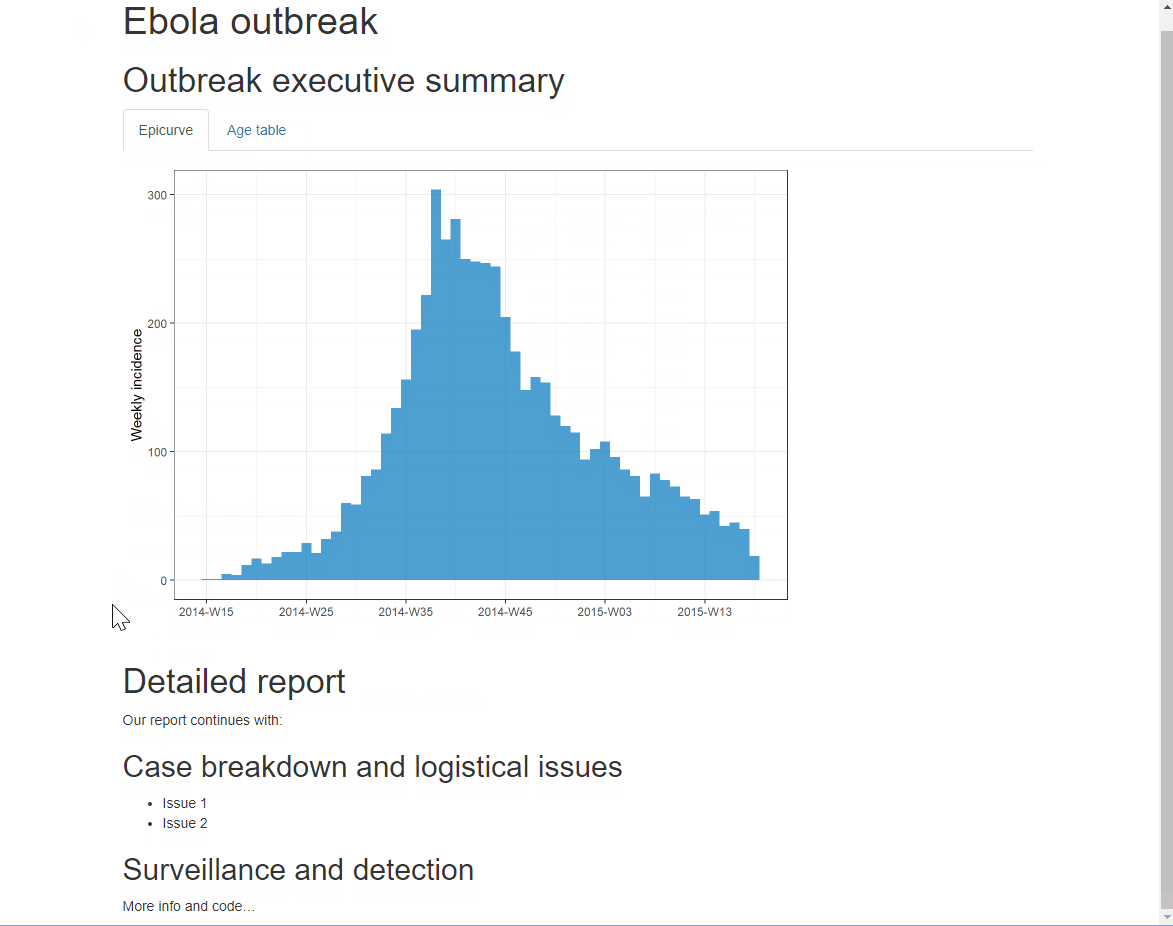
Vous pouvez ajouter une option supplémentaire .tabset-pills après .tabset pour donner aux onglets eux-mêmes un aspect plus esthétique avec un fond en noir.
40.4 Structure du fichier R Markdown
Il existe plusieurs façons de structurer votre fichier R Markdown et les scripts R associés. Chacune présente des avantages et des inconvénients :
-
R Markdown autonome - tout ce qui est nécessaire pour le rapport est importé ou créé dans le même fichier R Markdown.
- Faire appel à (sourcer) d’autres fichiers - Vous pouvez exécuter des scripts R externes avec la commande
source()et utiliser leurs sorties dans le Rmd. - Scripts dépendant ou dérivé (“child script”) - un mécanisme alternatif pour la commande
source()
- Faire appel à (sourcer) d’autres fichiers - Vous pouvez exécuter des scripts R externes avec la commande
Utiliser un “runfile” - Exécuter des commandes dans un script R avant de rendre le Markdown R.
Rmd autonome
Pour un rapport relativement simple, on peut choisir d’organiser notre script R Markdown de manière à ce qu’il soit “autonome” et n’implique pas de scripts externes.
Tout ce dont on a besoin pour exécuter le script R Markdown est importé ou créé dans le fichier Rmd, y compris tous les morceaux de code et le chargement des “packages”. Cette approche “autonome” est appropriée lorsqu’on n’a pas besoin de faire beaucoup de traitement de données (par exemple, elle apporte un fichier de données propre ou semi-propre) et que le rendu du R Markdown ne prendra pas trop de temps.
Dans ce scénario, une organisation logique du script R Markdown pourrait être la suivante :
- Définir les options globales de knitr.
- Chargement des “packages”
- Importer les données
- Traiter les données
- Produire des résultats (tableaux, graphiques, etc.)
- Sauvegarder les résultats, le cas échéant (.csv, .png, etc.)
Faire appel à (sourcer) d’autres fichiers
Une variante de l’approche “autonome” consiste à faire en sorte que les morceaux de code R Markdown “sourcent” (exécutent) d’autres scripts R. Cela peut rendre votre script R Markdown moins encombré, plus simple et plus facile à organiser. Cela peut rendre votre script R Markdown moins encombré, plus simple et plus facile à organiser. Elle peut également être utile si vous souhaitez afficher les chiffres finaux au début du rapport. Dans cette approche, le script R Markdown final combine simplement les sorties prétraitées dans un document.
Une façon de le faire est de fournir les scripts R (chemin et nom de fichier avec extension) à la commande base R source().
source("your-script.R", local = knitr::knit_global())
# ou sys.source("your-script.R", envir = knitr::knit_global())Notez que lorsque vous utilisez source() dans le R Markdown, les fichiers externes seront toujours exécutés pendant le rendu de votre fichier Rmd. Par conséquent, chaque script est exécuté à chaque fois que vous rendez le rapport. Ainsi, le fait d’avoir ces commandes source() dans le R Markdown n’accélère pas votre temps d’exécution, et ne vous aide pas beaucoup à débloquer, puisque les erreurs produites seront toujours affichées lors de l’exécution du R Markdown.
Une alternative est d’utiliser l’option child = knitr.
Vous devez être conscient des différents environnements de R. Les objets créés dans un environnement ne seront pas nécessairement disponibles dans l’environnement utilisé par le Markdown R.
Runfile
Par exemple, vous pouvez charger les “packages”, charger et nettoyer les données, et même créer les graphiques d’intérêt avant render(). Ces étapes peuvent se produire dans le script R, ou dans d’autres scripts qui sont “sourcés”. Tant que ces commandes se produisent dans la même session RStudio et que les objets sont enregistrés dans l’environnement, les objets peuvent ensuite être appelés dans le contenu Rmd. Ensuite, le R markdown lui-même ne sera utilisé que pour l’étape finale - pour produire la sortie avec tous les objets prétraités. Il est beaucoup plus facile de débloquer si quelque chose dans le code ne va pas.
Cette approche implique l’utilisation du script R qui contient la ou les commandes render() pour pré-traiter les objets qui alimentent le balisage R.
Cette approche est utile pour les raisons suivantes :
- Des messages d’erreur plus informatifs - ces messages seront générés par le script R, et non par le Markdown R. Les erreurs du Markdown R ont tendance à vous indiquer que vous n’avez pas besoin de les corriger. Les erreurs du Markdown R ont tendance à vous indiquer quel “chunk” a un problème, mais ne vous diront pas quelle ligne.
- Le cas échéant, vous pouvez exécuter des étapes de traitement longues avant la commande
render()- elles ne seront exécutées qu’une seule fois.
Dans l’exemple ci-dessous, nous avons un script R séparé dans lequel nous pré-traitons un objet data dans l’environnement R, puis nous rendons le fichier “create_output.Rmd” en utilisant render().
data <- import("datafile.csv") %>% # Charger les données et les sauvegarder dans l'environnement
select(age, hospital, weight) # Sélectionner les colonnes d'interet
rmarkdown::render(input = "create_output.Rmd") # Creer le fichier Rmd Structure du dossier
Le flux de travail concerne également la structure globale des dossiers, par exemple un dossier “output” pour les documents et figures créés, et des dossiers “data” ou “inputs” pour les données nettoyées. Nous n’entrerons pas dans les détails ici, mais consultez la page Organisation des rapports de routine.
40.5 Produire le document
Vous pouvez produire le document de la manière suivante :
- Manuellement en appuyant sur le bouton “Knit” en haut de l’éditeur de script RStudio (rapide et facile).
- Exécuter la commande
render()(exécutée en dehors du script R Markdown)
Option 1: Bouton “Knit”
Une fois le fichier Rmd ouvert, appuyez sur l’icône/bouton “Knit” en haut du fichier.
R Studio affichera la progression dans un onglet “R Markdown” près de votre console R. Le document s’ouvrira automatiquement une fois terminé.
Le document sera enregistré dans le même dossier que votre script R markdown, et avec le même nom de fichier (à l’exception de l’extension). Ce n’est évidemment pas idéal pour le contrôle de version (il sera écrasé à chaque fois que vous cliquerez pour produire le fichier Rmd, à moins d’être déplacé manuellement), car vous devrez peut-être renommer le fichier vous-même (par exemple, ajouter une date).
C’est le bouton de raccourci de RStudio pour la fonction render() de rmarkdown. Cette approche n’est compatible qu’avec un fihcier R markdown autonome, où tous les composants nécessaires existent ou proviennent du fichier.
Option 2: Commande render()
Une autre façon de produire votre sortie R Markdown est d’exécuter la fonction render() (du “package” rmarkdown). Vous devez exécuter cette commande en dehors du script R Markdown - donc soit dans un script R séparé (souvent appelé “fichier d’exécution”), soit comme une commande autonome dans la Console R.
rmarkdown::render(input = "my_report.Rmd")Comme avec “knit”, les paramètres par défaut enregistreront la sortie Rmd dans le même dossier que le script Rmd, avec le même nom de fichier (à part l’extension de fichier). Par exemple, “mon_rapport.Rmd”, une fois exécuté, créera “mon_rapport.docx” si vous décider de sortir le fichier vers un document Word. Cependant, en utilisant render() vous avez la possibilité d’utiliser des paramètres différents. render() peut accepter des arguments tels que :
-
output_format =C’est le format de sortie vers lequel convertir (par exemple,"html_document","pdf_document","word_document", ou"all"). Vous pouvez également le spécifier dans le YAML à l’intérieur du script R Markdown. -
output_file =C’est le nom du fichier de sortie (et le chemin du fichier). Il peut être créé par des fonctions R telles quehere()oustr_glue(), comme illustré ci-dessous. -
output_dir =C’est un répertoire de sortie (dossier) pour enregistrer le fichier. Cela vous permet de choisir un autre répertoire que celui dans lequel le fichier Rmd est enregistré. -
output_options =Vous pouvez fournir une liste d’options qui remplaceront celles du script YAML (par exemple ) -
output_yaml =Vous pouvez fournir le chemin d’accès à un fichier .yml qui contient des spécifications YAML. -
params =Voir la section sur les paramètres ci-dessous. - Voir la liste complète ici
Par exemple, pour améliorer le contrôle de version, la commande suivante enregistre le fichier de sortie dans un sous-dossier “outputs”, avec la date du jour dans le nom du fichier. Pour créer le nom du fichier, la fonction str_glue() du paquet stringr est utilisée pour ‘coller’ ensemble des chaînes statiques (écrites en clair) avec du code R dynamique (écrit entre crochets). Par exemple, si nous sommes le 10 avril 2021, le nom du fichier ci-dessous sera “Report_2021-04-10.docx”. Voir la page sur Caractères et chaînes de caractères pour plus de détails sur str_glue().
rmarkdown::render(
input = "create_output.Rmd",
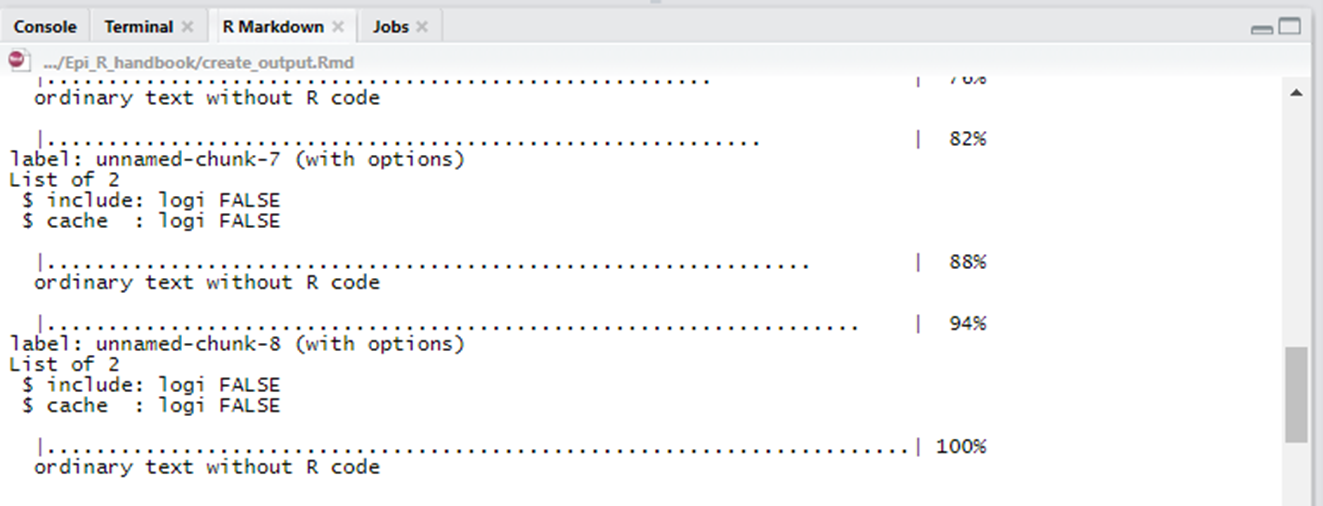
output_file = stringr::str_glue("outputs/Report_{Sys.Date()}.docx")) Au fur et à mesure de l’exécution du fichier Rmarkdown, la console RStudio vous montrera la progression du rendu jusqu’à 100%, et un message final pour indiquer que l’exécution est achevée.
Option 3 : package reportfactory
Le “package” R reportfactory offre une méthode alternative d’organisation et de compilation de rapports R Markdown adapté aux cas où vous exécutez des rapports régulièrement (par exemple, quotidiennement, hebdomadairement…). Il facilite la compilation de plusieurs fichiers R Markdown et l’organisation de leurs sorties. Essentiellement, il fournit une “usine” à partir de laquelle vous pouvez exécuter les rapports R Markdown, obtenir des dossiers automatiquement horodatés pour les fichiers de sortie, et avoir un contrôle de version “léger”.
Pour en savoir plus sur ce flux de travail, consultez la page Organisation des rapports de routine.
40.6 Rapports paramétrés
Vous pouvez utiliser le paramétrage pour rendre un rapport dynamique, de sorte qu’il puisse être exécuté avec des paramètres spécifiques (par exemple, une date ou un lieu spécifique ou avec certaines options d’exécution). Nous nous concentrons ci-dessous sur les principes de base, mais il existe d’autres détails en ligne sur les rapports paramétrés.
En utilisant la liste linéaire des cas Ebola comme exemple, disons que nous voulons exécuter un rapport de surveillance standard pour chaque hôpital chaque jour. Nous montrons comment on peut le faire en utilisant des paramètres.
Important: les rapports dynamiques sont également possibles sans la structure formelle des paramètres (sans params:), en utilisant de simples objets R dans un script R adjacent. Ceci est expliqué à la fin de cette section.
Définition des paramètres
Vous avez plusieurs options pour spécifier les valeurs des paramètres pour votre sortie R Markdown.
Option 1 : Définir les paramètres dans YAML
Editez le YAML pour inclure une option params:, avec des déclarations indentées pour chaque paramètre que vous voulez définir. Dans cet exemple, nous créons les paramètres date et hôpital, pour lesquels nous spécifions des valeurs. Ces valeurs sont susceptibles de changer à chaque fois que le rapport est exécuté. Si vous utilisez le bouton “Knit” pour produire le résultat, les paramètres auront ces valeurs par défaut. De même, si vous utilisez render(), les paramètres auront ces valeurs par défaut, sauf indication contraire dans la commande render().
---
title: Surveillance report
output: html_document
params:
date: 2021-04-10
hospital: Central Hospital
---En arrière-plan, ces valeurs de paramètres sont contenues dans une liste en lecture seule appelée params. Ainsi, vous pouvez insérer les valeurs des paramètres dans le code R comme vous le feriez pour un autre objet/valeur R dans votre environnement. Tapez simplement params$ suivi du nom du paramètre. Par exemple params$hospital pour représenter le nom de l’hôpital (“Central Hospital” par défaut).
Notez que les paramètres peuvent également contenir les valeurs vrai ou faux, et donc ceux-ci peuvent être inclus dans vos options knitr pour un “chunk” R. Par exemple, vous pouvez définir {r, eval=params$run} au lieu de {r, eval=FALSE}, et maintenant si le chunk s’exécute ou non dépend de la valeur d’un paramètre run:.
Notez que pour les paramètres qui sont des dates, ils seront entrés comme une chaîne. Donc, pour que params$date soit interprété dans le code R, il faudra probablement l’envelopper avec as.Date() ou une fonction similaire pour le convertir en classe Date.
Option 2 : Définir les paramètres dans render()
Comme mentionné plus haut, une alternative à l’appui sur le bouton “Knit” pour produire la sortie est d’exécuter la fonction render() à partir d’un script séparé. Dans ce dernier cas, vous pouvez spécifier les paramètres à utiliser dans ce rendu à l’argument params = de render().
Notez que toutes les valeurs de paramètres fournies ici vont écraser leurs valeurs par défaut si elles sont écrites dans le YAML. Nous écrivons les valeurs entre guillemets car dans ce cas, elles doivent être définies comme des valeurs de type chaîne de caractères.
La commande ci-dessous rend “surveillance_report.Rmd”, spécifie un nom de fichier de sortie dynamique et un dossier, et fournit une list() de deux paramètres et leurs valeurs à l’argument params =.
rmarkdown::render(
input = "surveillance_report.Rmd",
output_file = stringr::str_glue("outputs/Report_{Sys.Date()}.docx"),
params = list(date = "2021-04-10", hospital = "Central Hospital"))Option 3 : Définir les paramètres à l’aide d’une interface utilisateur graphique
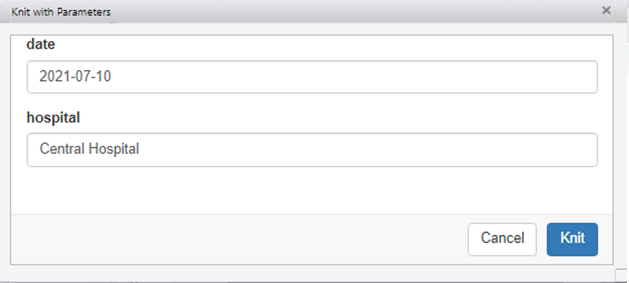
Pour une sensation plus interactive, vous pouvez également utiliser l’interface utilisateur graphique (GUI) pour sélectionner manuellement les valeurs des paramètres. Pour ce faire, nous pouvons cliquer sur le menu déroulant à côté du bouton “Knit” et choisir “Knit with parameters”.
Une fenêtre pop-up apparaît alors pour vous permettre de saisir les valeurs des paramètres établis dans le YAML du document.
Vous pouvez réaliser la même chose avec une commande render() en spécifiant params = "ask", comme démontré ci-dessous.
rmarkdown::render(
input = "surveillance_report.Rmd",
output_file = stringr::str_glue("outputs/Report_{Sys.Date()}.docx"),
params = “ask”)Toutefois, la saisie de valeurs dans cette fenêtre “pop-up” est sujette à des erreurs et à des fautes d’orthographe. Vous préférerez peut-être ajouter des restrictions aux valeurs qui peuvent être saisies dans les menus déroulants. Vous pouvez le faire en ajoutant dans le YAML plusieurs spécifications pour chaque entrée params: .
-
label:est le titre de ce menu déroulant particulier. -
value:est la valeur par défaut (de départ)
-
input:est défini surselectpour le menu déroulant
-
choices:Donne les valeurs éligibles dans le menu déroulant
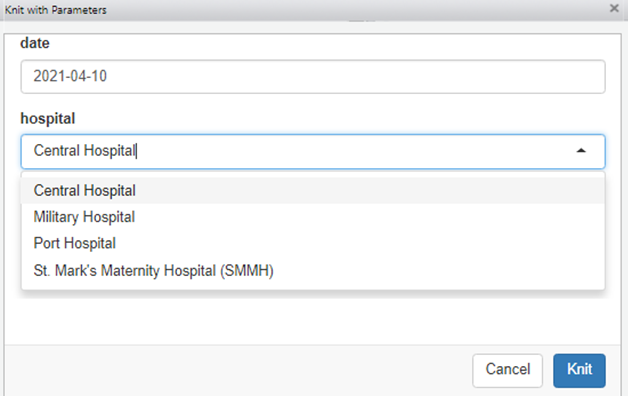
Ci-dessous, ces spécifications sont écrites pour le paramètre hôpital.
---
title: Surveillance report
output: html_document
params:
date: 2021-04-10
hospital:
label: “Town:”
value: Central Hospital
input: select
choices: [Central Hospital, Military Hospital, Port Hospital, St. Mark's Maternity Hospital (SMMH)]
---Lors de l’exécution du fichier (via le bouton “tricot avec des paramètres” ou par render()), la fenêtre pop-up aura des options déroulantes à sélectionner.
Exemple paramétré
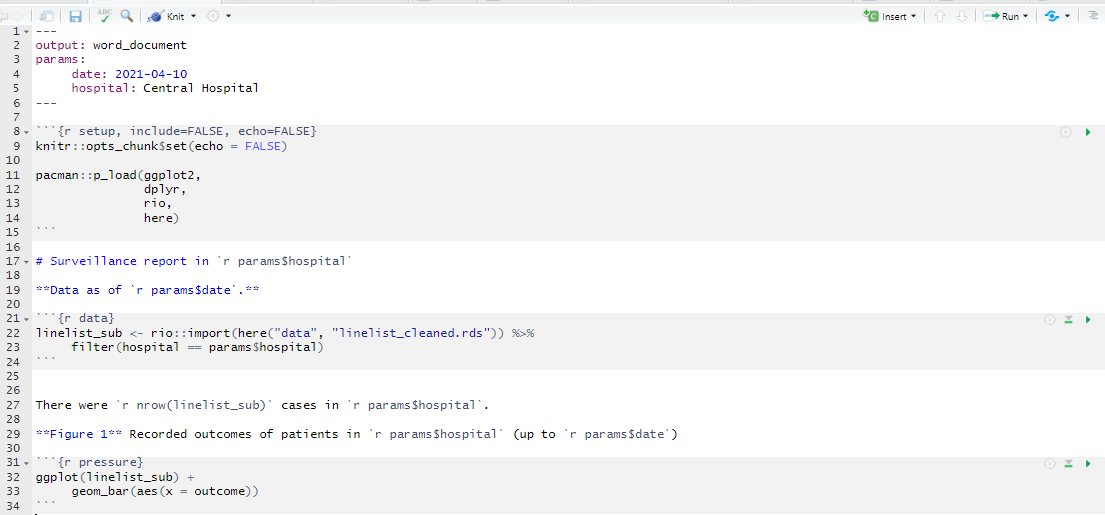
Le code suivant crée des paramètres pour date et ’hôpital, qui sont utilisés dans le R Markdown comme params$date et params$hospital, respectivement.
Dans le rapport qui en résulte, vous pouvez voir comment les données sont filtrées sur l’hôpital spécifique, et le titre du graphique fait référence à l’hôpital et à la date corrects. Nous utilisons ici le fichier “linelist_cleaned.rds”, mais il serait particulièrement approprié que la linelist elle-même comporte également un horodatage pour s’aligner sur la date paramétrée.
Lancer l’excecution produit la sortie finale avec la police et la mise en page par défaut.
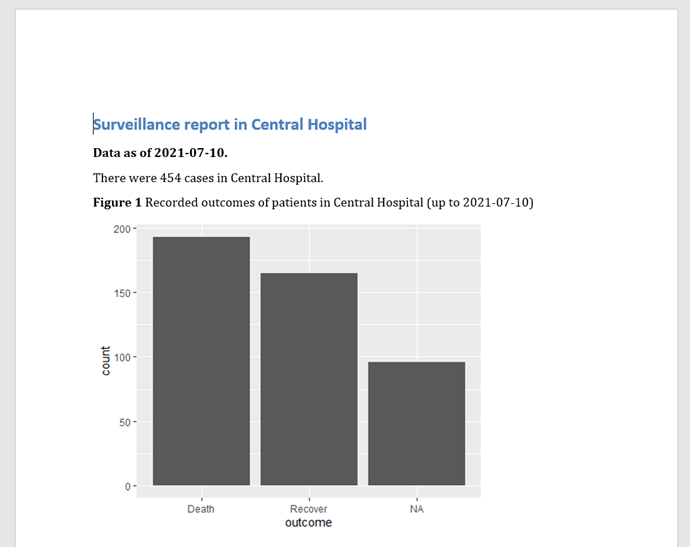
Paramétrisation sans params
Si vous exécutez un fichier R Markdown avec render() à partir d’un script séparé, vous pouvez en fait avoir le résultat du paramétrage sans utiliser la fonctionnalité params:.
Par exemple, dans le script R qui contient la commande render(), vous pouvez simplement définir hôpital et date comme deux objets R (valeurs) avant la commande render(). Dans le R Markdown, vous n’auriez pas besoin d’avoir une section params: dans le YAML, et nous ferions référence à l’objet date plutôt qu’à params$date et à hôpital plutôt qu’à params$hospital.
# Il s'agit d'un script R distinct du fichier R Markdown.
# définir les objets R
hospital <- "Central Hospital"
date <- "2021-04-10"
# Exécuter le fichier R markdown
rmarkdown::render(input = "create_output.Rmd") Suivre cette approche signifie que vous ne pouvez pas “Exécuter avec des paramètres”, utiliser l’interface graphique ou inclure des options d’exécution dans les paramètres. Cependant, elle permet de simplifier le code, ce qui peut être avantageux.
40.7 Rapports en boucle
Nous pouvons vouloir exécuter un rapport plusieurs fois, en faisant varier les paramètres d’entrée, afin de produire un rapport pour chaque juridiction/unité. Cela peut être fait en utilisant des outils d’itération, qui sont expliqués en détail dans la page Itération, boucles et listes. Les options comprennent le paquet purrr, ou l’utilisation d’une boucle for comme expliqué ci-dessous.
Ci-dessous, nous utilisons une simple boucle for pour générer un rapport de surveillance pour tous les hôpitaux d’intérêt. Ceci est fait avec une seule commande (au lieu de changer manuellement le paramètre de l’hôpital un par un). La commande permettant de rendre les rapports doit exister dans un script séparé sauf le rapport Rmd. Ce script contiendra également des objets définis à parcourir en boucle - la date du jour, et un vecteur de noms d’hôpitaux à parcourir en boucle.
hospitals <- c("Central Hospital",
"Military Hospital",
"Port Hospital",
"St. Mark's Maternity Hospital (SMMH)") Nous introduisons ensuite ces valeurs une par une dans la commande render() en utilisant une boucle, qui exécute la commande une fois pour chaque valeur du vecteur hospitals. La lettre i représente la position de l’index (1 à 4) de l’hôpital actuellement utilisé dans cette itération, tel que hospital_list[1] serait “Central Hospital”. Cette information est fournie à deux endroits dans la commande render() :
- Au nom du fichier, de sorte que le nom du fichier de la première itération, s’il est produit le 10 avril 2021, sera “Report_Central Hospital_2021-04-10.docx”, enregistré dans le sous-dossier “output” du répertoire de travail.
- Pour
params =de sorte que le Rmd utilise le nom de l’hôpital en interne chaque fois que la valeurparams$hospitalest appelée (par exemple pour filtrer l’ensemble de données sur l’hôpital particulier uniquement). Dans cet exemple, quatre fichiers seront créés - un pour chaque hôpital.
for(i in 1:length(hospitals)){
rmarkdown::render(
input = "surveillance_report.Rmd",
output_file = str_glue("output/Report_{hospitals[i]}_{Sys.Date()}.docx"),
params = list(hospital = hospitals[i]))
} 40.8 Canevas (Modèles de document)
En utilisant un canevas de document (exemple type) qui contient le formatage souhaité, vous pouvez ajuster l’esthétique de la sortie Rmd. Vous pouvez par exemple créer un fichier MS Word ou Powerpoint qui contient des pages/diapositives avec les dimensions, les filigranes, les fonds et les polices de caractères souhaités.
Documents Word
Pour créer un canevas, commencez un nouveau document Word (ou utilisez une sortie existante avec un formatage qui vous convient), et modifiez les polices en définissant les Styles. Dans Style,les titres 1, 2 et 3 font référence aux différents niveaux d’en-tête markdown (respectivement # Header 1, ## Header 2 et ## Header 3). Cliquez avec le bouton droit de la souris sur le style et cliquez sur “modifier” pour changer le formatage de la police ainsi que le paragraphe (par exemple, vous pouvez introduire des sauts de page avant certains styles, ce qui peut faciliter l’espacement). D’autres aspects du document Word, tels que les marges, la taille de la page, les en-têtes, etc., peuvent être modifiés comme un document Word habituel dans lequel vous travaillez directement.
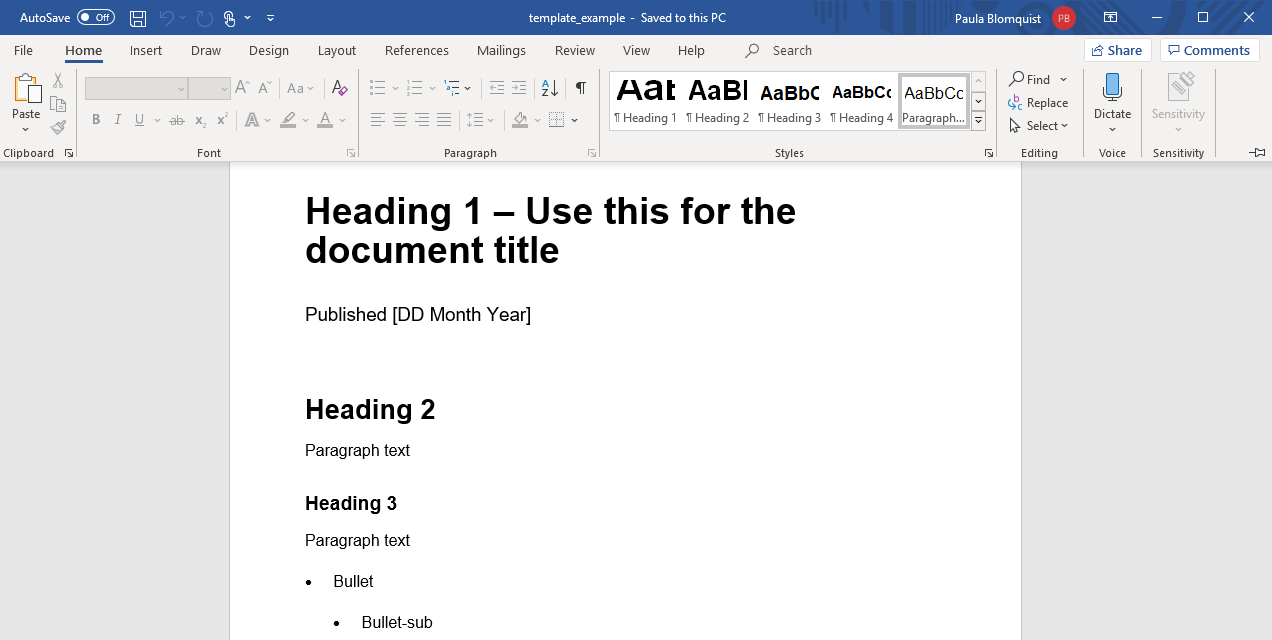
Documents Powerpoint
Comme ci-dessus, créez un nouveau jeu de diapositives ou utilisez un fichier Powerpoint existant avec le formatage souhaité. Pour une édition plus poussée, cliquez sur ‘View’ et ‘Slide Master’. À partir de là, vous pouvez modifier l’apparence de la diapositive “de base” en modifiant le formatage du texte dans les zones de texte, ainsi que les dimensions de l’arrière-plan/de la page pour l’ensemble de la page.
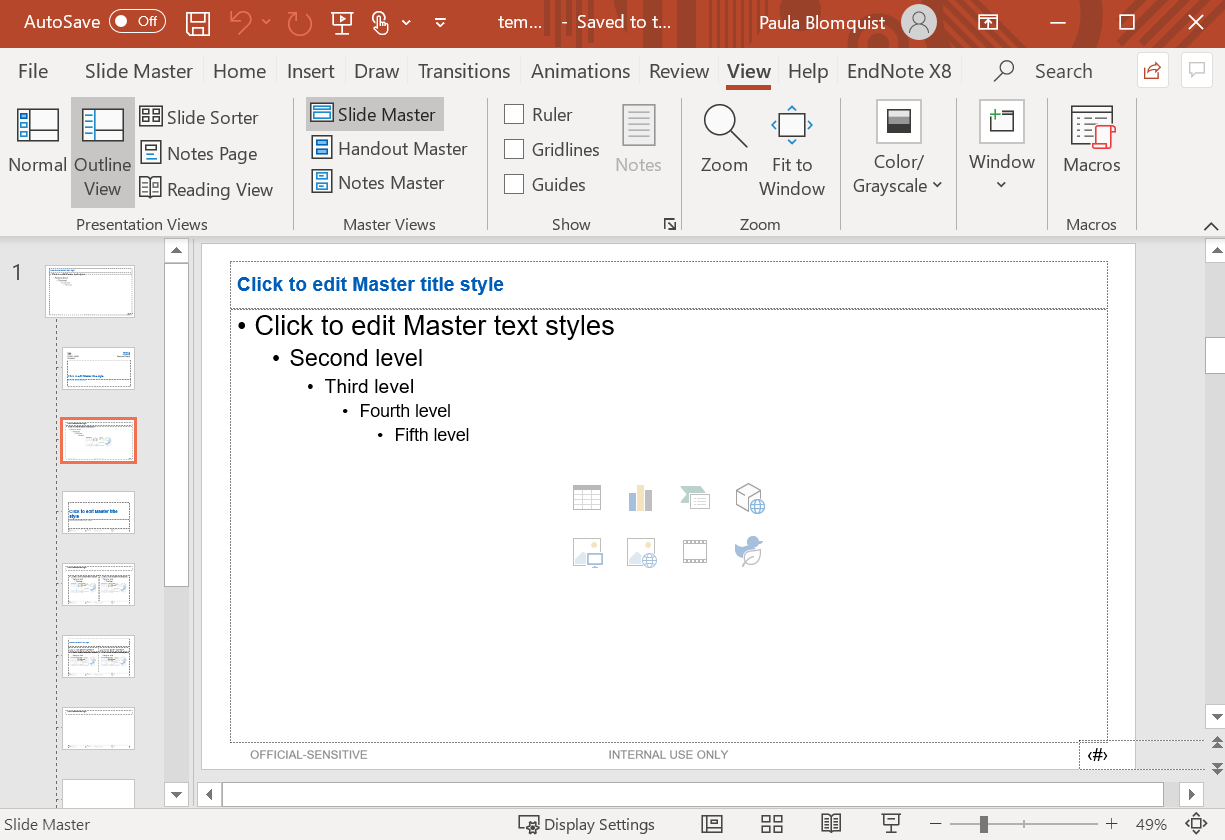
Malheureusement, l’édition des fichiers Powerpoint est un peu moins souple :
- Un en-tête de premier niveau (
# Header 1) deviendra automatiquement le titre d’une nouvelle diapositive, - Un texte
## Header 2n’apparaîtra pas comme un sous-titre mais comme un texte dans la zone de texte principale de la diapositive (à moins que vous ne trouviez un moyen de manoeuvrer la slide de base). - Les graphiques et les tableaux générés seront automatiquement placés dans de nouvelles diapositives. Vous devrez les combiner, par exemple avec la fonction patchwork pour combiner les ggplots, afin qu’ils apparaissent sur la même page. Consultez cet article de blog sur l’utilisation du paquet patchwork pour placer plusieurs images sur une seule diapositive.
Voir le paquet officer pour un outil permettant de travailler plus en profondeur avec les présentations Powerpoint.
Intégration des canevas (modèle de document) dans le YAML
Une fois qu’un canevas est préparé, le détail de celui-ci peut être ajouté dans le YAML du fichier Rmd sous la ligne “output” et sous l’endroit où le type de document est spécifié (qui va sur une ligne séparée elle-même). Notons que reference_doc peut être utilisé pour les modèles de diapositives Powerpoint.
Il est plus facile de sauvegarder le canevas dans le même dossier que celui où se trouve le fichier Rmd (comme dans l’exemple ci-dessous), ou dans un sous-dossier.
---
title: Surveillance report
output:
word_document:
reference_docx: "template.docx"
params:
date: 2021-04-10
hospital: Central Hospital
template:
---Formatage des fichiers HTML
Les fichiers HTML n’utilisent pas de modèles, mais les styles peuvent être configurés dans le YAML. Les HTML sont des documents interactifs, et sont particulièrement flexibles. Nous couvrons ici quelques options de base.
Table des matières : On peut ajouter une table des matières avec
toc: trueci-dessous, et aussi spécifier qu’elle reste visible (“flottante”) quand on la fait défiler, avectoc_float: true.Thèmes : Nous pouvons nous référer à certains thèmes pré-faits, qui proviennent d’une bibliothèque de thèmes Bootswatch. Dans l’exemple ci-dessous, nous utilisons cerulean. D’autres options incluent : journal, flatly, darkly, readable, spacelab, united, cosmo, lumen, paper, sandstone, simplex, et yeti.
Mise en évidence : Cette configuration modifie l’aspect du texte mis en évidence (par exemple, le code dans les morceaux qui sont affichés). Les styles pris en charge sont default, tango, pygments, kate, monochrome, espresso, zenburn, haddock, breezedark et textmate.
Voici un exemple de la manière d’intégrer les options ci-dessus dans le YAML.
---
title: "HTML example"
output:
html_document:
toc: true
toc_float: true
theme: cerulean
highlight: kate
---Vous trouverez ci-dessous deux exemples de sorties HTML comportant toutes deux des tables des matières flottantes, mais avec des thèmes et des styles de mise en évidence différents :
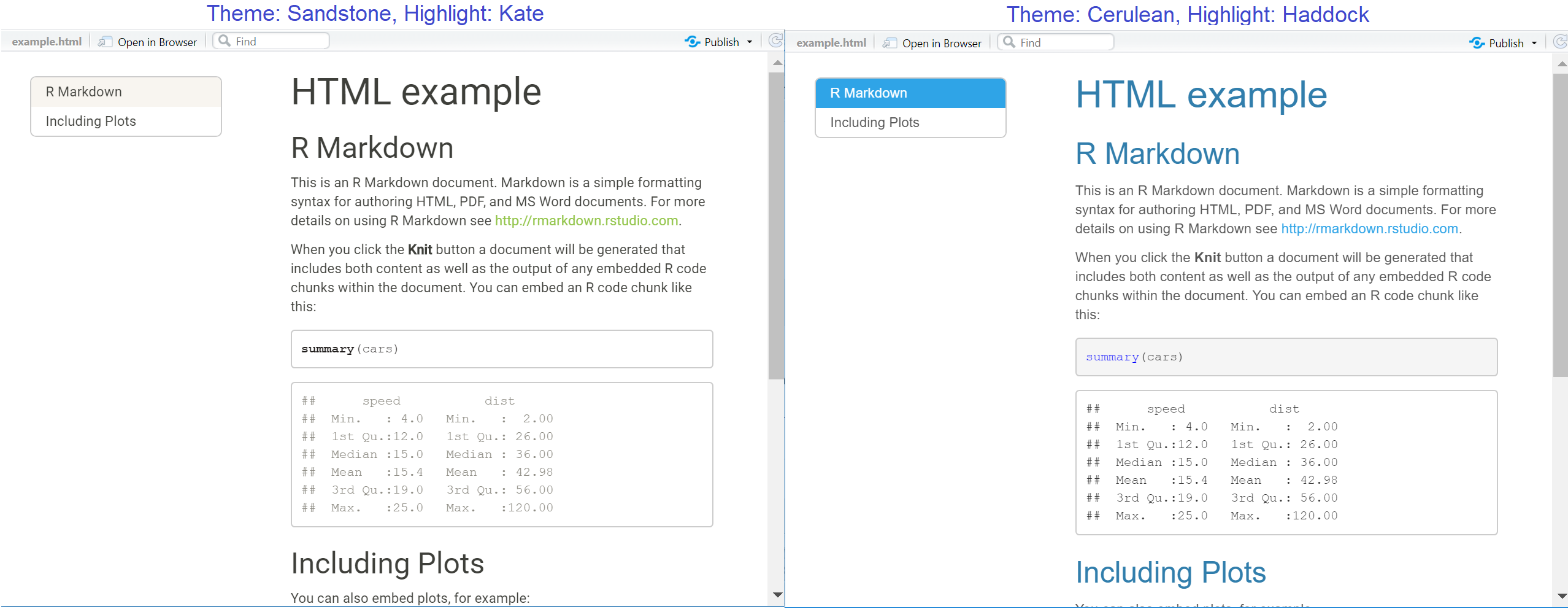
40.9 Contenu dynamique
Dans une sortie HTML, le contenu de votre rapport peut être dynamique. Voici quelques exemples :
Tableaux
Dans un rapport HTML, vous pouvez imprimer des tableaux de données de telle sorte que le contenu soit dynamique, avec des filtres et des barres de défilement. Il existe plusieurs “packages” qui offrent cette possibilité.
Pour ce faire, avec le “package” DT, tel qu’il est utilisé dans ce manuel, vous pouvez insérer un morceau de code comme celui-ci :

La fonction datatable() affichera le tableau de données fourni comme un tableau dynamique pour le lecteur. Vous pouvez définir rownames = FALSE pour simplifier le côté gauche de la table. filter = "top" fournit un filtre sur chaque colonne. Dans l’argument option(), fournissez une liste d’autres spécifications. Nous en incluons deux ci-dessous : pageLength = 5 fixe le nombre de lignes qui apparaissent à 5 (les lignes restantes peuvent être visualisées en cliquant sur les flèches), et scrollX=TRUE active une barre de défilement en bas du tableau (pour les colonnes qui s’étendent trop à droite).
Si votre jeu de données est très grand, pensez à n’afficher que les X premières lignes en enveloppant le nom du jeu de données dans head().
Les widgets HTML
Les widgets HTML pour R sont une classe spéciale de “packages” R qui permettent une interactivité accrue en utilisant des bibliothèques JavaScript. Vous pouvez les intégrer dans des sorties HTML R Markdown.
Voici quelques exemples courants de ces widgets :
- Plotly (utilisé dans cette page du manuel et dans la page Graphiques interactifs).
- visNetwork (utilisé dans la page Chaînes de transmission de ce manuel)
- Leaflet (utilisé dans la page Bases des GIS de ce manuel)
- dygraphs (utile pour afficher de manière interactive des données de séries chronologiques)
- DT (
datatable()) (utilisé pour afficher des tableaux dynamiques avec filtre, tri, etc.)
La fonction ggplotly() de plotly est particulièrement facile à utiliser. Voir la page Graphiques interactifs.
40.10 Ressources
De plus amples informations sont disponibles sur le site:
Une bonne explication de markdown vs knitr vs Rmarkdown se trouve ici: https://stackoverflow.com/questions/40563479/relationship-between-r-markdown-knitr-pandoc-and-bookdown