
11 Kiểu dữ liệu danh mục - Factors
Trong R, factors là một kiểu dữ liệu cho phép sắp xếp các danh mục với một tập hợp các giá trị có thể chấp nhận.
Thông thường, bạn sẽ chuyển đổi một cột từ dạng ký tự hoặc dạng số thành dạng factor khi bạn muốn sắp xếp một thứ tự đặc biệt cho các giá trị (“levels”) để chúng không hiển thị mặc định theo thứ tự bảng chữ cái trong các biểu đồ và bảng. Một cách sử dụng phổ biến khác của factor là chuẩn hóa các chú thích của biểu đồ để chúng không thay đổi nếu một giá trị tạm thời không có trong dữ liệu.
Chương này giới thiệu cách sử dụng các hàm từ package forcats (tên viết tắt của “For categorical variables”) và một số hàm base R. Chúng tôi cũng đề cập đến việc sử dụng lubridate và aweek cho các trường hợp factor đặc biệt liên quan đến tuần dịch tễ học.
Bạn có thể tìm thấy danh sách đầy đủ các hàm của package forcats trực tuyến tại đường link này. Sau đây, chúng tôi sẽ chỉ trình bày một số hàm phổ biến nhất.
11.1 Chuẩn bị
Gọi packages
Đoạn code dưới đây hiển thị cách gọi các package cần thiết cho việc phân tích. Trong sách này, chúng tôi nhấn mạnh đến việc sử dụng hàm p_load() từ package pacman, giúp cài đặt package nếu nó chưa được cài và gọi nó ra cho phiên làm việc. Bạn cũng có thể gọi các package đã được cài đặt bằng hàm library() từ base R. Xem chương R cơ bản để biết thêm thông tin về các package trong R.
pacman::p_load(
rio, # import/export
here, # filepaths
lubridate, # working with dates
forcats, # factors
aweek, # create epiweeks with automatic factor levels
janitor, # tables
tidyverse # data mgmt and viz
)Nhập dữ liệu
Chúng ta sẽ nhập bộ dữ liệu về các trường hợp từ một vụ dịch Ebola mô phỏng. Để tiện muốn theo dõi, bấm để tải bộ dữ liệu linelist “đã được làm sạch” (dưới dạng tệp .rds). Nhập dữ liệu bằng hàm import() từ package rio (hàm có thể áp dụng với nhiều loại dữ liệu như .xlsx, .rds, .csv - Xem chương Nhập xuất dữ liệu để biết thêm chi tiết).
# import your dataset
linelist <- import("linelist_cleaned.rds")Thêm biến danh mục mới
Trong chương này, chúng tôi sẽ minh họa một trường hợp thường gặp, đó là tạo ra một biến danh mục mới.
Lưu ý rằng khi bạn chuyển đổi một cột dạng số thành dạng factor, bạn sẽ không thể thực hiện các tính toán thống kê đối với dữ liệu dạng số trên cột đó nữa.
Tạo biến
Chúng ta sẽ sử dụng một biến có sẵn, tên là days_onset_hosp (số ngày, tính từ khi bắt đầu có triệu chứng cho đến khi nhập viện) và tạo một biến mới có tên delay_cat bằng cách phân loại các giá trị trong mỗi hàng của biến có sẵn đó thành một số nhóm khác nhau. Chúng ta sẽ thực hiện việc này bằng hàm case_when() trong package dplyr, hàm này sẽ giúp áp dụng tuần tự các tiêu chí logic (phía bên phải) cho mỗi giá trị của biễn có sẵn và trả về giá trị bên trái tương ứng ở biến mới delay_cat. Đọc thêm về case_when() tại chương Làm sạch số liệu và các hàm quan trọng.
linelist <- linelist %>%
mutate(delay_cat = case_when(
# criteria # new value if TRUE
days_onset_hosp < 2 ~ "<2 days",
days_onset_hosp >= 2 & days_onset_hosp < 5 ~ "2-5 days",
days_onset_hosp >= 5 ~ ">5 days",
is.na(days_onset_hosp) ~ NA_character_,
TRUE ~ "Check me")) Thứ tự mặc định của các giá trị
Khi sử dụng hàm case_when(), biến mới delay_cat tạo ra sẽ là một biến danh mục với kiểu dữ liệu là ký tự - chưa phải là một factor. Do đó, trong bảng tần suất dưới đây, chúng ta thấy rằng các giá trị xuất hiện theo thứ tự mặc định của bảng chữ cái, điều này không có nhiều ý nghĩa trực quan:
table(linelist$delay_cat, useNA = "always")
<2 days >5 days 2-5 days <NA>
2990 602 2040 256 Tương tự như vậy, nếu chúng ta tạo biểu đồ cột, các giá trị cũng xuất hiện theo thứ tự này trên trục x (xem chương ggplot cơ bản để hiểu thêm về package ggplot2 - package giúp trực quan hóa dữ liệu phổ biến nhất trong R).
ggplot(data = linelist)+
geom_bar(mapping = aes(x = delay_cat))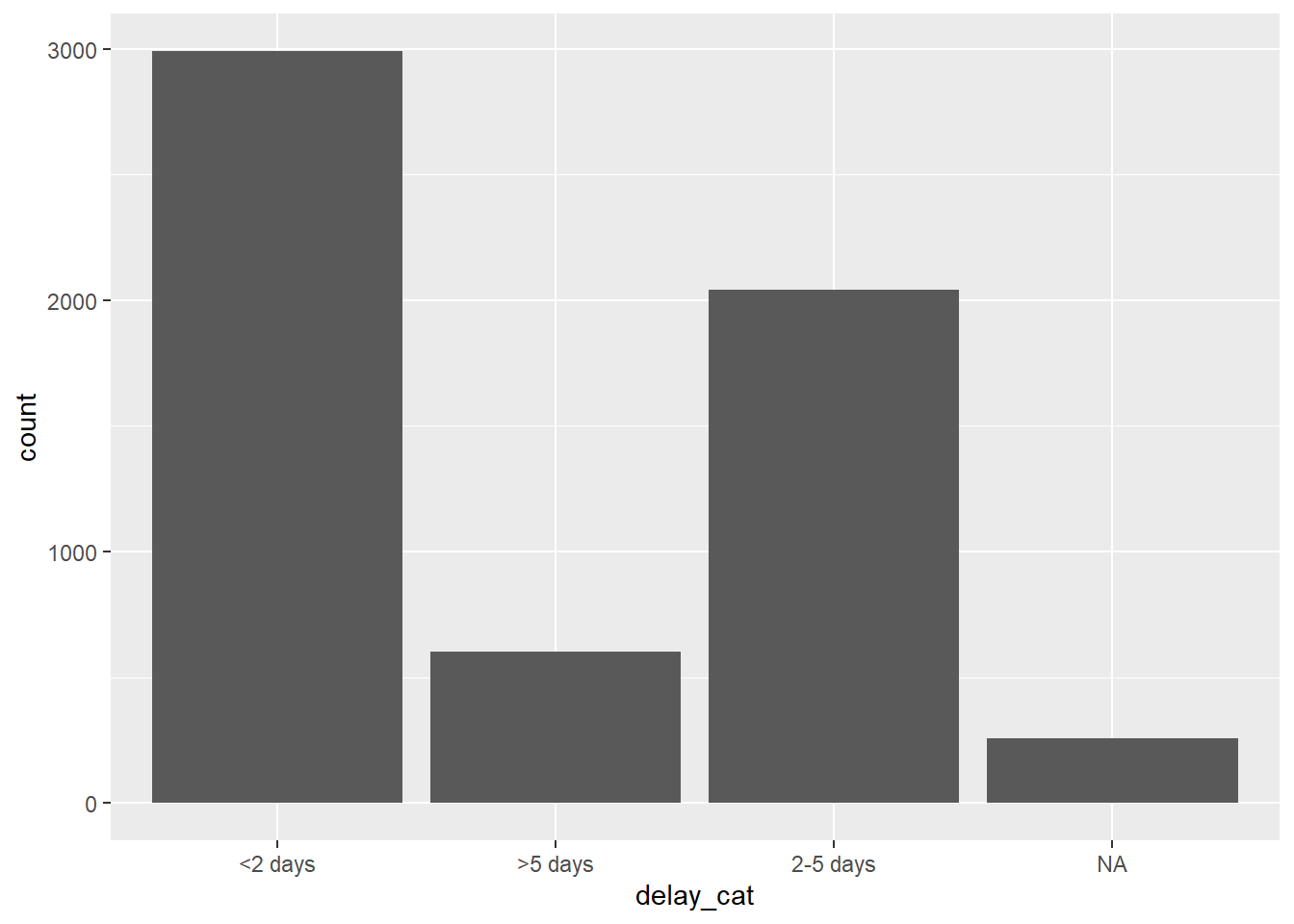
11.2 Định nghĩa dữ liệu sang kiểu factor
Để chuyển đổi một biến dạng ký tự hoặc dạng số sang dạng factor, bạn có thể sử dụng bất kỳ hàm nào trong package forcats (nhiều hàm được nêu chi tiết tại mục dưới đây). Các biến sẽ chuyển đổi sang dạng factor và sau đó cũng thực hiện hoặc sắp xếp theo một thứ tự nhất định của các levels - ví dụ: hàm fct_relevel() cho phép bạn chỉ định thứ tự levels theo cách thủ công. Hàm as_factor() chỉ đơn giản là chuyển đổi biến sang dạng factor mà không có thêm bất kỳ chức năng nào khác.
Hàm factor() trong base R chuyển đổi một biến thành factor và cho phép bạn tự sắp xếp thứ tự của các nhóm giá trị, dưới dạng một vectơ ký tự của đối số levels =.
Dưới đây, chúng tôi sử dụng hàm mutate() và hàm fct_relevel() để chuyển đối biến có sẵn delay_cat từ dạng ký tự sang dạng factor. Biến delay_cat đã được tạo ở phần Chuẩn bị bên trên.
linelist <- linelist %>%
mutate(delay_cat = fct_relevel(delay_cat))Các “giá trị” duy nhất trong biến số được gọi là các “thứ bậc” của biến factor. Các thứ bậc này được sắp xếp theo một trật tự nhất định và có thể được in ra bằng hàm levels() từ base R, hoặc bạn có thể xem nó bằng một bảng đếm thông qua hàm table()từ base R, hoặc hàm tabyl() từ package janitor. Trật tự này sẽ được hiển thị theo thứ tự của bảng chữ cái. Lưu ý rằng NA không được xem là một thứ bậc trong factor.
levels(linelist$delay_cat)[1] "<2 days" ">5 days" "2-5 days"Hàm fct_relevel() có thêm chức năng cho phép bạn có thể tự sắp xếp trật tự của các thứ bậc trong factor. Đơn giản, bạn chỉ cần viết các thứ bậc theo thứ tự bạn muốn, để chúng trong dấu ngoặc kép, được phân tách bằng dấu phẩy, như được hiển thị bên dưới. Lưu ý rằng chính tả phải khớp chính xác với tên các thứ bậc. Nếu bạn muốn tạo các thứ bậc không tồn tại trong dữ liệu, hãy sử dụng hàm fct_expand().
linelist <- linelist %>%
mutate(delay_cat = fct_relevel(delay_cat, "<2 days", "2-5 days", ">5 days"))Bây giờ chúng ta có thể thấy rằng các thứ bậc đã được sắp xếp theo một thứ tự hợp lý.
levels(linelist$delay_cat)[1] "<2 days" "2-5 days" ">5 days" Bây giờ trật tự các cột trong biểu đồ cũng trực quan hơn.
ggplot(data = linelist)+
geom_bar(mapping = aes(x = delay_cat))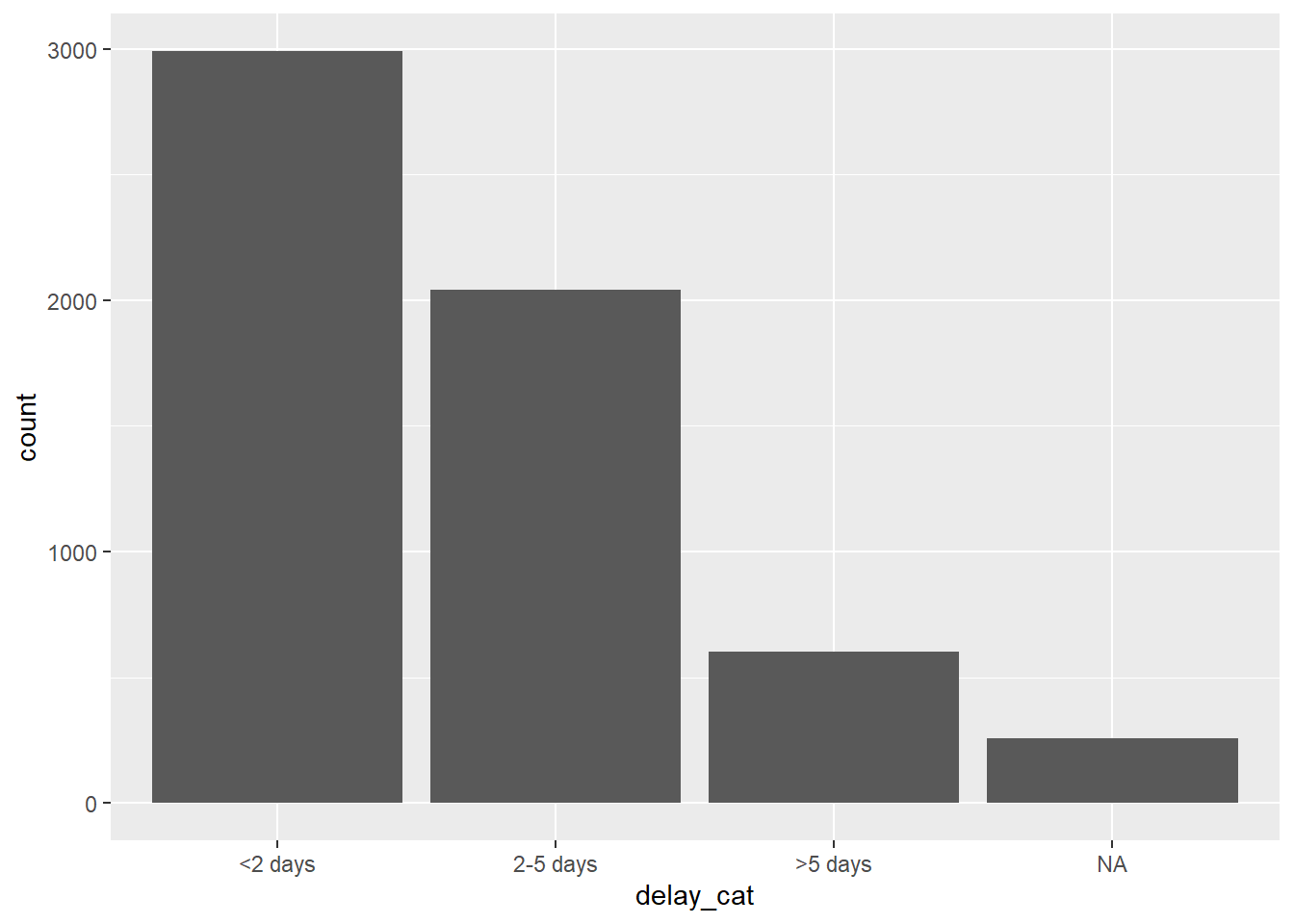
11.3 Thêm hoặc xóa thứ bậc
Thêm thứ bậc
Nếu bạn cần thêm thứ bậc trong factor, bạn có thể sử dụng hàm fct_expand(). Bạn chỉ cần viết tên biến và theo sau là tên các thứ bậc mới (phân tách bằng dấu phẩy). Bằng cách lập bảng, chúng ta có thể thấy các thứ bậc mới xuất hiện và chưa nhận giá trị nào. Bạn có thể sử dụng hàm table() trong base R, hoặc hàm tabyl() trong package janitor:
linelist %>%
mutate(delay_cat = fct_expand(delay_cat, "Not admitted to hospital", "Transfer to other jurisdiction")) %>%
tabyl(delay_cat) # print table delay_cat n percent valid_percent
<2 days 2990 0.50781250 0.5308949
2-5 days 2040 0.34646739 0.3622159
>5 days 602 0.10224185 0.1068892
Not admitted to hospital 0 0.00000000 0.0000000
Transfer to other jurisdiction 0 0.00000000 0.0000000
<NA> 256 0.04347826 NALưu ý: Package forcats có thể dễ dàng thêm các giá trị missing (NA) như là một thứ bậc. Bạn có thể xem thêm tại mục Giá trị Missing dưới đây.
Xóa thứ bậc
Nếu bạn sử dụng hàm fct_drop(), các thứ bậc “không được sử dụng” và không có quan sát nào sẽ bị loại bỏ khỏi factors. Thứ bậc mà chúng ta đã thêm ở trên (“Not admitted to a hospital”) có tồn tại nhưng thực tế không có dòng nào chứa giá trị này. Vì vậy, chúng sẽ bị loại bỏ khỏi biến factor của chúng ta bằng cách sử dụng hàm fct_drop() như sau:
linelist %>%
mutate(delay_cat = fct_drop(delay_cat)) %>%
tabyl(delay_cat) delay_cat n percent valid_percent
<2 days 2990 0.50781250 0.5308949
2-5 days 2040 0.34646739 0.3622159
>5 days 602 0.10224185 0.1068892
<NA> 256 0.04347826 NA11.4 Thay đổi trật tự của các thứ bậc
Package forcats cung cấp các hàm hữu ích để dễ dàng thay đổi trật tự của các thứ bậc trong một biến kiểu factor (sau khi một biến số được định nghĩa là một factor):
Các hàm trong package này có thể được áp dụng cho biến dạng factor trong hai trường hợp dưới đây:
- Đối với cột trong một data frame, thông thường, việc thay đổi sẽ được giữ nguyên cho các lần sử dụng dữ liệu tiếp theo
- Trong một biểu đồ, sự thay đổi trật tự chỉ được áp dụng cho biểu đồ đó
Thay đổi thủ công
Hàm này được sử dụng để thay đổi trật tự của các thứ bậc trong một biến dạng factor theo cách thủ công. Nếu hàm này được sử dụng trên một biến dạng khác, không phải factor, hàm sẽ giúp chuyển biến đó sang dạng factor trước.
Trong dấu ngoặc đơn trước tiên điền tên của biến factor, sau đó điền:
- Tất cả các thứ bậc trong biến factor mà bạn mong muốn thay đổi trật tự (dưới dạng vector ký tự
c()), hoặc - Chỉ một giá trị thứ bậc với vị trí tương ứng mong muốn, sử dụng đối số
after =
Dưới đây là một ví dụ về chuyển biến delay_cat thành dạng factor (mặc dù biến này đã ở dạng Factor rồi) và sắp xếp lại các thứ bậc theo thứ tự mong muốn.
# re-define level order
linelist <- linelist %>%
mutate(delay_cat = fct_relevel(delay_cat, c("<2 days", "2-5 days", ">5 days")))Nếu bạn chỉ muốn chỉ định vị trí cho một thứ bậc, bạn có thể dùng hàm fct_relevel() và sử dụng đối số after = để chỉ định một giá trị thứ bậc với vị trí tương ứng mong muốn. Ví dụ: lệnh dưới đây chuyển thứ bậc “<2 days” sang vị trí thứ hai:
# re-define level order
linelist %>%
mutate(delay_cat = fct_relevel(delay_cat, "<2 days", after = 1)) %>%
tabyl(delay_cat)Đối với biểu đồ
Các lệnh trong package forcats có thể được sử dụng để thay đổi trật tự của biến trong data frame hoặc trong biểu đồ. Bằng cách sử dụng các lệnh để “gói” tên biến vào trong các lệnh vẽ biểu đồ của package ggplot(), bạn có thể dảo ngược/thay đổi một trật tự có sẵn của biến. Sự thay đổi này chỉ áp dụng trong biểu đồ đang vẽ.
Dưới đây, hai biểu đồ đều được vẽ bởi hàm ggplot() (xem thêm tại chương ggplot cơ bản). Trong biểu đồ đầu tiên, biến delay_cat được vẽ trên trục x của biểu đồ với thứ tự các thứ bậc là mặc định trong dữ liệu linelist. Trong biểu đồ thứ hai, biến được đặt trong bởi hàm fct_relevel() và trật tự của các thứ bậc đã được sắp xếp lại.
# Alpha-numeric default order - no adjustment within ggplot
ggplot(data = linelist)+
geom_bar(mapping = aes(x = delay_cat))
# Factor level order adjusted within ggplot
ggplot(data = linelist)+
geom_bar(mapping = aes(x = fct_relevel(delay_cat, c("<2 days", "2-5 days", ">5 days"))))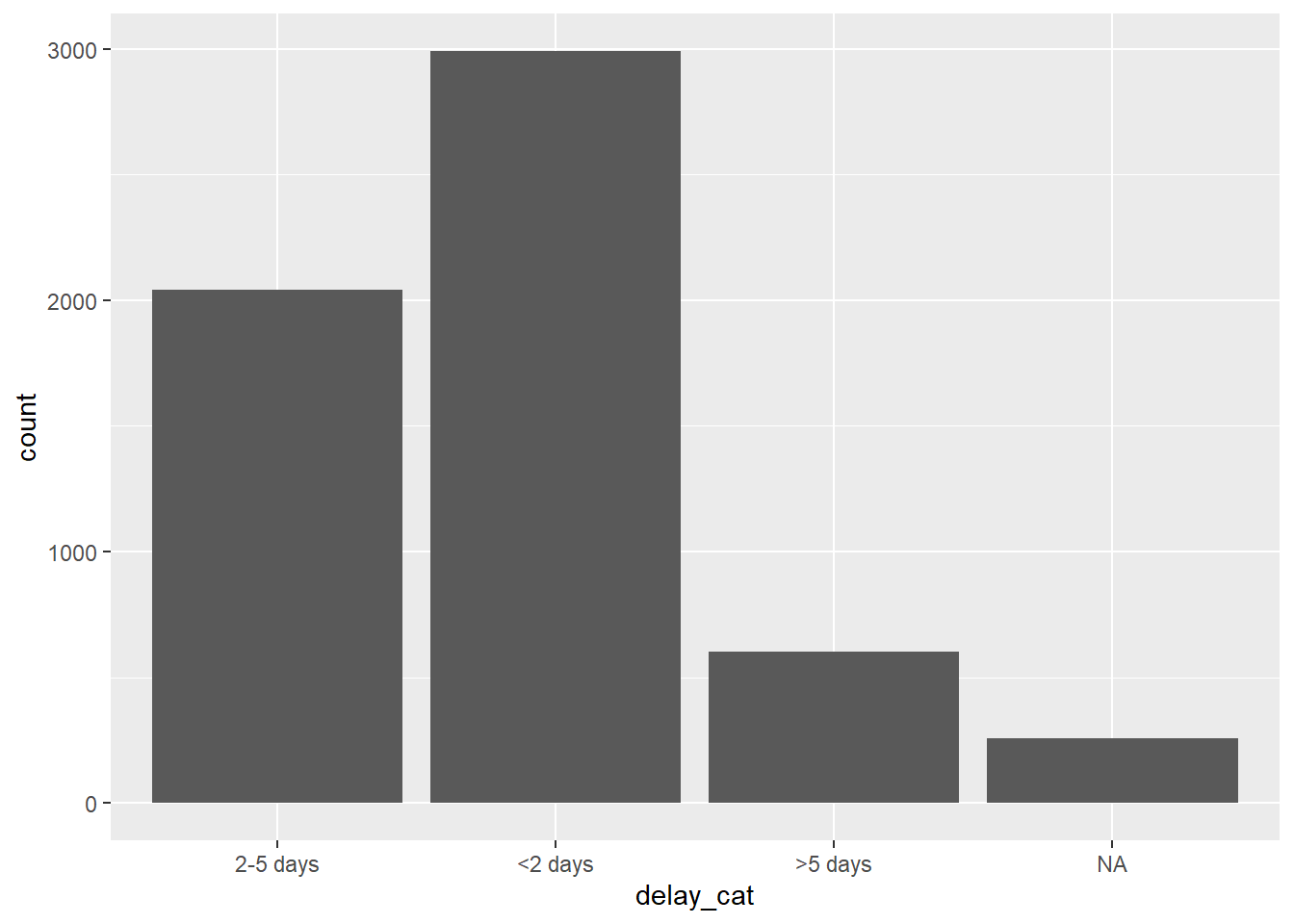
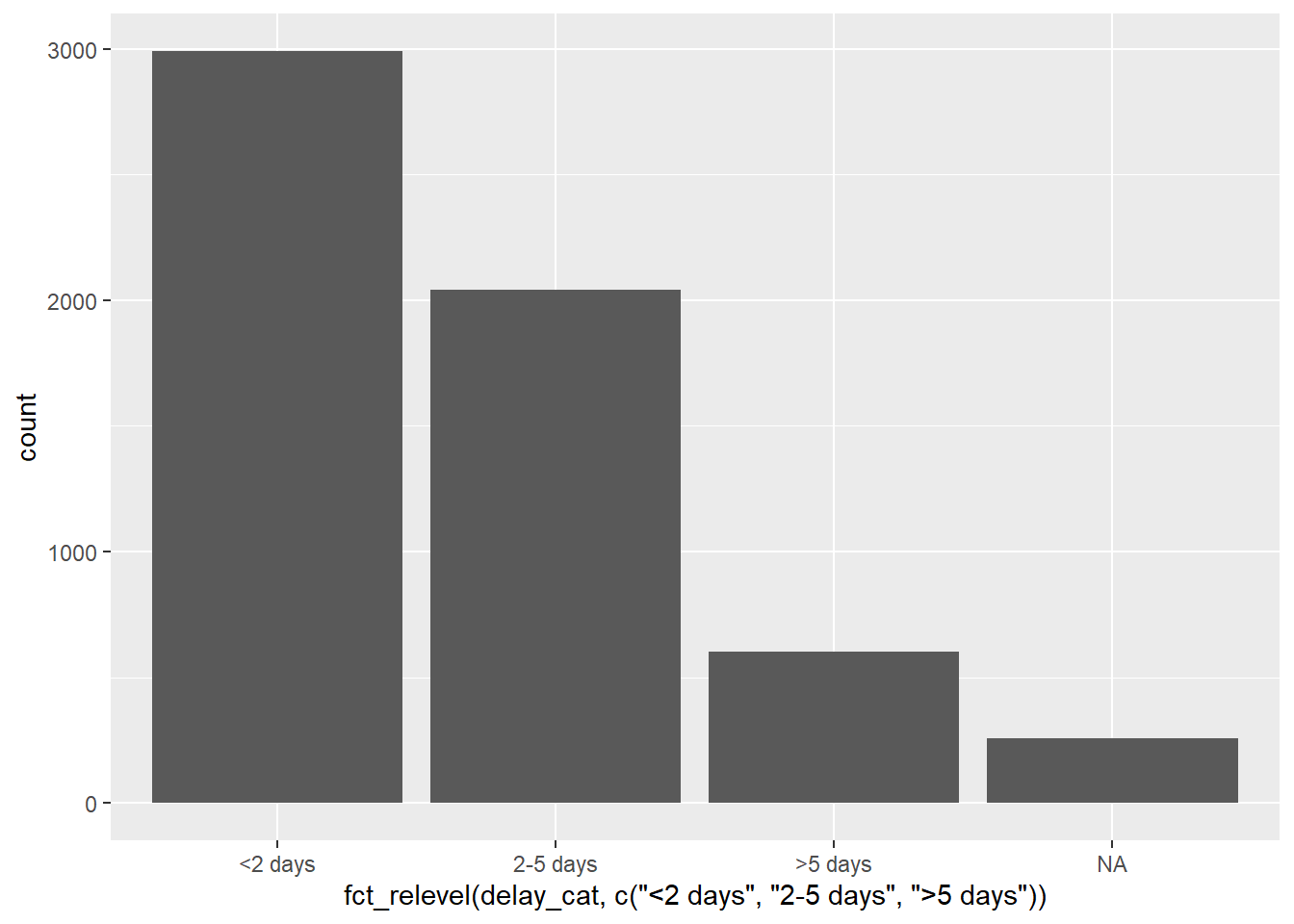
Lưu ý rằng, ở biểu đồ thứ hai, tiêu đề mặc định của trục x được hiện khá phức tạp - bạn có thể sử tiêu đề này bằng đối số labs() trong ggplot2.
Đảo ngược thứ tự
Bạn sẽ thường xuyên cần đảo ngược trật tự của các thứ bậc trong một biến. Đơn giản, bạn chỉ cần thêm tên biến vào bên trong hàm fct_rev().
Lưu ý rằng, nếu bạn chỉ muốn đảo ngược thứ tự trong một biểu đồ chứ không phải thứ tự của biến đó, bạn có thể thực hiện điều đó với hàm guides() (Xem thêm tại chương Các mẹo với ggplot).
Theo tần suất
Để sắp xếp trật tự các thứ bậc theo tần suất mà nó xuất hiện trong dữ liệu, hãy sử dụng hàm fct_infreq(). Tất cả các giá trị mising (NA) sẽ tự động được đưa xuống cuối, trừ khi chúng được chuyển sang một thứ bậc khác (xem thêm ở mục này). Bạn có thể đảo ngược trật tự bằng cách thêm hàm fct_rev() vào câu lệnh.
Hàm này có thể được sử dụng trong ggplot(), như hình bên dưới.
# ordered by frequency
ggplot(data = linelist, aes(x = fct_infreq(delay_cat)))+
geom_bar()+
labs(x = "Delay onset to admission (days)",
title = "Ordered by frequency")
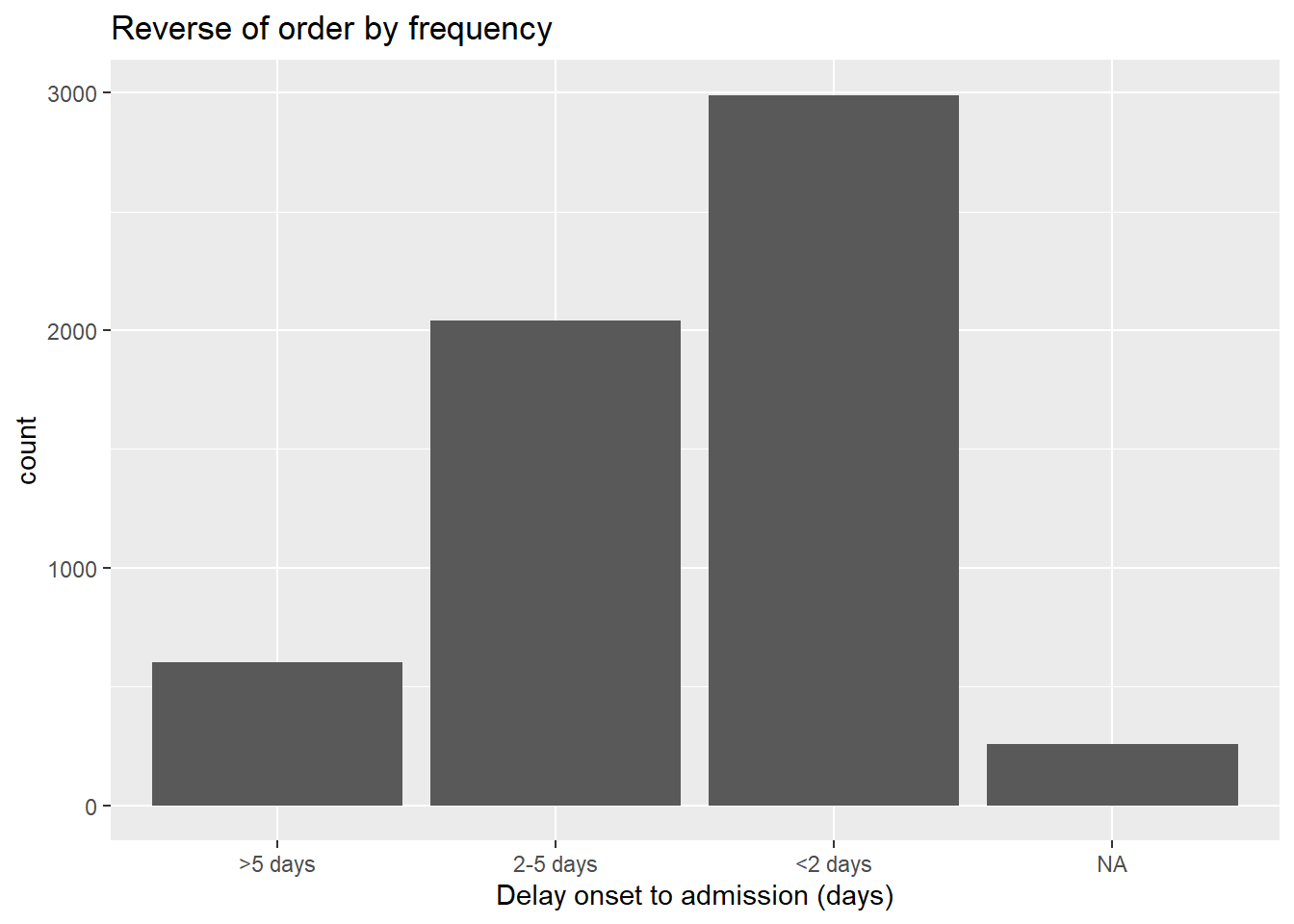
# reversed frequency
ggplot(data = linelist, aes(x = fct_rev(fct_infreq(delay_cat))))+
geom_bar()+
labs(x = "Delay onset to admission (days)",
title = "Reverse of order by frequency")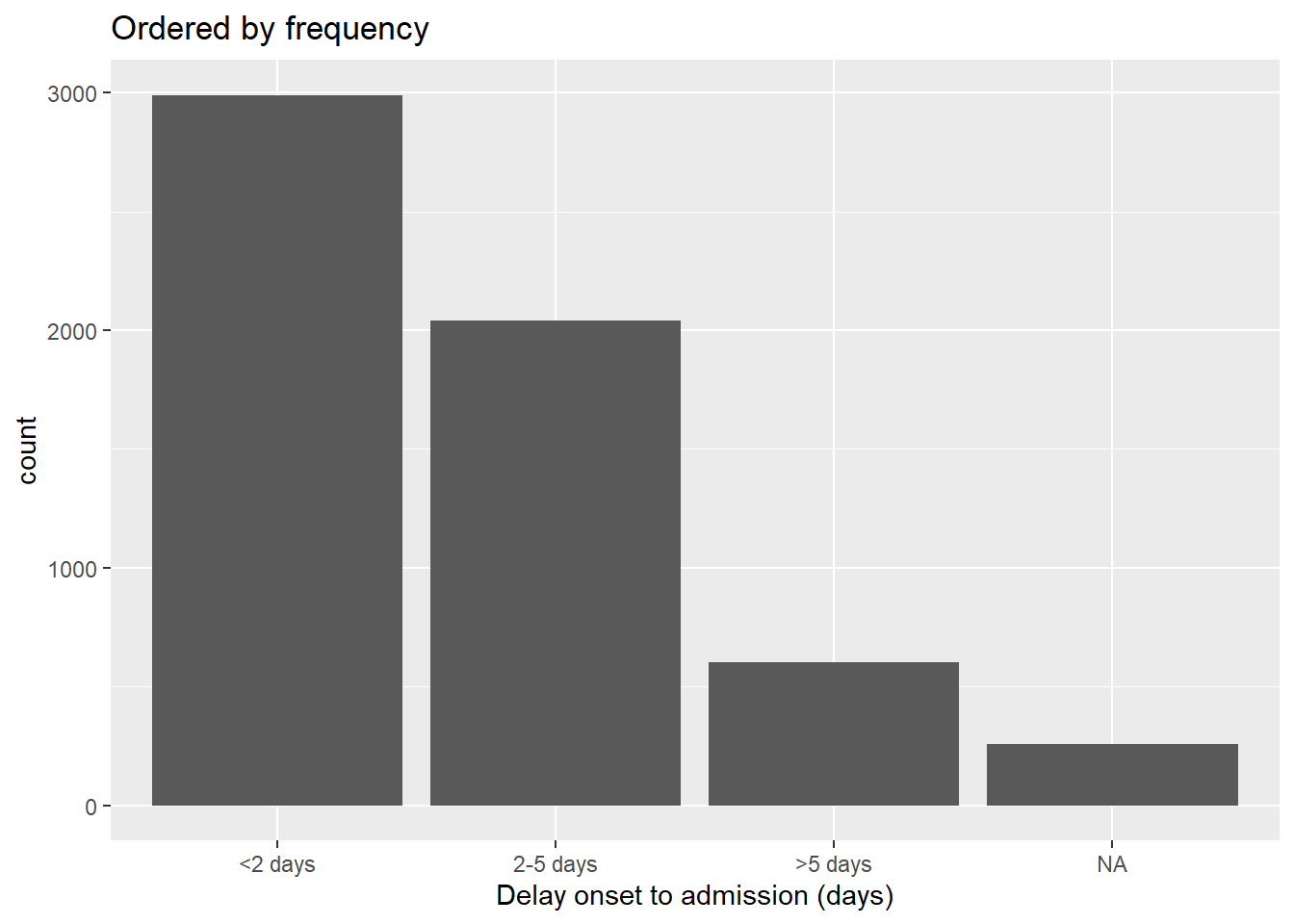
Theo sự xuất hiện
Sử dụng hàm fct_inorder() để thiết lập thứ bậc tương tự với thứ tự xuất hiện của các giá trị trong dữ liệu, bắt đầu từ hàng đầu tiên. Điều này có thể hữu ích nếu trước đó bạn đã cẩn thận sắp xếp dữ liệu trong data frame bằng hàm arrange(), sau đó sử dụng điều này để đặt trật tự các thứ bậc của biến facror.
Theo thống kê tóm tắt của một cột khác
Bạn có thể sử dụng hàm fct_reorder() để sắp xếp các thứ bậc của một biến theo thống kê tóm tắt của một biến khác. Về mặt trực quan, điều này có cho kết quả là các biểu đồ như ý bạn, có các cột/điểm lên hoặc xuống theo một chiều trong toàn bộ biểu đồ.
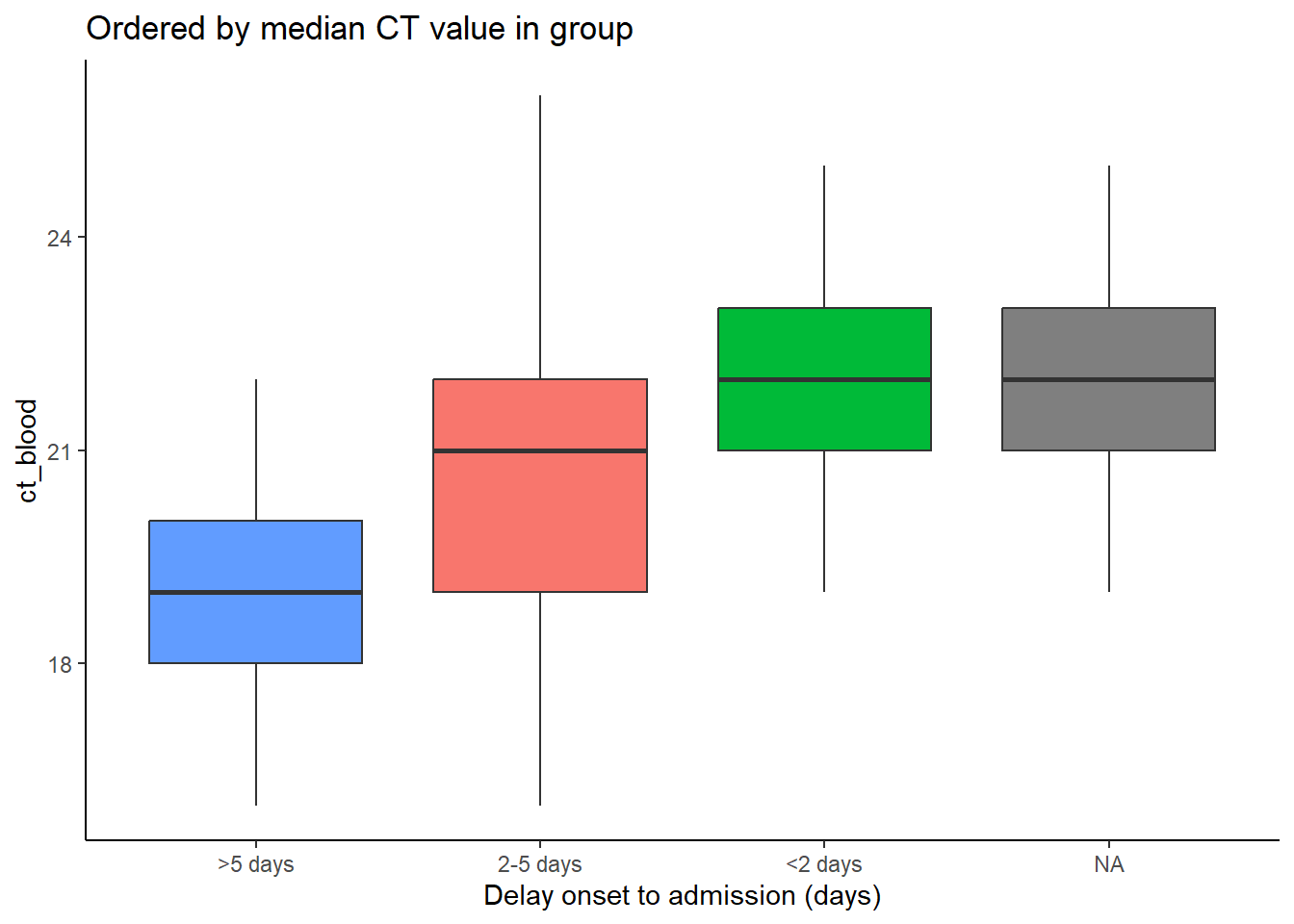
Trong các ví dụ bên dưới, trục x là delay_cat, và trục y là ct_blood (giá trị ngưỡng chu kỳ). Biểu đồ hộp (Box plot) hiển thị phân bố của giá trị CT theo nhóm delay_cat. Chúng ta cần sắp xếp các hộp theo thứ tự tăng dần của giá trị trung vị CT của nhóm.
Trong ví dụ đầu tiên bên dưới, các thứ bậc được sắp xếp một cách mặc định. Bạn có thể thấy các chiều cao của hộp bị lộn xộn và không theo bất kỳ thứ tự cụ thể nào. Trong ví dụ thứ hai, cột delay_cat (được sắp xếp theo trục x) đã được viết lệnh với hàm fct_reorder(), cột ct_blood được đưa ra làm đối số thứ hai và “trung vị” được đưa ra làm đối số thứ ba (bạn cũng có thể sử dụng “max”, “mean”, “min”, v.v.). Do đó, thứ tự các thứ bậc của biến delay_cat bây giờ sẽ phản ánh các giá trị trung vị CT tăng dần theo nhóm delay_cat. Điều này được trình bày trong biểu đồ thứ hai - các hộp đã được sắp xếp lại theo chiều tăng dần. Lưu ý giá trị missing NA sẽ luôn xuất hiện ở cuối, trừ khi được chuyển đổi thành một thứ bậc khác.
# boxplots ordered by original factor levels
ggplot(data = linelist)+
geom_boxplot(
aes(x = delay_cat,
y = ct_blood,
fill = delay_cat))+
labs(x = "Delay onset to admission (days)",
title = "Ordered by original alpha-numeric levels")+
theme_classic()+
theme(legend.position = "none")
# boxplots ordered by median CT value
ggplot(data = linelist)+
geom_boxplot(
aes(x = fct_reorder(delay_cat, ct_blood, "median"),
y = ct_blood,
fill = delay_cat))+
labs(x = "Delay onset to admission (days)",
title = "Ordered by median CT value in group")+
theme_classic()+
theme(legend.position = "none")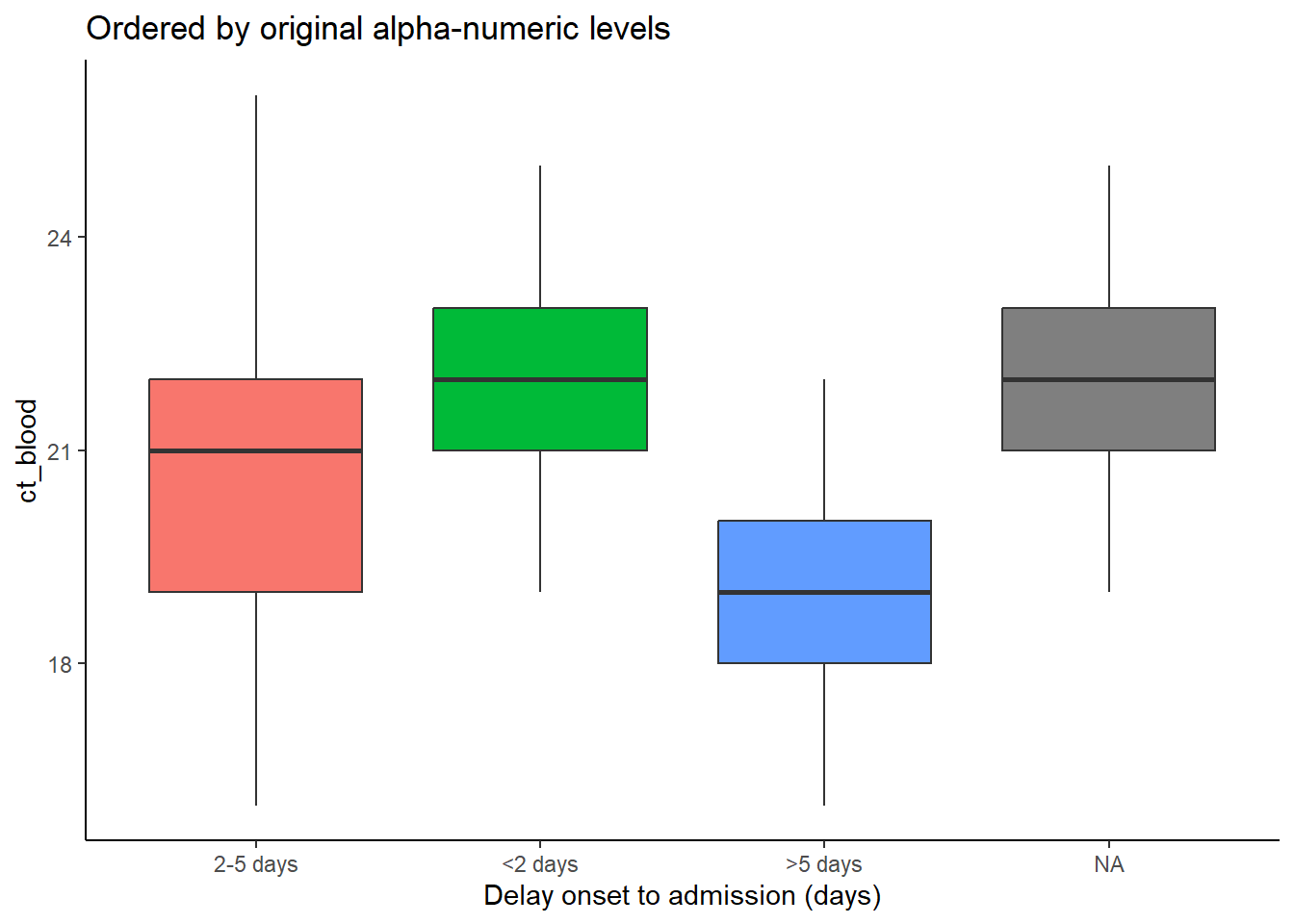
Lưu ý trong ví dụ bên trên không có bước nào được yêu cầu cần thực hiện trước khi gọi hàm ggplot() - việc nhóm và tính toán đều được thực hiện bên trong hàm ggplot.
Theo giá trị cuối
Sử dụng hàm fct_reorder2() cho biểu đồ đường theo nhóm. Hàm sẽ sắp xếp thứ tự xuất hiện các nhóm (bao gồm cả phần chú giải) dọc theo biểu đồ. Nói về mặt kỹ thuật, nó “sắp xếp theo các giá trị y tương ứng với các giá trị x lớn nhất.”
Ví dụ, nếu bạn có các dòng hiển thị số lượng trường hợp theo bệnh viện và thời gian, bạn có thể áp dụng hàm fct_reorder2() cho đối số color = trong aes(), sao cho thứ tự của các bệnh viện xuất hiện trong phần chú giải tương đương với thứ tự xuất hiện của các đường trong biểu đồ. Đọc thêm trong tài liệu trực tuyến sau đây.
epidemic_data <- linelist %>% # begin with the linelist
filter(date_onset < as.Date("2014-09-21")) %>% # cut-off date, for visual clarity
count( # get case counts per week and by hospital
epiweek = lubridate::floor_date(date_onset, "week"),
hospital
)
ggplot(data = epidemic_data)+ # start plot
geom_line( # make lines
aes(
x = epiweek, # x-axis epiweek
y = n, # height is number of cases per week
color = fct_reorder2(hospital, epiweek, n)))+ # data grouped and colored by hospital, with factor order by height at end of plot
labs(title = "Factor levels (and legend display) by line height at end of plot",
color = "Hospital") # change legend title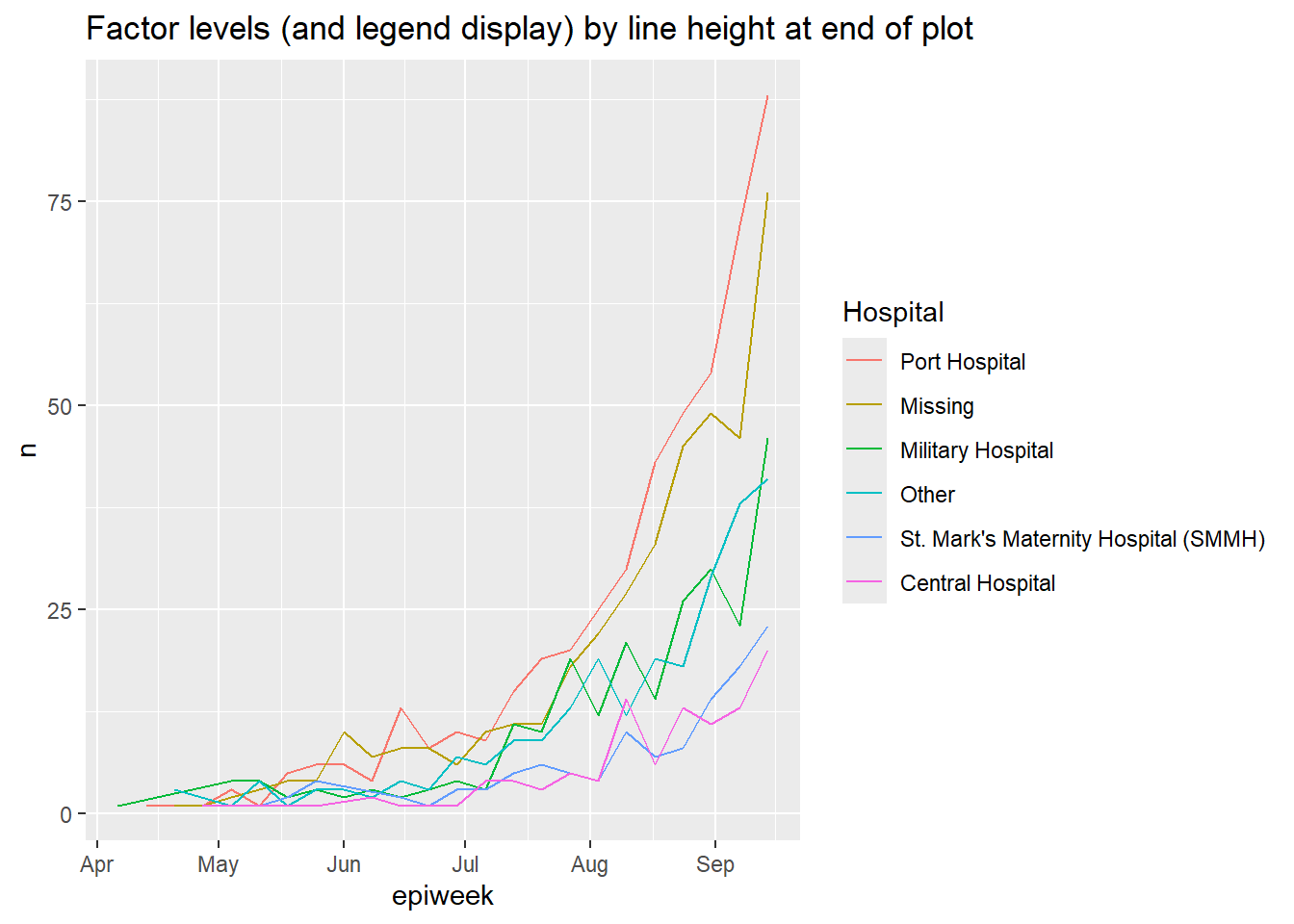
11.5 Giá trị Missing
Nếu có giá trị missing NA trong biến factor của bạn, bạn có thể dễ dàng chuyển đổi chúng thành một thứ bậc được đặt tên với hàm fct_explicit_na(). Giá trị missing NA được chuyển đổi thành “(Missing)” mặc định sẽ được xếp cuối cùng. Bạn có thể điều chỉnh tên thứ bậc bằng đối số na_level =.
Ví dụ dưới đây được thực hiện trên biến delay_cat và một bảng được in bằngtabyl()với các giá trị missing NA được chuyển thành “Missing delay”.
linelist %>%
mutate(delay_cat = fct_explicit_na(delay_cat, na_level = "Missing delay")) %>%
tabyl(delay_cat)Warning: There was 1 warning in `mutate()`.
ℹ In argument: `delay_cat = fct_explicit_na(delay_cat, na_level = "Missing
delay")`.
Caused by warning:
! `fct_explicit_na()` was deprecated in forcats 1.0.0.
ℹ Please use `fct_na_value_to_level()` instead. delay_cat n percent
2-5 days 2040 0.34646739
<2 days 2990 0.50781250
>5 days 602 0.10224185
Missing delay 256 0.0434782611.6 Kết hợp các thứ bậc trong kiểu dữ liệu factor
Kết hợp thủ công
Bạn có thể điều chỉnh cách hiển thị của các thứ bậc theo cách thủ công với hàm fct_recode(). Điều này giống như hàm recode() trong package dplyr (xem thêm tại chương Làm sạch số liệu và các hàm quan trọng), nhưng nó cho phép tạo các thứ bậc mới. Nếu bạn đơn giản chỉ sử dụng hàm recode(), các giá trị được mã hóa mới sẽ bị từ chối trừ khi chúng đã được đặt ở thứ bậc cho phép.
Công cụ này cũng có thể được sử dụng để “nhóm” các thứ bậc trong factor, bằng cách gán cho nhiều thứ bậc cùng một giá trị được mã hóa lại. Bạn cần cẩn thận để không bị mất thông tin! Hãy cân nhắc thực hiện hành động này trên một cột mới (không ghi đè lên cột hiện tại).
Hàm fct_recode() có cú pháp khác với hàm recode(). Hàm recode() sử dụng câu lệnh OLD = NEW, trong khi hàm fct_recode() sửu dụng câu lệnh NEW = OLD.
Những thứ bậc sẵn có của biến delay_cat như sau:
levels(linelist$delay_cat)[1] "<2 days" "2-5 days" ">5 days" Để tạo một thứ bậc mới, bạn sử dụng câu lệnh sau fct_recode(column, "new" = "old", "new" = "old", "new" = "old") và in ra như sau:
linelist %>%
mutate(delay_cat = fct_recode(
delay_cat,
"Less than 2 days" = "<2 days",
"2 to 5 days" = "2-5 days",
"More than 5 days" = ">5 days")) %>%
tabyl(delay_cat) delay_cat n percent valid_percent
Less than 2 days 2990 0.50781250 0.5308949
2 to 5 days 2040 0.34646739 0.3622159
More than 5 days 602 0.10224185 0.1068892
<NA> 256 0.04347826 NAỞ đây các thứ bậc cũ được kết hợp theo cách thủ công với fct_recode(). Lưu ý rằng không có lỗi phát sinh khi tạo thứ bậc mới “Less tham 5 days”.
linelist %>%
mutate(delay_cat = fct_recode(
delay_cat,
"Less than 5 days" = "<2 days",
"Less than 5 days" = "2-5 days",
"More than 5 days" = ">5 days")) %>%
tabyl(delay_cat) delay_cat n percent valid_percent
Less than 5 days 5030 0.85427989 0.8931108
More than 5 days 602 0.10224185 0.1068892
<NA> 256 0.04347826 NARút gọn thành nhóm “Khác”
Bạn có thể sử dụng hàm fct_other() để gán các thứ bậc của một cột dạng factor thành một thứ bậc mới “Other”. Dưới đây, tất cả các thứ bậc trong biến hospital, ngoại trừ “Port Hospital” và “Central Hospital”, được gộp chung thành “Other”. Bạn có thể cung cấp một vectơ để giữ keep =, hoặc loại bỏ drop =. Bạn có thể thay đổi cách hiển thị của thứ bậc “Other” bằng hàm other_level =.
linelist %>%
mutate(hospital = fct_other( # adjust levels
hospital,
keep = c("Port Hospital", "Central Hospital"), # keep these separate
other_level = "Other Hospital")) %>% # All others as "Other Hospital"
tabyl(hospital) # print table hospital n percent
Central Hospital 454 0.07710598
Port Hospital 1762 0.29925272
Other Hospital 3672 0.62364130Rút gọn theo tần suất
Bạn có thể tự động kết hợp các thứ bậc trong biến factor có tần suất ít nhất bằng cách sử dụng hàm fct_lump().
Để “gộp” nhiều giá trị tần suất thấp lại thành một nhóm khác “Other”, hãy thực hiện một trong các thao tác sau:
- Đặt
n =là số nhóm bạn muốn giữ. n thứ bậc có tần suất nhiều nhất sẽ được giữ nguyên và tất cả các cấp độ khác sẽ kết hợp thành nhóm “Other”. - Đặt
prop =là ngưỡng tỷ lệ cho các thứ bậc bạn muốn giữ ở trên. Tất cả các giá trị khác sẽ kết hợp thành nhóm “Other”.
Bạn có thể thay đổi cách hiển thị của thứ bậc “Other” bằng hàm other_level =. Dưới đây, tất cả các giá trị ngoài hai bệnh viện phổ biến nhất đều được kết hợp thành nhóm “Other Hospital”.
linelist %>%
mutate(hospital = fct_lump( # adjust levels
hospital,
n = 2, # keep top 2 levels
other_level = "Other Hospital")) %>% # all others as "Other Hospital"
tabyl(hospital) # print table hospital n percent
Missing 1469 0.2494905
Port Hospital 1762 0.2992527
Other Hospital 2657 0.451256811.7 Hiển thị tất cả thứ bậc
Một lợi ích của việc sử dụng factors là chuẩn hóa sự xuất hiện của các chú thích trong biểu đồ và bảng, bất kể giá trị nào thực sự có trong tập dữ liệu.
Nếu bạn đang chuẩn bị nhiều bảng biểu (ví dụ: cho nhiều khu vực pháp lý), bạn sẽ muốn các chú giải và bảng xuất hiện giống hệt nhau ngay cả với các mức độ hoàn thành dữ liệu hoặc thành phần dữ liệu khác nhau.
Trong biểu đồ
Trong hàm vẽ biểu đồ ggplot (), chỉ cần thêm đối số drop = FALSE trong hàm liên quan scale_xxxx(). Tất cả các thứ bậc trong biến factor sẽ được hiển thị, bất kể chúng có trong dữ liệu hay không. Nếu các thứ bậc trong biến factor của bạn được hiển thị bằng cách sử dụng fill =, thì trong scale_fill_discrete (), bạn cần thêm drop = FALSE, như được trình bày bên dưới. Nếu các thứ bậc trong biến factor của bạn được hiển thị với x = (đến trục x) color = hoặc size =, bạn sẽ cung cấp chúng tới scale_color_discrete() hoặc scale_size_discrete().
Ví dụ này là một biểu đồ cột chồng của nhóm tuổi, theo bệnh viện. Việc thêm scale_fill_discrete (drop = FALSE) đảm bảo rằng tất cả các nhóm tuổi đều xuất hiện trong chú giải, ngay cả khi không có trong dữ liệu.
ggplot(data = linelist)+
geom_bar(mapping = aes(x = hospital, fill = age_cat)) +
scale_fill_discrete(drop = FALSE)+ # show all age groups in the legend, even those not present
labs(
title = "All age groups will appear in legend, even if not present in data")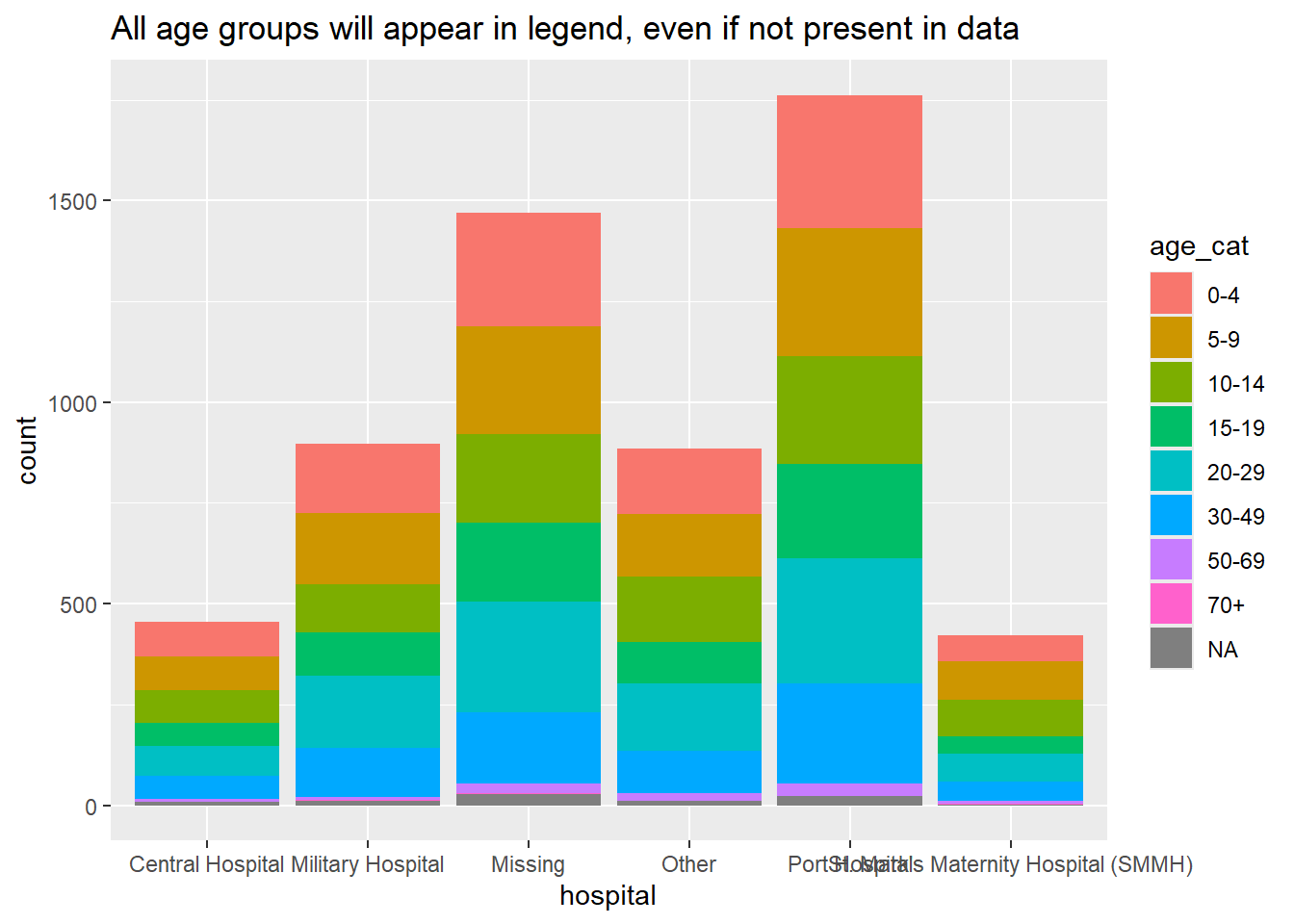
Trong bảng
Cả hàm table() trong base R và hàm tabyl() trong package janitor đều sẽ hiển thị tất cả các thứ bậc trong factor (ngay cả các thứ bậc không sử dụng).
Nếu bạn sử dụng hàm count() hoặc summarise() từ package dplyr để tạo bảng, hãy thêm đối số .drop = FALSE để hiển thị số lượng cho tất cả các thứ bậc trong factor ngay cả các thứ bậc không sử dụng.
Đọc thêm tại chương Bảng mô tả,hoặc tại các link sau scale_discrete documentation, hoặc count() documentation. Bạn có thể tìm các ví dụ khác tại chương Truy vết tiếp xúc.
11.8 Tuần dịch tễ
Vui lòng xem phần thảo luận đầy đủ về cách tạo các tuần dịch tễ trong chương Nhóm dữ liệu.
Vui lòng xem chương Làm việc với ngày tháng để biết các mẹo về cách tạo và định dạng các tuần dịch tễ học.
Tuần dịch tễ trong biểu đồ
Nếu mục tiêu của bạn là tạo các tuần dịch tễ học để hiển thị trong một biểu đồ, bạn có thể thực hiện việc này đơn giản với hàm floor_date() trong package lubridate, như được giải thích trong chương Nhóm dữ liệu. Các giá trị trả về sẽ thuộc loại Ngày tháng với định dạng YYYY-MM-DD. Nếu bạn sử dụng cột này trong một biểu đồ, ngày tháng sẽ tự nhiên được sắp xếp chính xác và bạn không cần phải lo lắng về thứ bậc hoặc chuyển đổi sang dạng factor. Xem biểu đồ histogram trong hàm ggplot() về các ngày khởi phát bên dưới.
Trong cách tiếp cận này, bạn có thể điều chỉnh việc hiển thị của ngày tháng trên trục với scale_x_date(). Xem thêm tại trang Đường cong dịch bệnh để biết thêm thông tin. Bạn có thể chỉ định định dạng hiển thị date_labels = cho đối số scale_x_date(). Sử dụng “% Y” để đại diện cho năm có 4 chữ số và “% W” hoặc “% U” để đại diện cho số tuần (các tuần thứ Hai hoặc Chủ Nhật tương ứng).
linelist %>%
mutate(epiweek_date = floor_date(date_onset, "week")) %>% # create week column
ggplot()+ # begin ggplot
geom_histogram(mapping = aes(x = epiweek_date))+ # histogram of date of onset
scale_x_date(date_labels = "%Y-W%W") # adjust disply of dates to be YYYY-WWw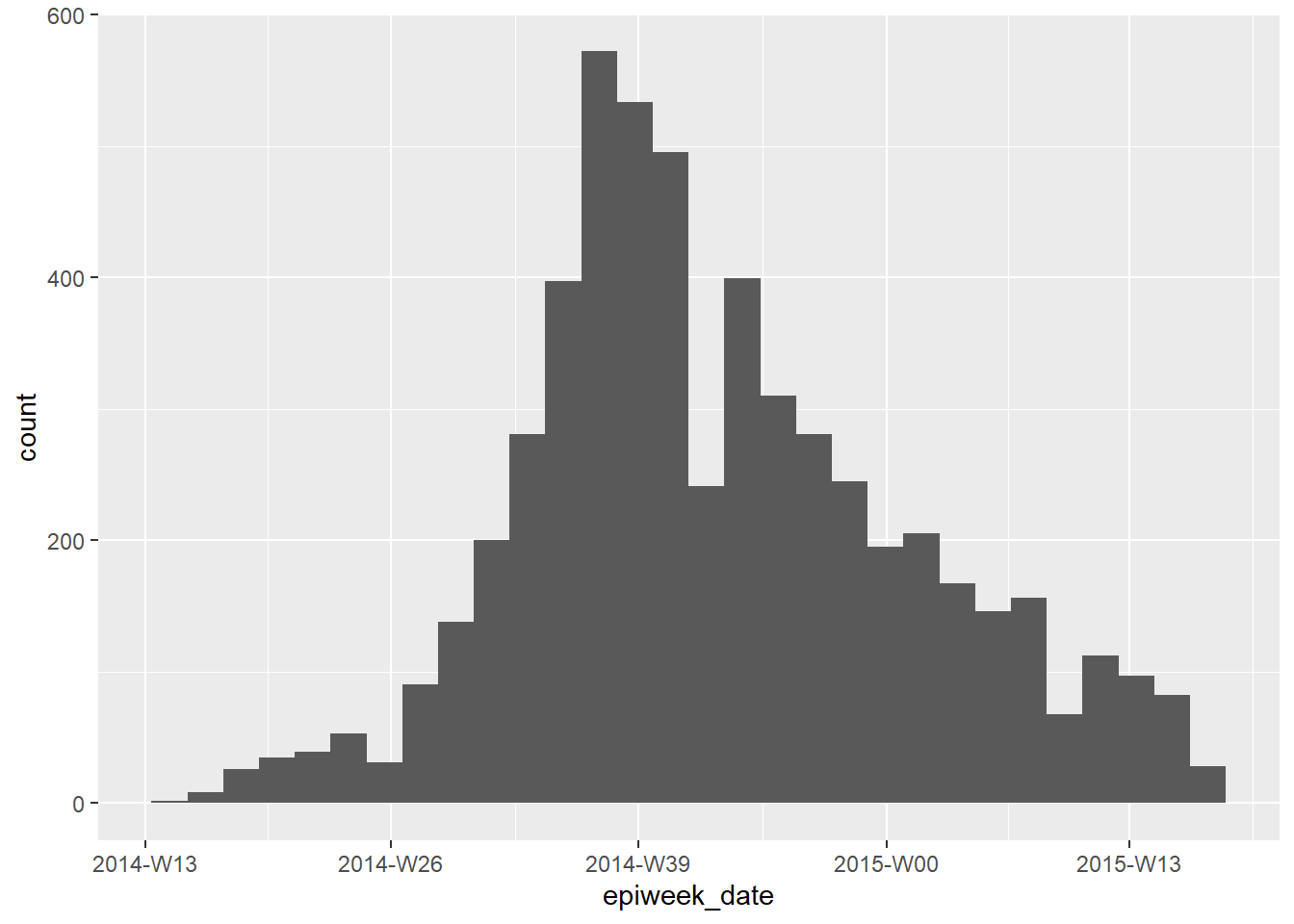
Tuần dịch tễ trong dữ liệu
Tuy nhiên, nếu mục đích của bạn với biến factor không phải để lập biểu đồ, bạn có thể tiếp cận theo một trong hai cách:
- Để kiểm soát tốt việc hiển thị, hãy chuyển đổi cột lubridate tuần dịch tễ (YYYY-MM-DD) sang định dạng hiển thị mong muốn (YYYY-WWw) trong chính data frame, rồi chuyển đổi nó thành dạng factor.
Đầu tiên, sử dụng hàm format() từ base R để chuyển đổi hiển thị ngày từ hiển thị YYYY-MM-DD sang hiển thị YYYY-Www (xem thêm tại chương Làm việc với ngày tháng). Trong quá trình này, kiểu của biến số sẽ được chuyển đổi thành ký tự. Sau đó, chuyển đổi từ kiểu ký tự sang kiểu Factor với hàm factor().
linelist <- linelist %>%
mutate(epiweek_date = floor_date(date_onset, "week"), # create epiweeks (YYYY-MM-DD)
epiweek_formatted = format(epiweek_date, "%Y-W%W"), # Convert to display (YYYY-WWw)
epiweek_formatted = factor(epiweek_formatted)) # Convert to factor
# Display levels
levels(linelist$epiweek_formatted) [1] "2014-W13" "2014-W14" "2014-W15" "2014-W16" "2014-W17" "2014-W18"
[7] "2014-W19" "2014-W20" "2014-W21" "2014-W22" "2014-W23" "2014-W24"
[13] "2014-W25" "2014-W26" "2014-W27" "2014-W28" "2014-W29" "2014-W30"
[19] "2014-W31" "2014-W32" "2014-W33" "2014-W34" "2014-W35" "2014-W36"
[25] "2014-W37" "2014-W38" "2014-W39" "2014-W40" "2014-W41" "2014-W42"
[31] "2014-W43" "2014-W44" "2014-W45" "2014-W46" "2014-W47" "2014-W48"
[37] "2014-W49" "2014-W50" "2014-W51" "2015-W00" "2015-W01" "2015-W02"
[43] "2015-W03" "2015-W04" "2015-W05" "2015-W06" "2015-W07" "2015-W08"
[49] "2015-W09" "2015-W10" "2015-W11" "2015-W12" "2015-W13" "2015-W14"
[55] "2015-W15" "2015-W16"Nguy hiểm: Nếu bạn đặt các tuần trước các năm (“Www-YYYY”) (“%W-%Y”), thứ tự các thứ bậc sẽ sắp xếp mặc định theo bảng chữ cái và điều này là không chính xác (ví dụ: 01-2015 sẽ là trước 35-2014). Bạn có thể cần phải điều chỉnh thứ tự theo cách thủ công, đây sẽ là một quá trình dài khó khăn .
-
Để hiển thị nhanh theo mặc định, sử dụng hàm
date2week()trong package aweek. Bạn có thể đặt ngày theo hàmweek_start =, và nếu bạn đặt đối sốfactor = TRUEthì cột đầu ra là một factor có thứ tự. Factor sẽ bao gồm các thứ bậc cho tất cả các tuần có thể có trong khoảng thời gian - ngay cả khi không có trường hợp nào xuất hiện trong tuần đó.
df <- linelist %>%
mutate(epiweek = date2week(date_onset, week_start = "Monday", factor = TRUE))
levels(df$epiweek)Xem chương Làm việc với ngày tháng để biết thêm thông tin về package aweek. Nó cũng cung cấp thông tin về hàm đảo ngược week2date().
11.9 Nguồn tham khảo
R trong Khoa học dữ liệu, chương factors
aweek package vignette